基于ARM7控制器――LPC2214的中英文翻譯器

2 系統軟件算法
由于數據量非常大,所以在軟件設計方面進行了優化,主要包括中英文數據存儲方式、環形接收和發送緩沖區算法、查找和翻譯算法等3部分。
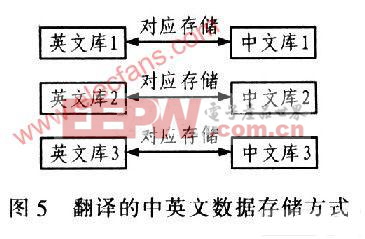
2.1 中英文數據存儲方式
首先,英文轉中文翻譯器涉及到的問題是漢字在計算機內的存儲問題,漢字在計算機內的存儲是以機內碼形式存儲的,1個漢字占用2個字節,因此在LPC2214中可以直接定義與接收到的英文字符串相對應的漢字常量字符串作為翻譯后的數據。其次,為了查找方便,對接收到的英文字符串分了3類,相應地漢字字符串也對應分為3類,如圖5所示。其中,庫l為包含“:”的英文行,對應的中文翻譯只是翻譯“:”前的英文,而“:”后的英文字符和數字不必翻譯直接輸出;庫2為不包含“:”的英文行,直接將對應的中文庫2輸出即可;庫3為含有多義語義的英文行庫,在中文庫3中再細分后輸出。在具體編程時利用了二維數組結構存儲中英文字庫。
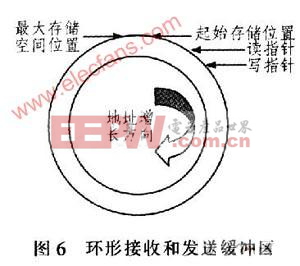
2.2 環形接收和發送緩沖區算法
設備傳輸的數據量很大,共有幾百組數據,而每組數據又包含幾十行英文字符和數字,如果采用全部接收完設備傳輸的數據后再查找對應的中文,找到后再依次控制打印機打印輸出,則不但需要相當大的緩沖區用于存儲,而且從接收數據開始到打印機輸出打印要延誤很長時間。因此,這里采用前后臺程序方式即邊接收、邊查找、邊打印,該方式既節省時間又節省存儲空間。在系統中開一段存儲空間作為接收緩沖區,如圖6所示。設置2個指針:寫指針和讀指針,初始化時令這2個指針分別指向存儲區的起始位置。接收設備數據采用UART0串口接收中斷處理方式,以便不丟失設備發送的任何一個字符。在UART0每接收一行英文數據后,寫指針加1,當寫指針達到最大存儲空間位置時,令寫指針復位為起始存儲位置,這樣就形成一個環形緩沖區。當接收緩沖區非空,即有需要翻譯的英文行數據時,讀指針指向當前需要翻譯的英文行數據,和寫指針類似,每翻譯一行數據后通過UARTl控制打印機輸出打印且讀指針加1,當讀指針到達最大存儲空間位置時,令讀指針復位為起始存儲位置。實驗表明,設置成很少的幾行接收和發送緩沖區都可以正常接收數據和打印數據。








評論