研究人員用“成員推斷攻擊”檢索大模型知識庫,攻擊精度達到80%



知識檢索增強系統,是已被用于大模型的技術之一,能有效解決大模型存在的知識更新不及時和幻覺等問題。
知識檢索增強的存在使得大模型無需通過模型訓練來適應下游任務,而是能夠通過一個外掛的知識庫,檢索與用戶所提的問題最相關的文本,并將這些文本集成為大模型的輸入,從而優化模型生成的內容。
想象一下,知識檢索增強就像是給 AI 裝上了一個超級圖書館。當我們向 AI 提問時,它不需要把所有知識都記在“大腦”里,而是在這個“圖書館”中快速查找最相關的信息,然后基于這些信息給出回答。
然而,知識檢索增強雖然實用并且使用門檻較低,但也同樣帶來了風險。
已有研究表明,只需向知識檢索增強的知識庫中注入一些有害信息,就能誘導大模型產生不當的回答。可見知識檢索增強系統本身并不安全。
更令人擔憂的是:知識檢索增強系統的知識庫本身安全嗎?知識庫中的信息通常是私有的,會不會存在被泄露的風險?
想象一下,在醫療領域,知識檢索增強系統的知識庫里可能包含大量的醫療問答數據。一旦這些信息被泄露,病人的隱私就會受到嚴重威脅。
因此,知識檢索增強的數據安全尤為重要,但在此前只有來自于 IBM 研究實驗室和南洋理工大學的研究人員關注這個問題。
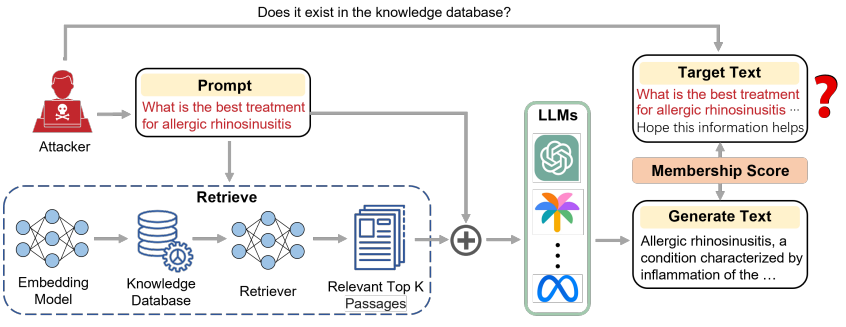
為了驗證這些問題,近期有研究人員設計了一種新的算法,旨在通過成員推斷攻擊(MIA,Membership Inference Attack)來判斷知識檢索增強系統的知識庫中所存儲的信息。
成員推斷攻擊,是用來測試模型隱私性的一種通用技術。它的工作原理可以理解為是在玩一個猜謎游戲:通過觀察模型的損失值、置信度、困惑度等信息,來推測它是否“見過”某個樣本。
但是,傳統的成員推斷攻擊主要針對那些參數化的 AI 模型,并不適用于知識檢索增強這樣非參數化系統。
而該團隊提出的新算法僅通過一個黑盒的應用程序編程接口(API,Application Programming Interface),無需介入模型訓練過程,也無需知道模型內部信息。僅通過模型輸出就能有效判斷某個信息是否存在于知識檢索增強的知識庫中。
具體來說,課題組將用戶的輸入文本劃分為兩部分。前半部分作為 prompt,使得知識檢索增強系統能檢索與 prompt 最相關的信息并生成輸出文本。
假如輸入文本存在于知識庫中,模型生成的內容會與輸入文本非常相似,且生成文本的困惑度更低。
因此,他們通過輸入文本和輸出文本的相似度以及模型生成的困惑度作為評判標準,來判斷輸入文本是否存在于知識庫中。
實驗結果顯示,本次方法能夠達到 80% 以上的攻擊精度,證明知識檢索增強系統的知識庫的確存在隱私泄露的風險。

圖 | 相關論文(來源:arXiv)
日前,相關論文以《眼見為信:針對檢索增強生成模型的“黑盒”會員推斷攻擊》(SEEING IS BELIEVING: BLACK-BOX MEMBERSHIP INFERENCE ATTACKS AGAINST RETRIEVAL AUGMENTED GENERATION)為題發在 arXiv[1]。
湖北大學人工智能學院楊洋副教授與國家級人才計劃專家程力教授課題組碩士生李鈺穎是論文第一作者,本論文在劉高揚博士和楊洋副教授的指導下完成。

圖 | 李鈺穎(來源:李鈺穎)
在應用前景上:
其一,本次研究證明知識檢索增強系統知識庫存在隱私泄露的風險,這有望推動科技公司重新審視他們的知識檢索增強系統,以便更加地重視用戶隱私。
因此,這可能會催生出一系列新的安全協議和行業標準,讓 AI 變得更加可信。
其二,本次研究有望提供一種數據確權的新方法。在數字時代,數據就是新的石油。但是,如何證明數據的所屬權?
現有研究只能對模型的預訓練數據進行確權,但本次成果有望對知識檢索增強知識庫中的數據進行確權。
在未來,這可能會成為數據版權保護的新方法,讓數據所有者能更好地維護自己的權益。
其三,隨著《數據安全法》的實施和相關法律法規的出臺,本次成果可能成為一個重要的取證手段,在數字世界的法律糾紛中發揮關鍵作用。
例如,在未來的知識產權糾紛中,本次成果可能會被用來證明某個模型是否使用了受保護的數據。
其四,隨著人們對隱私保護的意識日益增強,本次成果可能會衍生出一些個人使用的數據管理工具。
想象一下,未來人們可以用一個 APP 來檢測個人信息是否被不當用于 AI 系統,以增強個人對隱私數據的控制力。
其五,本次成果也可能被用來對 AI 系統進行“健康檢查”。公司和機構可以定期使用這種技術對知識檢索增強系統進行審核,確保沒有意外泄露用戶信息或存儲不當數據。
(來源:arXiv)
目前,課題組已經設計出一套攻擊方案,并證明了該方案的可行性。但是,這一系列研究不會止步于此。
目前的工作已經揭示了基于大模型及其各種應用系統存在的數據安全隱患,但關于這些隱患的成因,目前尚無公認的結果。
眼下該團隊正在加緊研究大模型內部的機制,尤其是在模型的記憶和正向推理過程中,重點分析信息流動和處理的關鍵環節,深入研究可能導致隱私泄露的薄弱環節。
同時,課題組正在探究模型信息回溯和信息整合的內在機理,為從根本上解決大模型數據隱私安全問題提供扎實的理論和實踐基礎。
研究人員表示:“本工作由湖北大學人工智能學院、智能感知系統與安全教育部重點實驗室以及華中科技大學電子信息與通信學院、智能互聯網技術湖北省重點實驗室聯合發布,該成果將先推廣至國家電網等信息安全敏感單位,目前正在洽談中。”
運營/排版:何晨龍
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
