智能機(jī)器人語音識別技術(shù)

摘要:給出了一種由說話者說出控制命令,機(jī)器人進(jìn)行識別理解,并執(zhí)行相應(yīng)動作的實(shí)現(xiàn)技術(shù)。在此,提出了一種高準(zhǔn)確率端點(diǎn)檢測算法、高精度定點(diǎn)DSP動態(tài)指數(shù)定標(biāo)算法,以解決定點(diǎn)DSP實(shí)現(xiàn)連續(xù)隱馬爾科夫模型CHMM識別算法時所涉及的大量浮點(diǎn)小數(shù)運(yùn)算問題,提高了定點(diǎn)DSP實(shí)現(xiàn)的實(shí)時性、精度,及其識別率。
關(guān)鍵詞:智能機(jī)器人;語音識別;隱馬爾可夫模型;DSP
0 引言
語音控制的基礎(chǔ)就是語音識別技術(shù),可以是特定人或者非特定人的。非特定人的應(yīng)用更為廣泛,對于用戶而言不用訓(xùn)練,因此也更加方便。語音識別可以分為孤立詞識別,連接詞識別,以及大詞匯量的連續(xù)詞識別。對于智能機(jī)器人這類嵌入式應(yīng)用而言,語音可以提供直接可靠的交互方式,語音識別技術(shù)的應(yīng)用價值也就不言而喻。
1 語音識別概述
語音識別技術(shù)最早可以追溯到20世紀(jì)50年代,是試圖使機(jī)器能“聽懂”人類語音的技術(shù)。按照目前主流的研究方法,連續(xù)語音識別和孤立詞語音識別采用的聲學(xué)模型一般不同。孤立詞語音識別一般采用DTW動態(tài)時間規(guī)整算法。連續(xù)語音識別一般采用HMM模型或者HMM與人工神經(jīng)網(wǎng)絡(luò)ANN相結(jié)合。
語音的能量來源于正常呼氣時肺部呼出的穩(wěn)定氣流,喉部的聲帶既是閥門,又是振動部件。語音信號可以看作是一個時間序列,可以由隱馬爾可夫模型(HMM)進(jìn)行表征。語音信號經(jīng)過數(shù)字化及濾噪處理之后,進(jìn)行端點(diǎn)檢測得到語音段。對語音段數(shù)據(jù)進(jìn)行特征提取,語音信號就被轉(zhuǎn)換成為了一個向量序列,作為觀察值。在訓(xùn)練過程中,觀察值用于估計(jì)HMM的參數(shù)。這些參數(shù)包括觀察值的概率密度函數(shù),及其對應(yīng)的狀態(tài),狀態(tài)轉(zhuǎn)移概率等。當(dāng)參數(shù)估計(jì)完成后,估計(jì)出的參數(shù)即用于識別。此時經(jīng)過特征提取后的觀察值作為測試數(shù)據(jù)進(jìn)行識別,由此進(jìn)行識別準(zhǔn)確率的結(jié)果統(tǒng)計(jì)。訓(xùn)練及識別的結(jié)構(gòu)框圖如圖1所示。
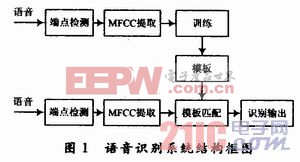
1. 1 端點(diǎn)檢測
找到語音信號的起止點(diǎn),從而減小語音信號處理過程中的計(jì)算量,是語音識別過程中一個基本而且重要的問題。端點(diǎn)作為語音分割的重要特征,其準(zhǔn)確性在很大程度上影響系統(tǒng)識別的性能。
能零積定義:一幀時間范圍內(nèi)的信號能量與該段時間內(nèi)信號過零率的乘積。
能零積門限檢測算法可以在不丟失語音信息的情況下,對語音進(jìn)行準(zhǔn)確的端點(diǎn)檢測,經(jīng)過450個孤立詞(數(shù)字“0~9”)測試準(zhǔn)確率為98%以上,經(jīng)該方法進(jìn)行語音分割后的語音,在進(jìn)入識別模塊時識別正確率達(dá)95%。
當(dāng)話者帶有呼吸噪聲,或周圍環(huán)境出現(xiàn)持續(xù)時間較短能量較高的噪聲,或者持續(xù)時間長而能量較弱的噪聲時,能零積門限檢測算法就不能對這些噪聲進(jìn)行濾除,進(jìn)而被判作語音進(jìn)入識別模塊,導(dǎo)致誤識。圖2(a)所示為室內(nèi)環(huán)境,正常情況下采集到的帶有呼氣噪聲的數(shù)字“0~9”的語音信號,利用能零積門限檢測算法得到的效果示意圖。最前面一段信號為呼氣噪聲,之后為數(shù)字“0~9”的語音。
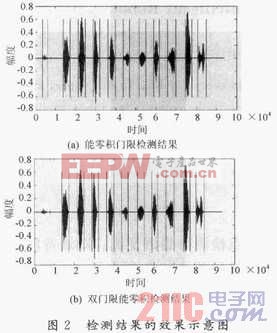
從圖2(a)直觀的顯示出能零積算法在對付能量較弱,但持續(xù)時間長的噪音無能為力。由此引出了雙門限能零積檢測算法。
所謂的雙門限能零積算法指的是進(jìn)行兩次門限判斷。第一門限采用能零積,第二門限為單詞能零積平均值。也即在前面介紹的能零積檢測算法的基礎(chǔ)上再進(jìn)行一次能零積平均值的判決。其中,第二門限的設(shè)定依據(jù)取決于所有實(shí)驗(yàn)樣本中呼氣噪聲的平均能零積及最小的語音單詞能零積之間的一個常數(shù)。如圖2(b)所示,即為圖2(a)中所示的語音文件經(jīng)過雙門限能零積檢測算法得到的檢測結(jié)果。可以明顯看到,最前一段信號,即呼氣噪聲已經(jīng)被視為噪音濾除。




評論