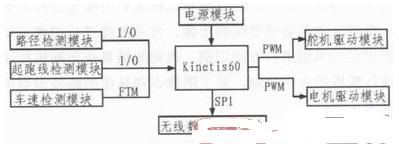
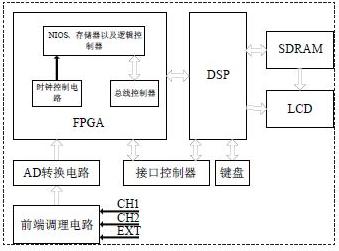
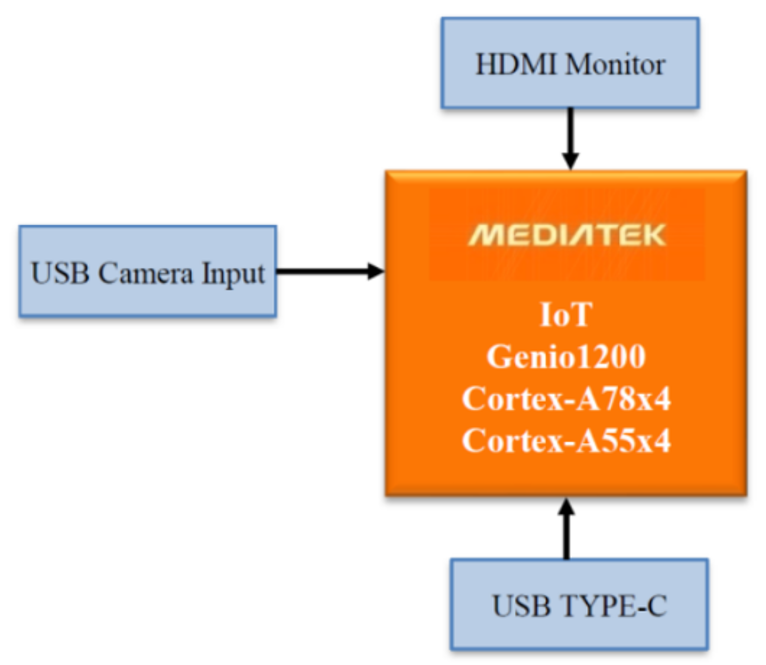
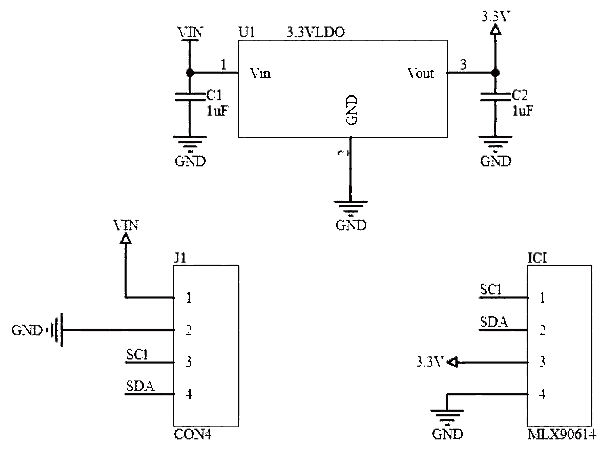
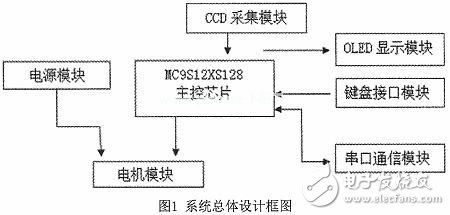
康謀分享 | 突破傳統(tǒng)匿名化:先進(jìn)技術(shù)解鎖數(shù)據(jù)價值新維度

海量數(shù)據(jù)的收集使得新舊企業(yè)能夠利用機(jī)器學(xué)習(xí)技術(shù)開發(fā)新產(chǎn)品并革新舊產(chǎn)品。近年來,數(shù)據(jù)質(zhì)量因直接影響了人工智能系統(tǒng)的性能和魯棒性而備受關(guān)注。然而,這對通常通過破壞像素信息(如模糊化、馬賽克等)來實現(xiàn)匿名化的方法提出了挑戰(zhàn),這些方法導(dǎo)致合規(guī)性與數(shù)據(jù)質(zhì)量之間難以兼得。
我們探索了一種不是簡單移除像素信息,而是對其進(jìn)行自然替換的深度自然匿名化(Deep Natural Anonymization,DNAT)方法,致力于提高匿名化數(shù)據(jù)價值,助力企業(yè)開發(fā)創(chuàng)新。
一、匿名化數(shù)據(jù)的傳統(tǒng)矛盾DNAT能夠檢測人臉、車牌等可識別信息,并為每個對象生成人工替換。每個替換都盡可能匹配源對象的屬性,但這種匹配是有選擇性的,我們可以靈活控制保留哪些屬性。
例如,對于人臉,保留性別和年齡等屬性可能對后續(xù)分析至關(guān)重要。對于可識別信息以外的內(nèi)容,不包含敏感個人數(shù)據(jù)的信息則保留不做修改。通過這種方式,DNAT成功打破了數(shù)據(jù)消除與匿名化之間的傳統(tǒng)矛盾。

圖1: 匿名化工具的比較,從左至右依次為:Facepixelizer,YouTube,F(xiàn)ast Redaction,DNAT,原圖
為了衡量匿名化方法對數(shù)據(jù)質(zhì)量的影響,我們從Labeled Face in the Wild(LFW)數(shù)據(jù)集中采樣了圖像。所有圖像均取自測試集。我們比較了代表匿名化技術(shù)的四種不同的匿名化工具,圖1顯示了這些示例的一部分。
二、匿名化的結(jié)構(gòu)一致性首先,我們分析了圖像在匿名化處理后的整體結(jié)構(gòu)變化。為此,我們仔細(xì)研究了圖像分割結(jié)果。圖像分割是將圖像的像素劃分為多個片段的過程,每個片段代表一個對象類別。在我們的示例中,最重要的對象是個人資料圖片中的人物和背景。
圖2和圖3展示了LFW數(shù)據(jù)集中兩位名人的分割圖。這些分割圖是由語義分割模型DeepLabv3+生成的,采用了官方TensorFlow存儲庫中的實現(xiàn)和模型權(quán)重。

圖2: AI Pacino DeepLabv3+ 分割結(jié)果對比

圖3: Reese witherspoon DeepLabv3+ 分割結(jié)果對比
從圖2和圖3中可以看出,傳統(tǒng)匿名化方法的分割圖明顯退化,其中一些甚至完全錯誤。然而,深度自然匿名化(DNAT)保留了語義分割。分割圖與原始圖像幾乎完全相同。從圖3中可以看出,經(jīng)過傳統(tǒng)匿名化方法處理的人臉圖像不僅產(chǎn)生了較差的分割邊界,還使分割模型推斷出原始圖像中從未出現(xiàn)的新對象類別,如貓、狗或瓶子。
為了量化每種匿名化技術(shù)的影響,我們計算了整個測試集的平均交并比(mIOU)。計算是在不同方法生成的圖像分割圖與原始圖像分割圖之間進(jìn)行的。結(jié)果如表1所示。
表1:用mIOU測量的語義分割一致性(越高越好)

為了評估匿名化圖像與原始圖像之間的整體內(nèi)容一致性,我們使用了Clarifai的獨立圖像標(biāo)注模型。“通用圖像標(biāo)注模型能夠識別超過11,000種不同的概念,包括對象、主題、情緒等。”這些標(biāo)簽描述了模型從輸入圖像中推斷出的內(nèi)容。
此外,模型還為每個標(biāo)簽提供了置信度。圖4展示了Clarifai公共圖像標(biāo)注模型對原始圖像及其DNAT版本預(yù)測的前5個概念。

圖4:來自clarifai的Reese Witherspoon前5個概念。(左原始圖像,右DNAT)
理想情況下,通用圖像標(biāo)注模型應(yīng)該為原始圖像和匿名化圖像預(yù)測完全相同的概念。為了衡量一致性,我們使用Clarifai為每種匿名化技術(shù)的所有測試樣本預(yù)測概念。然后,我們計算了匿名化圖像與原始圖像之間前N個預(yù)測概念的平均精度(mAP)(其中N代表不同概念的數(shù)量)。
通過mAP,我們評估了兩點:預(yù)測概念的一致性及其相關(guān)分?jǐn)?shù)。例如,考慮一個匿名化圖像及其原始圖像對,經(jīng)過圖像標(biāo)注模型處理后,如果某個概念在匿名化圖像中的置信度值低于其在原始圖像中的置信度值,則對最終mAP分?jǐn)?shù)的影響較小;而如果某個概念僅出現(xiàn)在匿名化圖像中,而未出現(xiàn)在其原始圖像中,則影響較大。
前5和前50個概念的結(jié)果如表2所示。
表2:用mAP測量圖像概念一致性(越高越好)

本文探討了如何通過深度自然匿名化(DNAT)技術(shù)提升匿名化數(shù)據(jù)的價值,打破了傳統(tǒng)匿名化方法在合規(guī)性與數(shù)據(jù)質(zhì)量之間的固有權(quán)衡。DNAT通過生成自然替換而非破壞像素信息,不僅有效保護(hù)了個人隱私,還最大限度地保留了數(shù)據(jù)的分析價值。
實驗表明,DNAT在圖像分割和內(nèi)容一致性方面顯著優(yōu)于傳統(tǒng)匿名化方法,能夠更好地支持后續(xù)的AI分析和應(yīng)用。
*博客內(nèi)容為網(wǎng)友個人發(fā)布,僅代表博主個人觀點,如有侵權(quán)請聯(lián)系工作人員刪除。