密歇根大學團隊打造多模態大模型,能用于可穿戴設備和具身AI智能體

但是,人類依靠自己的大腦不僅僅可以讀寫文字,還可以看圖、看視頻、聽音樂等。所以,為了讓 AI 更接近真實世界,將額外的模態比如圖像輸入,融入大語言模型從而打造多模態大模型(MLLMs,Multi-modal LLMs),被認為是 AI 發展的一個關鍵新領域。相比純文本數據,多模態數據更加難以獲取,而從零開始直接訓練多模態模型也比較困難。因此,目前的主流方法是基于預訓練好的大語言模型,為其配備一個視覺感知模塊,來獲取多模態感知能力。典型的該類模型有 Flamingo、BLIP、LLaVA、MiniGPT4 等。這些模型可以處理圖片輸入,根據用戶的問題生成相應的文本回復。然而,研究發現盡管這些模型表現出不錯的多模態理解能力,但是存在嚴重的視覺幻覺問題。具體表現為:幻想圖片中不存在的物體、回答中對圖片內容的描述與事實嚴重不符等。該問題的本質其實是:現有模型在細粒度文本圖像匹配能力上存在缺失。近期,Kosmos、Shikra 和 Ferret 等模型,將 Grounding 能力引入了 MLLM(即 Grounding MLLM)。它指的是當模型在輸出文本時,可以同時輸出名詞短語所對應物體的邊界框坐標,以表示該物體在圖片中的位置。實驗結果證明,此類模型具備更可靠的性能,能顯著減少視覺幻覺的發生。此外,由于模型可以更全面地呈現輸出文本和文本所指物體在圖片中的位置關系,因此可以給用戶提供信息量更多、也更容易理解的內容輸出。然而,目前基于邊界框的 Grounded MLLM 模型仍然存在幾個問題:首先,受限于長方形物體邊界框的表達能力,現有模型無法進行更精細的文本實體定位。例如,當文本所指物體是不規則的背景形狀(如天空、樹林)時,或者和其他物體有部分重疊或位置交錯等,邊界框無法準確表達所表示物體的位置,以至于容易產生歧義。其次,受限于模型訓練數據的多樣性,現有模型僅限于指代單個物體,而很難生成物體局部區域、多個物體組成的整體、以及圖片中文本的指代。最后,現有模型是基于圖像的隱式特征,來直接預測物體的邊界框坐標。而這一過程并不透明,當出現物體指代錯誤時,很難診斷問題是出在檢測上——即沒有成功檢測到目標物體,還是出在識別上——即成功檢測到物體但是識別錯誤。
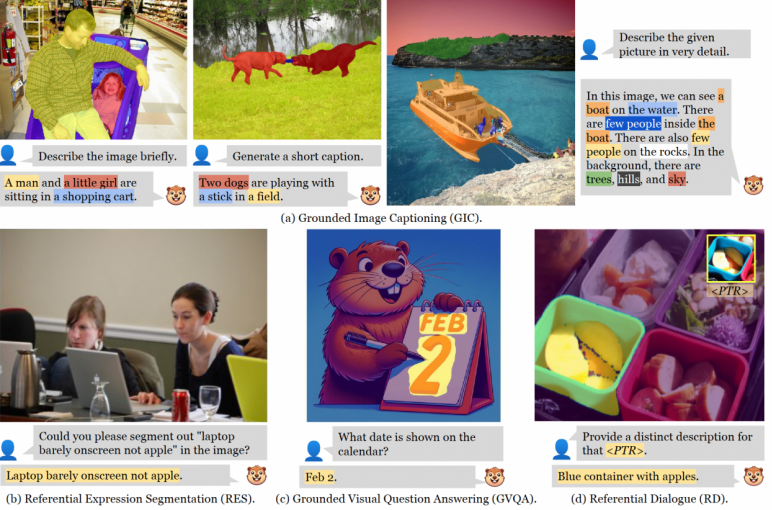 圖 | GROUNDHOG 支持的任務示例(來源:arXiv)針對這些問題,美國密歇根大學博士生張亦弛和所在團隊提出了 GROUNDHOG,這是一個可以支持大型語言模型與視覺實體進行像素級語義對齊的 Grounded MLLM 模型。
圖 | GROUNDHOG 支持的任務示例(來源:arXiv)針對這些問題,美國密歇根大學博士生張亦弛和所在團隊提出了 GROUNDHOG,這是一個可以支持大型語言模型與視覺實體進行像素級語義對齊的 Grounded MLLM 模型。 圖 | 張亦弛(來源:張亦弛)對于已有的 MLLM 模型來說,其采用輸入 patch-level 視覺特征后直接輸出定位坐標的黑盒架構。而 GROUNDHOG 的關鍵思想是將 Language Grounding(語言接地)解藕成兩個階段:定位和識別。在定位階段:首先,由一個可以提出各種不同實體區域分割的專家模型,提供圖像中所有實體的分割。然后,通過一個掩碼特征提取器,提取每個實體的視覺特征,以此作為多模態語言模型的輸入。在識別階段:當大語言模型解碼出可進行視覺錨定的短語時,就會從輸入的所有實體中,選擇相應的實體分割進行融合,借此得到文本對應的視覺分割區域。這種分離的設計不僅允許獨立優化實體分割模型和多模態語言模型,還提高了錯誤分析的可解釋性,并允許 MLLM 與多種視覺專家模型靈活結合,從而提高整體性能。
圖 | 張亦弛(來源:張亦弛)對于已有的 MLLM 模型來說,其采用輸入 patch-level 視覺特征后直接輸出定位坐標的黑盒架構。而 GROUNDHOG 的關鍵思想是將 Language Grounding(語言接地)解藕成兩個階段:定位和識別。在定位階段:首先,由一個可以提出各種不同實體區域分割的專家模型,提供圖像中所有實體的分割。然后,通過一個掩碼特征提取器,提取每個實體的視覺特征,以此作為多模態語言模型的輸入。在識別階段:當大語言模型解碼出可進行視覺錨定的短語時,就會從輸入的所有實體中,選擇相應的實體分割進行融合,借此得到文本對應的視覺分割區域。這種分離的設計不僅允許獨立優化實體分割模型和多模態語言模型,還提高了錯誤分析的可解釋性,并允許 MLLM 與多種視覺專家模型靈活結合,從而提高整體性能。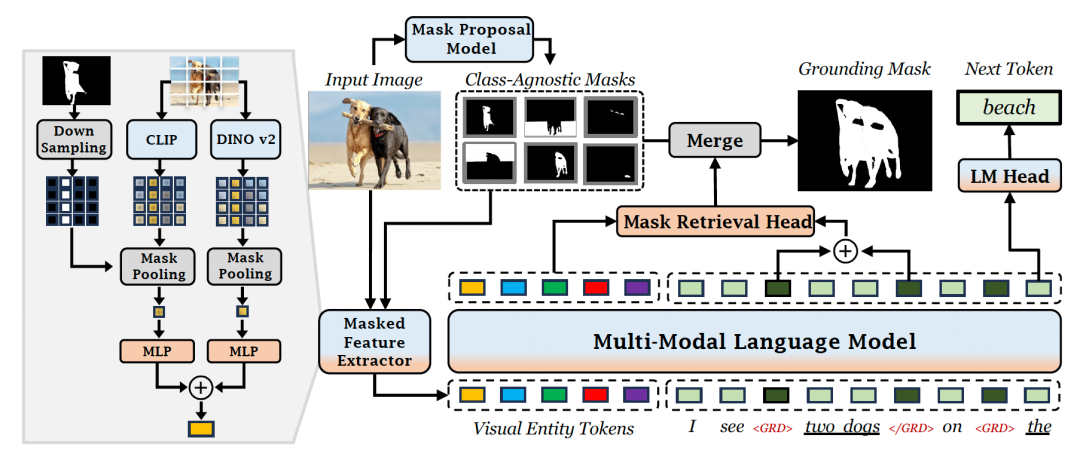 圖 | GROUNDHOG 架構(來源:arXiv)此外,GROUNDHOG 的這種設計模式可以自然拓展到區域級的圖像理解任務,能夠靈活地接受任何圖像中的位置和區域指代方式來作為輸入。另據悉,不同于 GPT4ROI、Ferret 等現有模型需要引入額外的 spatial prompt encoder,GROUNDHOG 可以直接和 SAM(Segment Anything)等預訓練專家模型結合,從而處理位置的指代輸入,進而極大拓展應用場景。
圖 | GROUNDHOG 架構(來源:arXiv)此外,GROUNDHOG 的這種設計模式可以自然拓展到區域級的圖像理解任務,能夠靈活地接受任何圖像中的位置和區域指代方式來作為輸入。另據悉,不同于 GPT4ROI、Ferret 等現有模型需要引入額外的 spatial prompt encoder,GROUNDHOG 可以直接和 SAM(Segment Anything)等預訓練專家模型結合,從而處理位置的指代輸入,進而極大拓展應用場景。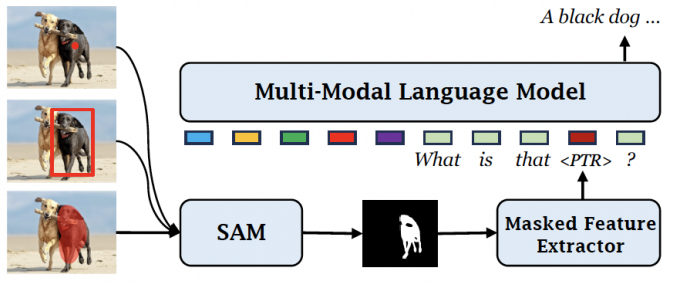 圖 | 與 SAM 無縫銜接處理各種形式的位置提示輸入(來源:arXiv)據了解,為了訓練 GROUNDHOG,課題組整合了 27 個現有數據集的 2.5M 文本-圖像對,并進行了衍生和增強。通過此,他們組成一個名為 M3G2 的新數據集,以便用于學習多模態多粒度的視覺文本對齊能力。M3G2 包括圖文錨定描述、指代物體分割、圖文錨定問答、視覺指代對話 4 大類任務,涵蓋 36 種子任務,具備豐富的視覺文本對齊標注能力。
圖 | 與 SAM 無縫銜接處理各種形式的位置提示輸入(來源:arXiv)據了解,為了訓練 GROUNDHOG,課題組整合了 27 個現有數據集的 2.5M 文本-圖像對,并進行了衍生和增強。通過此,他們組成一個名為 M3G2 的新數據集,以便用于學習多模態多粒度的視覺文本對齊能力。M3G2 包括圖文錨定描述、指代物體分割、圖文錨定問答、視覺指代對話 4 大類任務,涵蓋 36 種子任務,具備豐富的視覺文本對齊標注能力。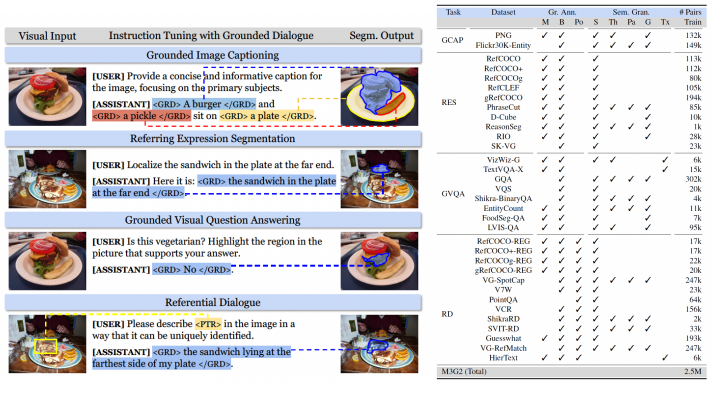 圖 | M3G2 數據集的 4 種任務示例及數據統計(來源:arXiv)通過相關實驗,該團隊證明 GROUNDHOG 在各種視覺文本對齊任務上,都能達到很好的性能,且無需針對特定任務進行微調。此外,GROUNDHOG 能顯著減少視覺幻覺現象的出現,并在失敗案例中提供了易于理解的診斷信息,為需要精確視覺理解和自然語言處理的領域的發展奠定了一定基礎。
圖 | M3G2 數據集的 4 種任務示例及數據統計(來源:arXiv)通過相關實驗,該團隊證明 GROUNDHOG 在各種視覺文本對齊任務上,都能達到很好的性能,且無需針對特定任務進行微調。此外,GROUNDHOG 能顯著減少視覺幻覺現象的出現,并在失敗案例中提供了易于理解的診斷信息,為需要精確視覺理解和自然語言處理的領域的發展奠定了一定基礎。 (來源:arXiv)GROUNDHOG 模型的一個典型應用場景,便是在可穿戴設備中,推動多模態 AI 助手的發展。試想這樣一個情境:當顧客佩戴智能眼鏡在商場購物時,對著某個品牌的商品詢問 AI 助手:“這個商品好嗎,有更好評價的嗎?”AI 助手不僅能精確地識別顧客所指商品并能提供相關評價信息,還能智能推薦貨架上其他評價更高的商品。以及能在眼鏡屏幕上通過增強現實技術,高亮地顯示這些商品,便于顧客查找和比較。在顧客與多模態 AI 助手的互動中,這種結合視線追蹤理解用戶意圖的能力,加上視覺錨定增強輸出文本的效果,不僅可以提升交互的自然性,也能極大增強用戶體驗。“也就是說,GROUNDHOG 模型正是在這兩個關鍵能力上表現出色,從而能為推動下一代多模態 AI 助手的革新奠定基礎。”研究人員表示。GROUNDHOG 的另一個應用前景,在于能夠驅動具身 AI 智能體。比如,可以設計一個網絡瀏覽機器人,它通過接收網頁截圖和用戶意圖描述作為輸入,并輸出相應的鼠標操作或鍵盤操作。在這個場景中,點擊網頁元素——可被視作結合輸出文本(動作)和網頁交互元素位置的交互行為。比如,智能體輸出的動作為“點擊‘提交’按鈕”,然后識別并定位到截圖中的“提交”按鈕,并執行實際的點擊操作。研究人員表示:“GROUNDHOG 所提供的 Grounding 能力在這種視覺語言理解與動作執行相結合的應用場景中至關重要,進一步拓寬了多模態語言模型在用于 AI 智能體決策中的應用范圍。”事實上,該團隊最開始的研究動機是因為觀察到了多模態大語言模型中普遍存在的視覺幻覺現象,希望探索緩解這個問題的解決方案。經過深入思考之后,他們認為幻覺現象出現的根源還是在于模型視覺文本對齊能力的缺失。而現有模型由于架構上的限制,很難支持精細的像素級文本對齊。由此便想到:為何不打造一款新模型去解決這個問題呢?于是研究重心就從緩解視覺幻覺轉移到開發一款具備較強像素級視覺文本對齊能力的模型。幸運的是,當他們的架構能夠運營之后,該團隊在實驗中發現確實極大緩解了大模型的視覺幻覺問題,因此也算完成了他們的初衷。與此同時,在確定研究問題之后,很快他們就發現了現有模型存在可解釋性較差的問題,于是便確定了“先定位后識別”的主要框架。隨后,課題組開始尋找具體的實體分割模型。期間遇到了一些困難:其希望這個實體分割模型可以提供語義豐富、粒度多樣、高質量的實體分割圖片標簽。然而,在已有的預訓練分割模型中,要么只能給出有限的實體類別,要么無法很好地支持他們想要的多粒度分割。總之,并沒有可以滿足研究人員全部需求的模型。因此,他們通過整合 COCO、LVIS、PACO、Entity-V2、TextOCR 等現有的分割數據集,基于一個修改后的 Mask2Former 架構自行訓練了一個支持多樣、全面分割的模型 Mask2Former+,以此作為他們的實體分割模型。而在當時,另一個重要問題就是構建訓練模型的數據集。構建這種具備較為復雜的細粒度圖像文本對齊標注的數據集一般有兩種方式:要么通過重新整合現有數據集,要么通過現有的大模型對圖像進行標注加工。出于對任務豐富性和數據質量的考慮,他們選擇了前者,并盡可能地收集了學術界已有的能夠納入本次任務框架的數據集。隨后,該團隊通過 ChatGPT 生成了對話模板,將所有數據整合為了人機對話的形式。最后,他們選擇在視覺文本對齊任務中一些比較有代表性的 benchmark,對本次模型加以量化評測與分析。日前,相關論文以《GROUNDHOG:將大型語言模型建立在整體分割的基礎上》(GROUNDHOG:Grounding Large Language Models to Holistic Segmentation)為題發在 arXiv[1]。
(來源:arXiv)GROUNDHOG 模型的一個典型應用場景,便是在可穿戴設備中,推動多模態 AI 助手的發展。試想這樣一個情境:當顧客佩戴智能眼鏡在商場購物時,對著某個品牌的商品詢問 AI 助手:“這個商品好嗎,有更好評價的嗎?”AI 助手不僅能精確地識別顧客所指商品并能提供相關評價信息,還能智能推薦貨架上其他評價更高的商品。以及能在眼鏡屏幕上通過增強現實技術,高亮地顯示這些商品,便于顧客查找和比較。在顧客與多模態 AI 助手的互動中,這種結合視線追蹤理解用戶意圖的能力,加上視覺錨定增強輸出文本的效果,不僅可以提升交互的自然性,也能極大增強用戶體驗。“也就是說,GROUNDHOG 模型正是在這兩個關鍵能力上表現出色,從而能為推動下一代多模態 AI 助手的革新奠定基礎。”研究人員表示。GROUNDHOG 的另一個應用前景,在于能夠驅動具身 AI 智能體。比如,可以設計一個網絡瀏覽機器人,它通過接收網頁截圖和用戶意圖描述作為輸入,并輸出相應的鼠標操作或鍵盤操作。在這個場景中,點擊網頁元素——可被視作結合輸出文本(動作)和網頁交互元素位置的交互行為。比如,智能體輸出的動作為“點擊‘提交’按鈕”,然后識別并定位到截圖中的“提交”按鈕,并執行實際的點擊操作。研究人員表示:“GROUNDHOG 所提供的 Grounding 能力在這種視覺語言理解與動作執行相結合的應用場景中至關重要,進一步拓寬了多模態語言模型在用于 AI 智能體決策中的應用范圍。”事實上,該團隊最開始的研究動機是因為觀察到了多模態大語言模型中普遍存在的視覺幻覺現象,希望探索緩解這個問題的解決方案。經過深入思考之后,他們認為幻覺現象出現的根源還是在于模型視覺文本對齊能力的缺失。而現有模型由于架構上的限制,很難支持精細的像素級文本對齊。由此便想到:為何不打造一款新模型去解決這個問題呢?于是研究重心就從緩解視覺幻覺轉移到開發一款具備較強像素級視覺文本對齊能力的模型。幸運的是,當他們的架構能夠運營之后,該團隊在實驗中發現確實極大緩解了大模型的視覺幻覺問題,因此也算完成了他們的初衷。與此同時,在確定研究問題之后,很快他們就發現了現有模型存在可解釋性較差的問題,于是便確定了“先定位后識別”的主要框架。隨后,課題組開始尋找具體的實體分割模型。期間遇到了一些困難:其希望這個實體分割模型可以提供語義豐富、粒度多樣、高質量的實體分割圖片標簽。然而,在已有的預訓練分割模型中,要么只能給出有限的實體類別,要么無法很好地支持他們想要的多粒度分割。總之,并沒有可以滿足研究人員全部需求的模型。因此,他們通過整合 COCO、LVIS、PACO、Entity-V2、TextOCR 等現有的分割數據集,基于一個修改后的 Mask2Former 架構自行訓練了一個支持多樣、全面分割的模型 Mask2Former+,以此作為他們的實體分割模型。而在當時,另一個重要問題就是構建訓練模型的數據集。構建這種具備較為復雜的細粒度圖像文本對齊標注的數據集一般有兩種方式:要么通過重新整合現有數據集,要么通過現有的大模型對圖像進行標注加工。出于對任務豐富性和數據質量的考慮,他們選擇了前者,并盡可能地收集了學術界已有的能夠納入本次任務框架的數據集。隨后,該團隊通過 ChatGPT 生成了對話模板,將所有數據整合為了人機對話的形式。最后,他們選擇在視覺文本對齊任務中一些比較有代表性的 benchmark,對本次模型加以量化評測與分析。日前,相關論文以《GROUNDHOG:將大型語言模型建立在整體分割的基礎上》(GROUNDHOG:Grounding Large Language Models to Holistic Segmentation)為題發在 arXiv[1]。 圖 | 相關論文(來源:arXiv)關于上述數據集和本次模型的詳細介紹,可以參考本次論文的附錄。之后,他們也會將這部分數據處理和模型訓練的代碼一并公開。后續,他們希望能將 GROUDHOG 拓展到第一視角視頻,打造一個能夠處理視頻輸入的 Grounded MLLM 個人助手。參考資料:1.https://arxiv.org/pdf/2402.16846
圖 | 相關論文(來源:arXiv)關于上述數據集和本次模型的詳細介紹,可以參考本次論文的附錄。之后,他們也會將這部分數據處理和模型訓練的代碼一并公開。后續,他們希望能將 GROUDHOG 拓展到第一視角視頻,打造一個能夠處理視頻輸入的 Grounded MLLM 個人助手。參考資料:1.https://arxiv.org/pdf/2402.16846排版:初嘉實
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

