CMU華人18萬打造高能機器人,完爆斯坦福炒蝦機器人!全自主操作,1小時學會開12種門

 編輯:Aeneas 桃子【導讀】斯坦福炒菜機器人的大火,開啟了2024年機器人元年。最近,CMU研究團隊推出了一款能在開放世界完成任務的機器人,成本僅18萬元。沒見過的場景,它可以靠自學學會!
編輯:Aeneas 桃子【導讀】斯坦福炒菜機器人的大火,開啟了2024年機器人元年。最近,CMU研究團隊推出了一款能在開放世界完成任務的機器人,成本僅18萬元。沒見過的場景,它可以靠自學學會!比斯坦福炒蝦機器人還厲害的機器人來了!
最近,CMU的研究者只花費2.5萬美元,就打造出一個在開放世界中可以自適應移動操作鉸接對象的機器人。
 論文地址:https://arxiv.org/abs/2401.14403
論文地址:https://arxiv.org/abs/2401.14403厲害之處就在于,它是完全自主完成操作的。
看,這個機器人能自己打開各式各樣的門。
無論是需要按一下把手才能打開的門。
需要推開的門。

透明的彈簧門。

甚至是昏暗環境中的門。

它還能自己打開櫥柜。

打開抽屜。

自己打開冰箱。

甚至,它的技能推廣到訓練以外的場景。
結果發現,一個小時內,機器人學會打開20個從未見過的門,成功率從行為克隆預訓練的50%,飆升到在線自適應的95%。
即使眼前是一個它從未見過的門,這個優秀的小機器人也順利打開了!


英偉達高級科學家Jim Fan表示:
斯坦福的ALOHA雖然令人印象深刻,但很多動作都需要人類協同控制,但這個機器人,則是完全自主完成的一系列操作。
它背后的核心思想,就是在測試時進行RL,使用CLIP(或任何視覺語言模型)作為學習的獎勵函數。
這樣,就像ChatGPT用RLHF進行預訓練一樣,機器人可以對人類收集的軌跡進行預訓練(通過遠程控制),然后通過新場景進行RLHF,這樣就掌握了訓練以外的技能。

這項工作一經發布,立刻獲得了同行們的肯定。
「恭喜!這是將機械臂帶出實驗室的好裝置。」

「太令人激動了,讓機器人在線學習技能前景巨大!」

「如此便宜的定制硬件,會讓移動操作變得瘋狂。」
「永遠不要惹一個機器人,它已經學會開門了。」
讓我們具體看看,這個機器人是如何完成未見過的開門任務。
機器人自適應學習,性能暴漲至90%
當前多數機器人移動操作,僅限于拾取-移動-放置的任務。
由于多種原因,在「開放世界」中開發和部署,能夠處理看不見的物體機器人系統具有極大的挑戰性。
針對學習「通用移動操作」的挑戰,研究人員將研究重點放在一類有限的問題——涉及鉸接式物體的操作,比如開放世界中的門、抽屜、冰箱或櫥柜。
別看,開門、打開抽屜、冰箱這種日常生活中的操作對于每個人來說,甚至小孩子來說輕而易舉,卻是機器人的一大挑戰。
對此,CMU研究人員提出了「全棧」的方法來解決以上問題。

為了有效地操縱開放世界中的物體,研究中采用了「自適應學習」的框架,機器人不斷從交互中收集在線樣本進行學習。
這樣一來,即使機器人遇到了,不同鉸接模式或不同物理參數(因重量或摩擦力不同)的新門,也可以通過交互學習實現自適應。
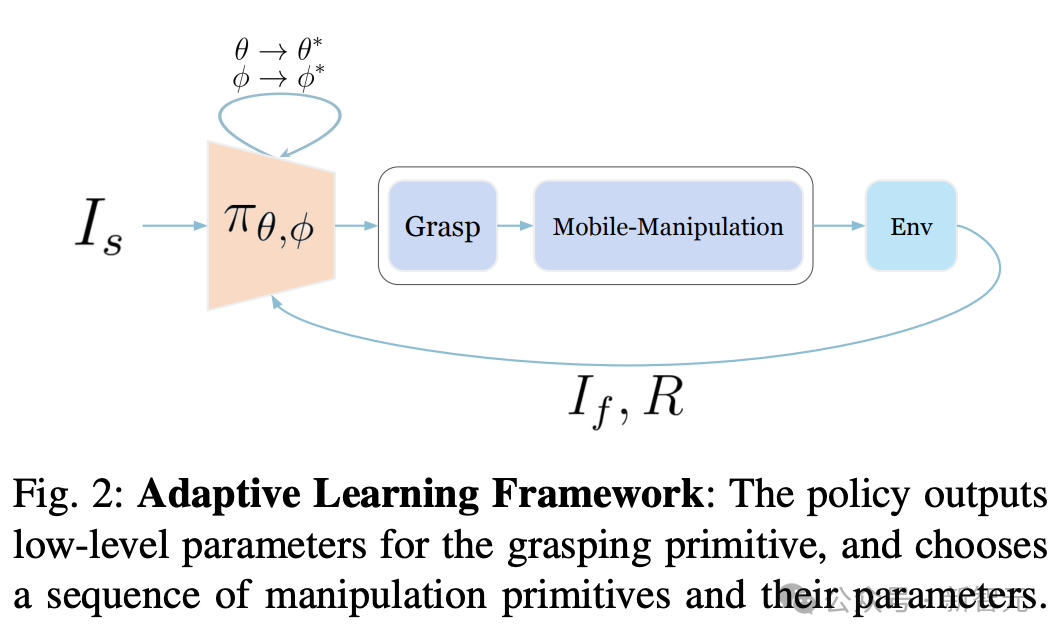
為了實現高效學習,研究人員使用一種結構化的分層動作空間。它使用固定的高級動作策略和可學習的低層控制參數。
使用這種動作空間,研究人員通過各種遠程操作演示的數據集,初始化了策略(BC)。這為探索提供了一個強有力的先驗,并降低了執行不安全動作的可能性。
成本僅2.5萬美金
此前,斯坦福團隊在打造Mobile ALOHA的所有成本用了3萬美元。
而這次,CMU團隊能夠以更便宜的成本——2.5萬美元(約18萬元),打造了一臺在通用世界使用的機器人。

如下圖3所示,展示了機器人硬件系統的不同組件。
研究人員選用了AgileX的Ranger Mini 2底座,因其具有穩定性,全向速度控制,和高負載稱為最佳選擇。
為了使這樣的系統有效,能夠有效學習至關重要,因為收集現實世界樣本的成本很高。
使用的移動機械手臂如圖所示。
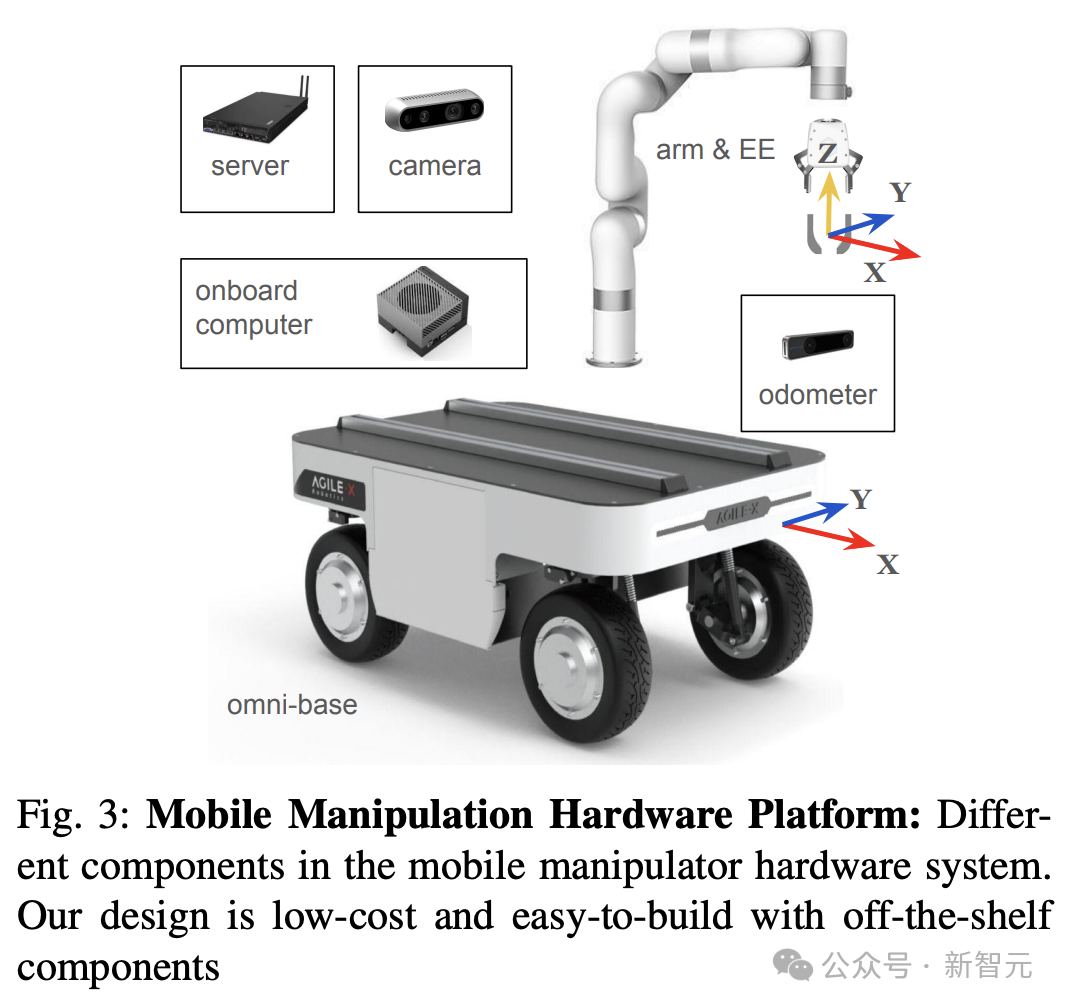
手臂采用了xArm進行操作,有效負載為5公斤,成本較低,可供研究實驗室廣泛使用。
CMU機器人系統使用了Jetson計算機來支持傳感器、底座、手臂,以及托管LLM的服務器之間的實時通信。
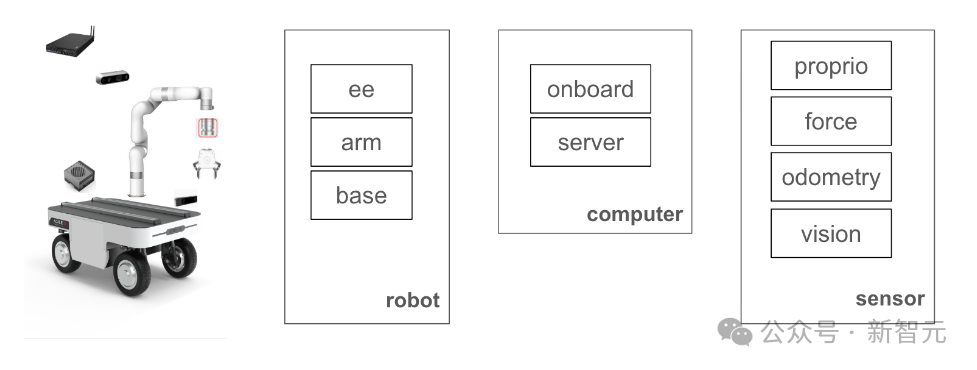
對于實驗數據的收集,是通過安裝在框架上的D435 IntelRealsense攝像頭來收集RGBD圖像,并使用T265 Intel Realsense攝像頭來提供視覺里程計,這對于在執行RL試驗時重置機器人至關重要。
另外,機器人抓手還配備了3D打印抓手和防滑帶,以確保安全穩定的抓握。
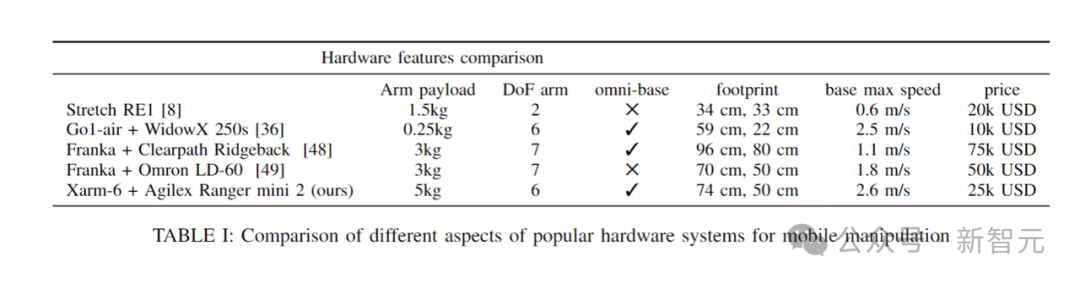
研究人員還將創建的模塊化平臺的關鍵方面,與其他移動操縱平臺進行比較。
看得出,CMU的機器人系統不論是在手臂負載力,還是移動自由度、全向驅動的底座、成本等方面具有明顯的優勢。
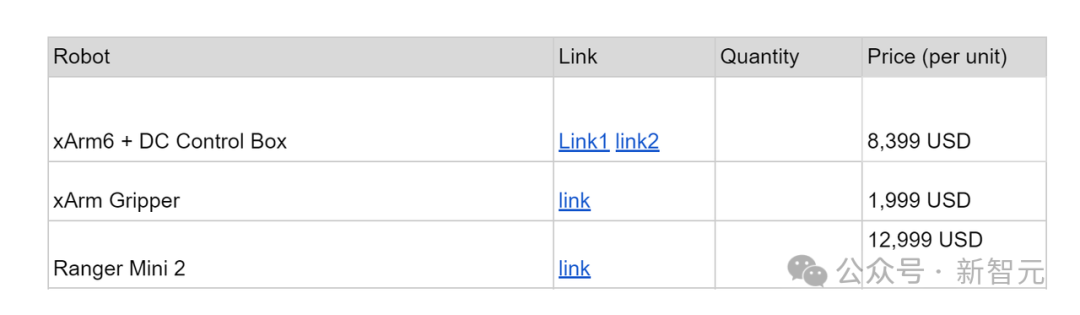 機器人成本
機器人成本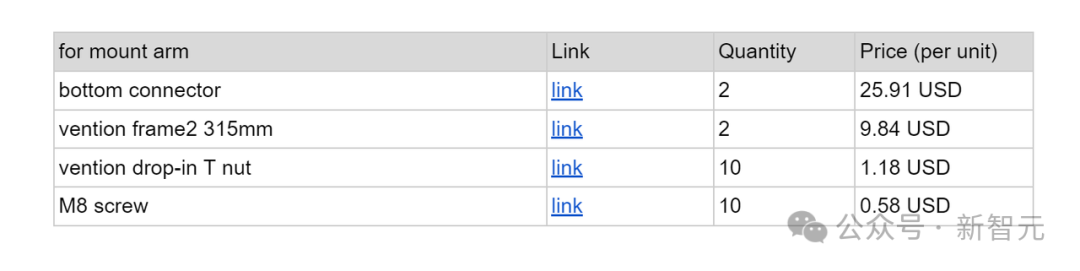 機械臂成本
機械臂成本原始實現
參數化原始動作空間的實現細節如下。
抓取為了實現這個動作,對于從實感相機獲得的場景RGBD圖像,研究者使用現成的視覺模型,僅僅給出文本提示,就能獲取門和把手的掩碼。
此外,由于門是一個平面,因此可以使用相應的掩碼和深度圖像,來估計門的表面法線。
這就可以將底座移動到靠近門的地方,使其垂直,并設置抓握把手的方向角度。
使用相機校準,將把手的2D掩碼中心投影到3D坐標,這就是標記的抓取位置。
原始抓取的低級控制參數,會指示要抓取位置的偏移量。
這是十分有益的,因為根據把手的類型,機器人可能需要到達稍微不同的位置,通過低級連續值參數,就可以來學習這一點。
約束移動操縱
對于機器人手臂末端執行器和機器人底座,研究者使用了速度控制。
通過在SE2平面中的6dof臂和3dof運動,他們創建了一個9維向量。
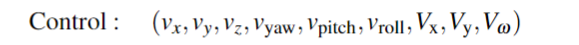
其中前6個維度對應手臂的控制,后三個維度對應底座。
研究者使用原始數據,對該空間施加了如下約束——
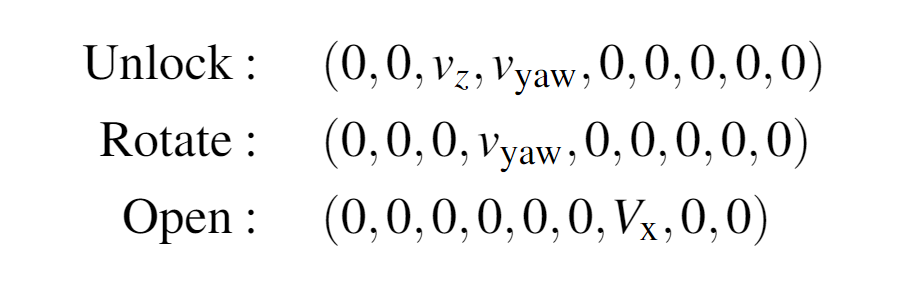
在控制機器人時,策略會輸出與要執行的原始數據相對應的索引,以及運動的相應低級參數。
低級控制命令的值從-1到1連續,并且會在一段固定的持續時間內執行。
參數的符號決定了速度控制的方向,順時針或逆時針用于解鎖和旋轉,向前或向后用于打開物體。
預訓練數據集
在這個項目中考慮的鉸接物體,由三個剛性部分組成:底座部分、框架部分和手柄部分。
其中包括門、櫥柜、抽屜和冰箱等物體。
它們的底座和框架通過旋轉接頭(如在櫥柜中)或棱柱接頭(如在抽屜中)連接。框架通過旋轉接頭或固定接頭連接到手柄。
因此,研究者確定了鉸接物體的四種主要類型,分類取決于與手柄的類型和關節機構。
手柄關節通常包括杠桿(A型)和旋鈕(B型)。
對于手柄沒有鉸接的情況,主體框架可以使用旋轉接頭(C型)繞鉸鏈旋轉,或者沿著柱接頭(例如抽屜)前后滑動(D型)。
雖然并不詳盡,但可以說這四種分類基本涵蓋了機器人系統可能遇到的各種日常鉸接物體。
然而,總還有機器人看不到的新型鉸接物體,為了提供操作這些新型鉸接物體的泛化優勢,研究者首先收集了離線演示數據集。
在BC訓練數據集中,包含了每個類別的3個對象,研究者為每個對象收集10個演示,總共生成120個軌跡。
此外,研究者還為每個類別保留了2個測試對象,用于泛化實驗。
訓練和測試對象在視覺外觀(例如紋理、顏色)、物理動力學(例如彈簧加載)和驅動(例如手柄關節可能是順時針或逆時針)方面存在顯著差異。

在圖4中,包含了訓練和測試集中使用的所有對象的可視化,以及它們來自集合的哪個部分,如圖5所示。
自主安全的在線自適應
在這項工作中,研究者們面臨的最大挑戰就在于,如何使用不屬于BC訓練集的新對象進行操作?
為了解決這個問題,他們開發了一個能夠完全自主強化學習(RL)在線適應的系統。
安全意識探索確保機器人所采取的探索動作對其硬件來說是安全的,這一點至關重要,特別是它是在關節約束下與物體交互的。
理想情況下,機器人應該可以解決動態任務,比如使用不同力量控制開門。
然而,研究者使用的xarm-6這種低成本手臂,不支持精確的力感應。

因此,為了部署系統,研究者使用了基于在線采樣期間讀取聯合電流的安全機制。
如果機器人采樣到導致關節電流達到閾值的動作,該事件就會終止,并重置機器人,以防止手臂可能會損害到自身,并且會提供負面獎勵,來抑制此類行為。
獎勵規范在實驗中,人類操作員會給機器人提供獎勵。
如果機器人成功開門,則獎勵+1,如果失敗則獎勵0,如果存在安全違規則獎勵-1。
這種獎勵機制是可行的,因為系統只需要很少的樣本來學習。
然而,對于自主學習,研究者希望消除依賴人類出現在循環中的瓶頸。
在這種情況下,他們研究了使用大型視覺語言模型作為獎勵來源的辦法。
具體來說,他們使用CLIP來計算兩個文本提示與機器人執行后觀察到的圖像之間的相似度得分。
研究者使用的兩個提示是「門已關閉」和「門已打開」,他們會計算最終觀察到的圖像和每個提示的相似度得分。
如果圖像更接近指示門打開的提示,則分配獎勵+1,否則分配獎勵0。如果觸發安全保護,獎勵為-1。
在這個過程中,機器人會采用視覺里程計,利用安裝在其底座上的T265跟蹤攝像頭,使其能夠導航回初始位置。
每次行動結束時,機器人會放開抓手,并移回原來的SE2基地位置,并拍攝If的圖像以用于計算獎勵。
然后,研究者對SE2基地位置進行隨機擾動,以便策略變得更加穩健。
此外,如果獎勵為1,門被打開時,機器人就會有一個腳本例程,來把門關上。
實驗結果
研究人員在CMU校園內四棟不同建筑中(12個訓練對象和8個測試對象),對全新架構加持的機器人系統進行了廣泛的研究。
具體回答了以下幾個問題:
1)系統能否通過跨不同對象類別的在線自適應,來提高未見過對象的性能?
2)這與僅在提供的演示中,使用模仿學習相比如何?
3)可以使用現成的視覺語言模型自動提供獎勵嗎?
4)硬件設計與其他平臺相比如何?(硬件部分已進行了比較)
在線自適應a. 不同物體類別評估
研究人員在4個類別的固定銜接物體上,對最新的方法進行了評估。
如下圖6所示,呈現了從行為克隆初始策略開始,利用在線交互進行5次迭代微調的持續適應性能。
每次改進迭代包括5次策略rollout,之后使用等式5中的損失對模型進行更新。
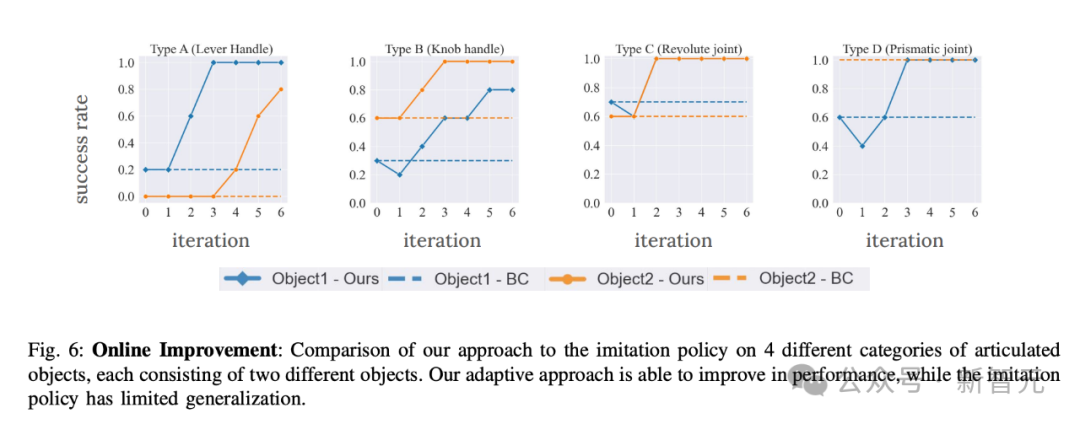
可以看到,最新方法將所有對象的平均成功率從50%提高到95%。因此,通過在線交互樣本不斷學習能夠克服初始行為克隆策略的有限泛化能力。
自適應學習過程能夠從獲得高獎勵的軌跡中學習,然后改變其行為,更頻繁地獲得更高的獎勵。
在BC策略性能尚可的情況下,比如平均成功率約為70%的C類和D類對象,RL能夠將策略完善到100%的性能。
此外,即使初始策略幾乎無法執行任務,強化學習也能夠學習如何操作對象。這從A類實驗中可以看出,模仿學習策略的成功率非常低,只有10%,完全無法打開兩扇門中的一扇。
通過不斷的練習,RL的平均成功率可以達到90%。
這表明,RL可以從模仿數據集中探索出可能不在分布范圍內的動作,并從中學習,讓機器人學會如何操作未見過的新穎的鉸接物體。
b. Action-replay基線
還有另一種非常簡單的方法,可以利用演示數據集在新對象上執行任務。
研究團隊針對2個特別難以進行行為克隆的對象(A類和B類各一個(按壓杠桿和旋鈕手柄)運行了這一基線。
這里,采取了開環和閉環兩種方式對這一基線進行評估。
在前一種情況下,只使用第一張觀察到的圖像進行比較,并執行整個檢索到的動作序列;而在后一種情況下,每一步執行后都會搜索最近的鄰居,并執行相應的動作。
從表3中可以看出,這種方法非常無效,進一步凸顯了實驗中訓練對象和測試對象之間的分布差距。

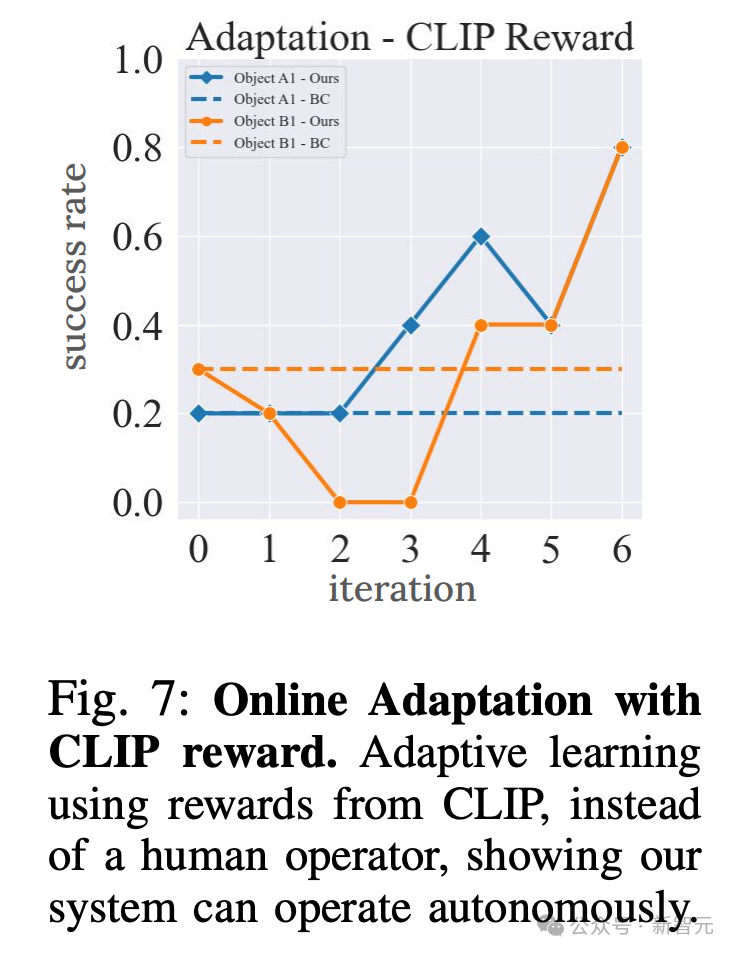
c. 通過VLM自主獎勵
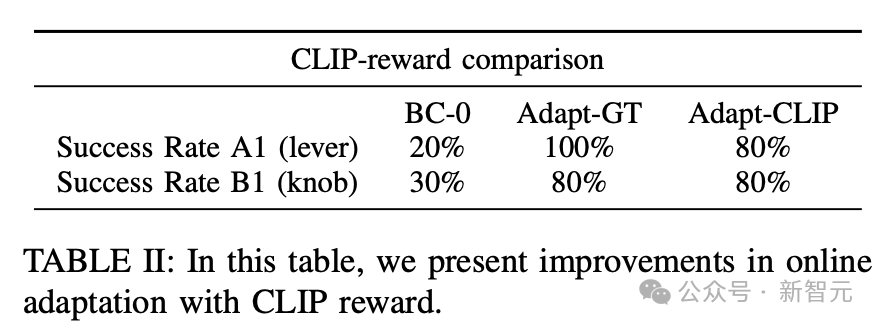
CMU團隊還研究是否可以通過自動程序來提供獎勵,從而取代人工操作。
正如Action-replay基線一樣,研究人員在兩個測試門上對此進行評估,每個門都從把手和旋鈕類別進行評估。
從表2中,使用VLM獎勵的在線自適應性能與使用人類標注的地面實況獎勵相近,平均為80%,而使用人類標注的獎勵則為90%。
另外,研究人員還在圖7中報告了每次訓練迭代后的性能。學習循環中不再需要人類操作員,這為自主訓練和改進提供了可能性。
為了成功操作各種門,機器人需要足夠堅固才能打開并穿過它們。
研究人員根據經驗與另一種流行的移動操縱系統進行比較,即Stretch RE1(Hello Robot)。
他們測試機器人由人類專家遠程操作,以打開不同類別的兩扇門的能力,特別是杠桿門和旋鈕門。每個物體都進行了5次試驗。
如表IV所示,這些試驗的結果揭示了Stretch RE1的一個重大局限性:即使由專家操作,其有效負載能力也不足以打開真正的門,而CMU提出的AI系統在所有試驗中都取得了成功。

總而言之,CMU團隊在這篇文章中提出了一個全棧系統,用于在開放世界中進行進行自適應學習,以操作各種鉸接式物體,例如門、冰箱、櫥柜和抽屜。
最新AI系統通過使用高度結構化的動作空間,能夠從很少的在線樣本中學習。通過一些訓練對象的演示數據集進一步構建探索空間。
CMU提出的方法能夠將來自4個不同對象類別中,8個不可見對象的性能提高約50%-95%。
值得一提的是,研究還發現這一系統還可以在無需人工干預的情況下通過VLM的獎勵進行學習。
作者介紹
Haoyu Xiong

Haoyu Xiong是CMU計算機科學學院機器人研究所的研究生研究員,專注于人工智能和機器人技術。他的導師是Deepak Pathak。
Russell Mendonca
Russell Mendonca是CMU大學機器人研究所的三年級博士生,導師是Deepak Pathak。他本人對機器學習、機器人學和計算機視覺中的問題非常感興趣。
之前,他曾畢業于加州大學伯克利分校電氣工程和計算機科學專業,并在伯克利人工智能實驗室(BAIR)與Sergey Levine教授一起研究強化學習。
Kenneth Shaw

Kenneth Shaw是卡內基梅隆大學機器人研究所的一年級博士生,導師同樣是Deepak Pathak。他的研究重點是,實現與人類一樣的機械手的靈巧操作。機械手應該如何設計成是何在我們的日常生活中應用?我們如何教機械手模仿人類?最后,我們如何使用模擬和大規模數據來解鎖新的靈巧操作行為?
Deepak Pathak
Deepak Pathak是卡內基梅隆大學計算機科學學院的助理教授,還是機器人研究所的成員。他的工作是人工智能,是計算機視覺、機器學習和機器人學的交匯點。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
