MPEG-4編碼器在BF561上的優化

3 編碼器優化方案
3.1 基于Cache和DMA的優化
Blackfin系列DSP多級存儲結構,其代碼從內部L1指令存儲器運行、中間數據及常用參數從內部L1數據存儲器讀取或存放時,才能實現最佳性能。但是MPEG-4算法大量的算法導致代碼不可能放入L1指令存儲器中,大量的中間數據和參數也不可能僅存放在L1數據存儲器中,所以要考慮如何更好地利用處理器上的L1存儲器才能讓系統的性能達到最佳。指令Cache,數據DMA,這是目前最流行的系統模型,多數的嵌入式媒體處理器都是基于這樣的想法而設計的。
使用高速緩存機制允許編程者訪問大的、低成本的外部存儲器。它的工作方式是:在需要的時候自動將代碼讀入L1指令存儲器。這使編程者不必繁瑣地將代碼從內部存儲器移入移出。指令高速緩存有助于以更為有效的方式從外部存儲器預取指令。
相比于指令管理方面使用指令Cache,在數據管理上使用DMA顯得是自然而然的。但是在優化過程中還是注意了以下幾個問題:
(1)由于BF561的外部總線是32位寬的,所以用32位DMA能最大程度地提高數據存取的性能。
(2)基于寄存器的DMA和基于描述符的DMA兩種DMA工作方式的選取。基于寄存器的DMA中,處理器直接對DMA控制寄存器編程來初始化一個傳送。因為寄存器不必從內存中裝載,并且內核不必保存描述符,因此,基于寄存器的DMA提供了最好的DMA控制器性能。相反在基于描述符的DMA操作中,可以對一個DMA通道進行編程,以便在當前傳送隊列完成后,自動設置和重啟其他的DMA傳送過程。在管理一個系統的DMA過程時,基于描述符的模型可以提供最大的靈活性。基于上面的考慮,在視頻采集模塊中我們選了基于描述符的DMA控制方式,而在其他模塊中選取基于寄存器的DMA方式。
(3)當數據在內部存儲器移動時,盡量不使用標準C語言中的memepy()函數,而使用MemDMA的方式,這樣可以減少CPU等待時間。
3.2 存儲器管理策略優化
對于通常的嵌入式媒體處理器,片上存儲器都不夠存儲一個完整的視頻幀,因此系統必須依賴L3外部RAM來支持對大緩沖區進行相對較快的訪問。因此對片外存儲器的訪問必須精心設計,以保證較優的數據吞吐。以下是筆者在優化過程中總結的一些關鍵步驟:
(1)分組類似傳送來減小存儲器總線出送方向切換的次數。以相同的方向訪問外存是是最有效率的(如連續的讀或者寫)。例如,當訪問片外SDRAM時,16個讀16個寫總比單獨的16個讀/寫要快,這是由于先寫再讀而導致的延遲。對外存的隨機訪問會產生高概率的總線中轉。因此在給定的方向上充分利用控制傳輸數量的能力是重要的。
對于MemDMA流,當期望共享可用的DMA總線帶寬時,可編程的DMA控制器以輪流選擇每個數據流的方式進行固定數量的傳送。在每條DMA總線上,這個“方向控制”工具在DMA資源的優化使用方面是一個重要的考慮。通過分組同方向地傳送在一起,其提供了一種方法來管理DMA總線傳送方向的頻繁變動。當使用方向控制特性時,DMA控制器優先級保證在DMA或存儲器總線上,與前一次傳送據具有相同讀/寫方向的數據傳輸,直到方向控制計數器溢出,或停止傳送,或傳送過程中自己改變方向。當方向計數器歸零時,DMA控制器改變其優先選擇方向為相反的數據流動。
(2)保持SDRAM的行打開及實現多次數據傳送。每次訪問SDRAM都會花費幾個SCLK(系統時鐘周期),特別是如果需要的SDRAM的行還沒有被激活時。一旦一行是激活的,就能從一整行中讀取數據而不必每次訪問該行的時候再打開。或者可以這樣理解:每個SCLK周期訪問存儲器的任何位置都是可能的,只要這些位置在SDRAM的同一行中。關閉一行需要多個SDRAM時鐘周期,因此,連續的行關閉能嚴格限制SDRAM的吞吐量。
一個SDRAM的頁錯失可花費20~50個CCLK(核時鐘周期)。Blackfin系列DSP可以最多同時打開四個SDRAM行,從而減少設置時間。應用程序應當通過適當放置數據緩沖區和管理訪問來利用打開的SDRAM塊,原則就是把可能同一時間訪問的緩沖區分配到不同的SDRAM塊中。
3.3 基于雙核結構的優化
一片BF561內包含了兩個完全相同的Blackfin內核,這使其擁有比同系列芯片更為強勁的運算能力。因此想要充分發揮其能力就必須更具其結構特性為編碼器設定合適的整體構架。通常的方式有兩種,一種是非對稱的程序設計模式,另外一種為對稱的程序設計模式。顧名思義,非對稱模式就是兩個內核完成不同的處理任務,這種模式下,兩個內核好像是兩個單獨的處理器,它們之間不共享代碼。不共享或者只共享少量的數據。而對稱的程序設計模式比較適合于處理器任務較為單一,但運算量比較大的情況,更能發揮雙核在運算能力方面的優勢。
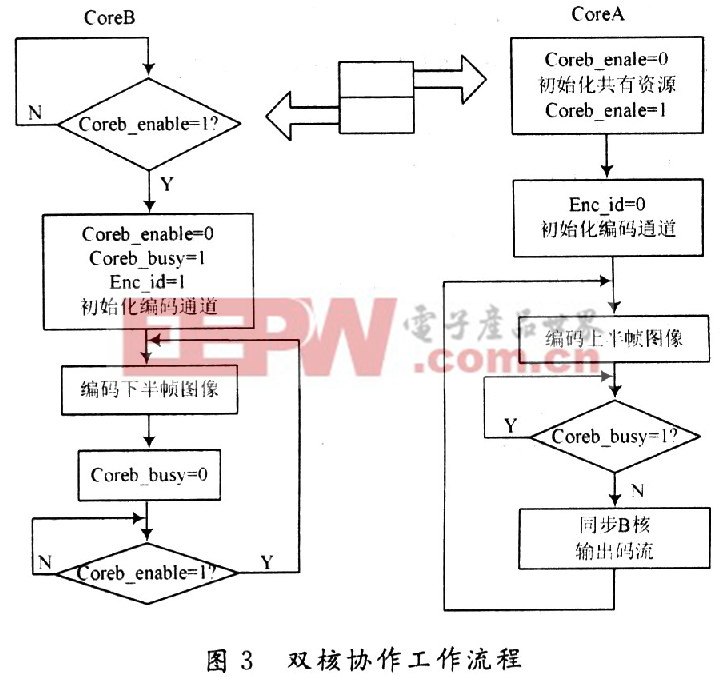
基于上面的分析,選擇了對稱的程序設計模式,而且是基于運算量考慮的對稱模型,即兩個核各負責半幀圖像的壓縮,另外A核還負責系統初始化以及輸入/輸出中斷的響應,B核還負責時間字符的疊加以及時間計算等,這樣最大程度上平衡了兩個核的工作量。此外,在L2存儲器中定義了兩個核都需要的變量,以及控制雙核同步的信號量等。雙核協作工作的過程以及同步方式如圖3所示。本文引用地址:http://www.104case.com/article/151817.htm






評論