基于TMS320C6416的語音凈化系統

系統上電后,存儲在FLASH ROM中的程序將裝入TMS320C6416的片內RAM中,程序對寄存器、中斷向量表和編碼進行初始化并對片內McBSP進行配置,完成這些初始化的任務后系統采集并處理語音信號.系統首先對目前狀態進行辨識.開機后的狀態分為非識別狀態和識別狀態,非識別狀態 下系統將采集純正語音信號,提取出語音特征送入存儲器中作為模板;識別狀態下首先參數考純凈語音的特征對采集的雙路混合信號進行分離,獲得純凈的待別語音,最后送入識別系統完成語音識別.整個流程見圖4.
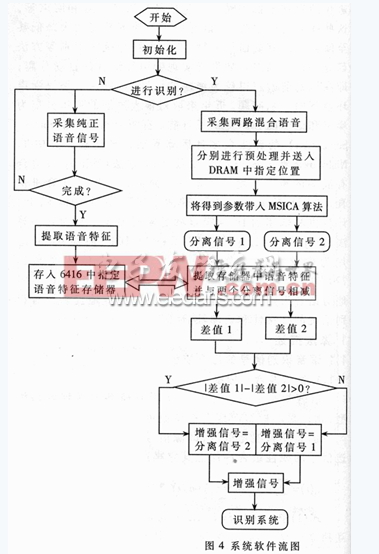
具體分離步驟在初始化之后,主函數程序進入一個等待循環,在一個新的采樣輸入被獲取之后與中斷服務程序(ISR)一起工作并調用分離程序.第一步,信號首先通過TI的DFT程序變換到頻域.系統使用最前面的幾個塊(例如取5塊)來估計輸入信號x1和x2每個頻率分量的功率矩陣.流程圖(見圖5)中的變量P表示正在處理的塊數.對于接下來的每一塊(P≥5),系統通過指數平均來更新輸入信號的功率矩陣,以計算出梯度.然后計算步長u12、u21和差分脈沖響應濾波器ΔH12、ΔH21的更新系數.最后確定更新系統和DRIR濾波器系數,在頻域對輸入信號進行初步分離.第二步,白化程序對FDICA輸出信號進行白化處理,以去除信號的相關性.第三步,首先通過最小化非負代價函數計算分離濾波器矩陣和分離濾波器系數,然后帶入白化后的信號求得TDICA輸出信號.
2.3 代碼優化
為了進行實時的混合語音分離并識別,分離算法必須在盡可能短的時間(如1~2s)內完成.在本系統中,通過CCS對C源代碼進行編譯,并對分離算法的一些關鍵模塊從內聯函數替換、數據讀寫、循環體優化、函數拆并、C級優化等方面進行優化設計,以達到充分利用CPU、存儲器等資源,提高算法運行速度,滿足實時性要求.
(1)內聯函數優化
通過內聯函數替換提高代碼性能.內聯函數直接與匯編指令相對應,通過使用它們,C編譯器能達到更好的編譯效果,并充分利用系統資源.C6416提供豐富的內聯函數,涵蓋了各種數據類型的乘、加、移位等操作.實驗結果表明,內聯函數替換是提高代碼性能最簡單、直接有效的方法.
(2)數據讀寫優化
充分利用C6416的雙字存儲指信和packing/unpacking方式提高代碼的運行速度.
(3)循環體優化
通過軟件流水工具(Software Pipeline)適當安排循環指令,使多次迭代并行執行,以達到優化代碼的目的.
(4)函數拆并優化
將某些大函數拆開成多個小函數或相反,以提高程序的運行速度.對FDICA和TDICA等大程序中某些常用的分支,可將其拆分以減少判斷、跳轉操作.對于某些簡單的小函數,將其合并成大函數有助于減少程序調用開銷.
(5)C級優化
在定點DSP上進行浮點運算會影響C源代碼的性能.因此,第一個優化任務就是將源碼中運算比較密集的部分(如分離濾波器矩陣和分離濾波器系數的計算)轉換成定點的算法.此外,影響系統性能的一個重要原因是沒有有效利用DSP的并行計算能力,TMS320C6416為最優化這些并行操作的打包數據處理提供了特殊的指令.系統另一個瓶頸是對外部存儲器的訪問.對混合語音的分離需要處理大量的數據,存儲和訪問可能是DSP系統的最大瓶頸.通過使用緩存可以緩解瓶頸,優化在外部和內部存儲中的數據定位可以提高系統的性能.最后,使用C編譯器的最優化選項編譯代碼.
上述的優化并非已經完全,在后續的研究中代碼可以進一步優化,如可改進以下幾處:首先,使用DMA以提高存儲器訪問的性能并減少存儲器消耗;其次,為了避免浮點溢出可以將代碼全部轉換為定點,對代碼中的關鍵循環進行更好的組織以實現軟件流水線;最后,為了最大程序提高性能可以使用線性匯編語言并對部分代碼進行匯編層的優化.
2.4 實驗結果
采用兩組混合語音來測試,即單獨錄制兩個純凈的信號源,圖1所示模型用MATLAB混合(忽略噪聲),通過凈化系統得到兩級分離信號并與原始語音進行比對.x1(t)和x2(t)即為兩個麥克風的輸入信號.使用以下兩組聲音信號作為測試信號,第一組為語音和音樂信號,第二組為兩個語音信號,都是16kHz采樣16bit單聲道文件,長度均為7s.圖6與圖7分別為上述兩組混合語音的分離結果,從中可以看出分離效果非常令人滿意,達到了帶噪語音的凈化效果.
結語
在實驗室環境引入語音凈化系統后,語音識別的速度雖然略有下降,但是識別語音的信噪比有顯著提高,在有不同信噪比的音樂和混響噪聲的背景中,識別率平均提高30%以上.






評論