基于DSP的語音識別計算器設計

TLV320AIC23是Tl公司的一款低成本、低功耗的音頻編解碼器(CODEC),在本系統中負責采集語音信號。它與本系統相關的性能參數有:支持8~96 kHz可調采樣率;可調1~5dB的完整緩存放大系統等。圖4是TLV320AIC23的電路圖。本文引用地址:http://www.104case.com/article/166656.htm

AM29LV800B存儲器又稱閃存(Flash),它具有在線電擦寫、低功耗、大容量等特點,其存儲容量為8Mbit。上電后,DSP從外部Flash加載并執行程序代碼,使系統能夠脫機運行。在本系統中,它主要用來存儲程序代碼、語音模型、以及壓縮后的語音數據。
HY57V641620同步動態存儲器(SDRAM),容量為4 M×16 bit。作為RAM的擴展,它大大增強了DSP的存儲與運算能力。在系統初始化的時候,用來裝載放在Flash中的聲學模型。這樣在語音識別的過程中可以通過片外的SDRAM來訪問聲學模型,比直接訪問Flash來獲取聲學模型數據要快。LCD顯示器用來實時顯示經過語音識別后的數字、運算符號,并在得到需要顯示最終結果的提示后顯示答案。
2 系統軟件設計
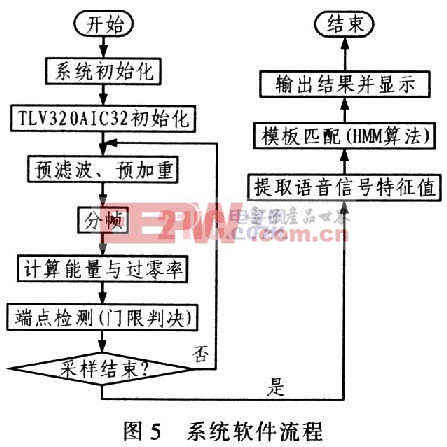
2.1 系統軟件流程
圖5為系統的軟件流程。整個系統開始運行后,初始化DSP及TLV320AIC23,以使各個寄存器的初值符合要求。在系統通過TLV320AIC23采集語音信號后,首先要進行預濾波和預加重;接著將語音信號進行分幀;然后計算每幀信號的短時能量與短時平均過零率,為接下來的門限判決提供依據;利用門限判決進行端點檢測后,提取每幀的Mel倒譜參數(MFCC),作為該幀信號的特征值;最后,用處理后的語音信號的特征值與模板進行匹配,這一部分是系統的重點。以相似度最大的模板鎖對應的語音信號為識別結果。根據識別的結果在顯示器上顯示數字和運算符號,由運算規則得出結果并顯示。
2.2 前處理
前處理是對語音信號采樣、A/D轉換、預濾波和預加重、分幀等。以8 kHz和16位的采樣頻率采集的語音模擬信號。本系統使用帶通濾波器來濾波,上截頻率為3.4 kHz。下截頻率為60 Hz。由于語音信號具有極強的相關性,因此,分幀時要考慮幀重復的問題。本文將語音信號以256個采樣點為一幀,兩頓之間的重復點數為80,通過一個一階的濾波器H(z)=1-a/z對采集的信號進行處理。
端點檢測就是從說話人的語音命令中,檢測出孤立詞的語音開始和結束的始點。端點檢測是語音識別過程的一個重要環節,只有將孤立詞從說話人的背景噪聲中分割出來,才能夠進一步進行語音識別工作。本文采用短時能量和過零率檢測端點。語音信號的短時能量分析給出了反應其幅度變化的一個合適描述方法。
短時過零率,即指每幀內信號通過零值的次數,能夠在一定程度上反映信號的頻譜特性。一幀語音信號內短時平均過零率定義為:

用短時能量參數檢測結束點,信號{x(n)}的短時能量定義為:

式中,{x(n)}為輸入信號序列。
在正式端點檢測開始后,短時能量與短時過零率作為門限來判決說話人命令字的開始與結束;連續5幀語音信號超過門限值視為說話人命令字的開始,連續8幀語音信號低于門限值視為說話人命令字的結束。
2.3 特征值提取
提取每幀的Mel倒譜參數(MFCC)為該幀信號的特征值。由倒譜特征是用于說話人個性特征和說話人識別的最有效的特征之一,它是基于人耳模型而提出的。其提取過程如下:
1)原始語音信號S(n)經過預加重、加窗等處理,得到每個語音幀的時域信號x(n)。然后經過離散傅里葉變換(DFT)后得到離散頻譜X(k)。

式中,N表示傅里葉變換的點數。










評論