通過電源管理和工作負(fù)載整合,大幅提升電信業(yè)務(wù)處理性能

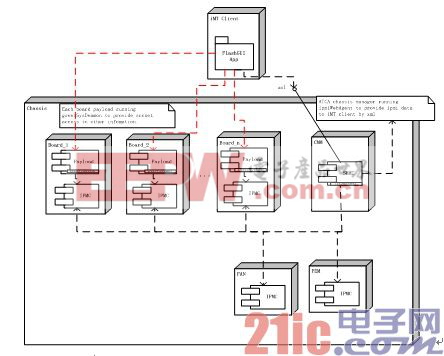 本文引用地址:http://www.104case.com/article/148005.htm
本文引用地址:http://www.104case.com/article/148005.htm客戶端代表電源管理系統(tǒng)搜集與電源有關(guān)的數(shù)據(jù)。系統(tǒng)守護(hù)進(jìn)程是加載在每一個(gè)刀片上的應(yīng)用,扮演者電源管理模塊的角色。它提供了CPU、內(nèi)存、硬盤、網(wǎng)絡(luò)和虛擬化的工作方法以及功耗限定等功能,在滿足性能需求的前提下盡量降低功耗。實(shí)際的管理端可以運(yùn)行在臺(tái)式機(jī)或者筆記本上,通過整合并顯示輸出機(jī)箱、板卡和傳感器(如溫度)等實(shí)際功耗的信息。
圖3:功耗限定功能實(shí)例
主動(dòng)電源管理
通過策略的配置,將ATCA刀片上CPU的工作模式切換至節(jié)能或主動(dòng)電源管理模式后,每個(gè)刀片的功耗相比持續(xù)運(yùn)行在性能模式下減少15%(參見圖4和圖5)。每片板卡在加載服務(wù)的情況下可以節(jié)約0.4KW的功耗(參見圖5)。如果一個(gè)14槽的ATCA機(jī)框中使用了10個(gè)刀片,那每天節(jié)約的功耗大約4KW。
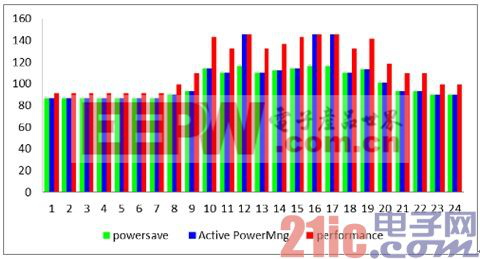

圖45:CPU在三種獨(dú)立模式下的功耗比較
動(dòng)態(tài)遷移
減少功耗的另一個(gè)非常有效的方法就是只使用必要的設(shè)備來處理相關(guān)事件。利用Erlang概率分布算法(圖表6)可以有效檢測出使用率較低的時(shí)段。
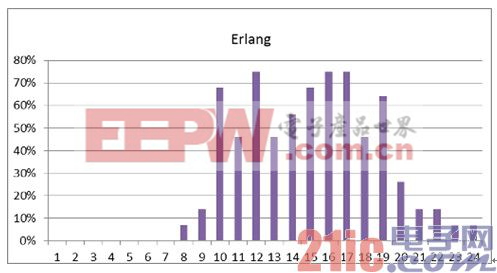
圖6:Erlang概率分布算法在電信網(wǎng)絡(luò)流量監(jiān)測中的實(shí)例
通過上面的圖表我們可以了解到,1點(diǎn)至7點(diǎn)期間的CPU使用率最低,然而,即使運(yùn)行在省電模式下,每片板卡仍然在消耗電能。在這種情況下,每片板卡在主動(dòng)電源管理的策略下會(huì)消耗90W的功耗,峰值性能時(shí)會(huì)上升至140W。解決的辦法就是利用實(shí)時(shí)遷移策略,用最少的CPU刀片在處理這些工作負(fù)載,同時(shí)將節(jié)能模式下的刀片切換到睡眠模式,這樣相比主動(dòng)電源管理的模式可以節(jié)約超過25%的功耗。
在工作負(fù)載和I/O處理方面,目前的市場和技術(shù)發(fā)展趨勢(shì)比較傾向采用將傳統(tǒng)的網(wǎng)絡(luò)架構(gòu)整合到一個(gè)通用平臺(tái)或模塊化的組件上來,以支持多網(wǎng)絡(luò)設(shè)備和提供不同的服務(wù)功能,如應(yīng)用處理、控制處理、包處理和信號(hào)處理功能等。處理器架構(gòu)以及新的軟件開發(fā)工具的功能提升,讓開發(fā)人員可以很容易的將工作負(fù)載整合到統(tǒng)一的刀片架構(gòu)中,這些負(fù)載包含了應(yīng)用、控制以及包處理等。通過軟硬件的整合,可以大幅度提升性能,并使得刀片式服務(wù)器架構(gòu)在包處理解決方案中的應(yīng)用大幅增加。
為了說明工作負(fù)載整合的演變,我們?cè)O(shè)計(jì)了一系列的測試方法。這些測試方法是在單一平臺(tái)中,通過將CPU制造商提供的DPDK整合到ATCA處理器刀片上,以此驗(yàn)證處理器刀片提供的性能以及整合的IP轉(zhuǎn)發(fā)服務(wù)。比較在沒有使用Intel® DPDK做任何優(yōu)化時(shí),采用原生 Linux(Native Linux) IP轉(zhuǎn)發(fā)時(shí)的第三層轉(zhuǎn)發(fā)性能。然后,我們?cè)俜治霾捎肐ntel® DPDK技術(shù)之后所獲得的IP轉(zhuǎn)發(fā)性能提升的原因。
數(shù)據(jù)平面開發(fā)套件
DPDK(Data Plane Development Kit,數(shù)據(jù)平面開發(fā)套件)是一個(gè)專為x86架構(gòu)處理器提供的輕量級(jí)運(yùn)行環(huán)境。它提供了低功耗和Run-to-Completion(RTC,運(yùn)行到完成)模式,以此最大限度的提升數(shù)據(jù)包的處理性能。而且DPDK還包含了優(yōu)化的和高效的函數(shù)庫,為用戶提供豐富的選擇,例如我們熟知的環(huán)境抽象層(EAL,Environment Abstraction Layer),它負(fù)責(zé)控制低級(jí)資源并提供優(yōu)化的輪詢模式驅(qū)動(dòng)(PMD,Poll Mode Driver),以及更高級(jí)別應(yīng)用的完整API接口,圖7為軟件層級(jí)結(jié)構(gòu)圖。
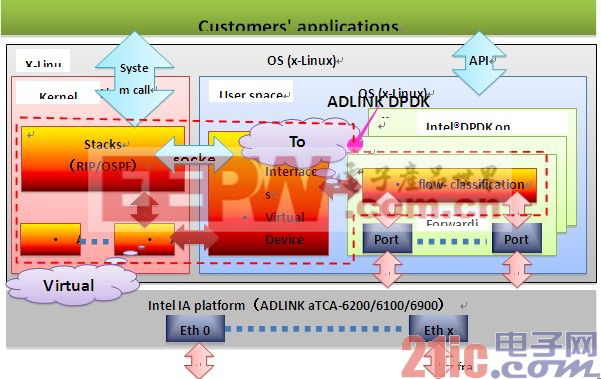
圖7: Linux應(yīng)用環(huán)境下的EAL和GLIBC
測試拓?fù)浣Y(jié)構(gòu)
為了測量ATCA處理器刀片在第三層處理和轉(zhuǎn)發(fā)IP包的速度,我們使用圖8中所示的環(huán)境進(jìn)行測試。
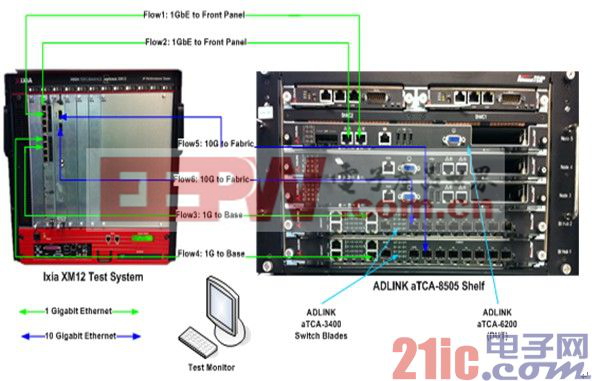
圖8:IP轉(zhuǎn)發(fā)測試環(huán)境
我們的測試使用了ATCA處理器刀片的2個(gè)10GbE外部接口和兩個(gè)10GbE Fabric接口(總計(jì)40G),通過比較使用和未使用DPDK的結(jié)果,我們可以得出結(jié)論:在相同的硬件平臺(tái)下,使用DPDK后的Linux僅用兩個(gè)CPU線程進(jìn)行IP轉(zhuǎn)發(fā)的性能,與原生 Linux(Native Linux)使用全部的CPU線程進(jìn)行IP轉(zhuǎn)發(fā)的性能相比,前者是后者的10倍。使用DPDK的平臺(tái),3層小數(shù)據(jù)包的轉(zhuǎn)發(fā)線速可以達(dá)到>70%。DPDK中優(yōu)化過的軟件堆棧可以實(shí)現(xiàn)10倍性能的提升。如果在一個(gè)基于IA架構(gòu)的刀片的控制層和數(shù)據(jù)層配備DPDK,就可以減少一個(gè)40G的NPU刀片。通常一個(gè)40G的GPU刀片的功耗為180W,因此通過工作負(fù)載整合可以節(jié)省56%的能耗。

評(píng)論