
AI計算面臨三大現狀,存算一體顛覆性重塑AI芯片。編輯 | GACS
9月14日~15日,2023全球AI芯片峰會(GACS 2023)在深圳南山圓滿舉行。在首日開幕式上,后摩智能聯合創始人、研發副總裁陳亮分享了題為《存算一體:顛覆性架構重塑AI芯片》的主題演講。陳亮談道,面向大模型時代的新需求,后模智能正計劃推出擴展大模型應用邊界的第二代天璇架構,以及基于這一整體性能、效率與靈活性更強架構的后摩鴻途H50芯片,預計在2024年正式推出。創立于2020年的后摩智能是存算一體芯片公司之一。公司于2023年5月正式推出存算一體智駕芯片后摩鴻途?H30,物理算力達到256TOPS,典型功耗達到35W。根據后摩實驗室及MLPerf公開測試結果,在ResNet50性能功耗對比上,采取12nm制程的H30相比某國際芯片巨頭的7nm同類芯片性能提升超2倍,功耗減少超50%。H30和H50系列背后是后摩智能自研的IPU架構,陳亮談道,該架構設計遵循“中庸之道”。如果將集中式計算架構比作居住面積和擴展性有限的“中式庭院”,那么分布式計算架構類似于“高層公寓”,容納性好但溝通性不足。后摩智能的IPU架構選擇在兩者之間尋求平衡點:在計算方面,通過多核、多硬件線程實現計算效率與算力靈活擴展;在存儲方面,通過多級數據緩存實現高效數據搬運與復用;在數據傳輸方面,通過雙環拓撲專用總線實現靈活數據傳輸與共享。以下為陳亮的演講實錄:尊敬的各位嘉賓、各位老師:大家下午好!后摩智能是一家做存算一體AI芯片的初創公司。我們在創業過程中,經常會被大家問到一個問題:既然存算一體技術優點這么多,那為什么國內或者國外的成熟大公司他們不做呢?我們的同事們也從不同的角度給出了一些解答。
01.AI計算面臨三大現狀,存算一體技術帶來新探索
從我的角度來看,我們希望從真正的客戶需求、產業的痛點,以及結合自身的特點出發,做出一些真正有意義、有價值的創新。我們看到AI計算的現狀:首先是算法對算力的要求越來越高,但是AI芯片的計算效率還不夠,這個效率包括了能效比和面效比,也就是單位功耗所能提供的算力和性能,以及單位面積能提供的性能。第二,系統的帶寬瓶頸會導致計算資源的利用效率降低,如何有效地利用帶寬,提高計算資源的利用效率,會成為更大的挑戰。第三,算法還遠未達到收斂的程度。各種各樣新的算法還層出不窮,雖然最近Transformer類的計算有一統江湖之勢,但是大家知道,真正端到端的AI計算所涉及到的計算范式還是非常豐富的。如何能夠在一個處理器內部完成端到端的AI計算,從而避免AI計算在不同的處理器核乃至不同芯片之間的數據傳輸,進而減少數據的搬運和存儲的開銷也是一個難題。基于此,我們希望借助獨特的存算一體技術,給大家帶來一些AI計算的不同探索。先簡單介紹一下我們公司,后摩智能是2020年底成立,2021年初正式運營。2021年8月,我們首款技術樣片完成了設計和流片,并且完成了首款量產產品的產品定義。2022年3月,我們的技術樣片回片跑通了自動駕駛的算法,完成了存算一體的技術驗證。同年10月,我們首款量產產品后摩鴻途?H30設計完成,進行投片,2023年5月發布了第一個量產產品,后摩鴻途?H30。這就是我們今年5月份發布的后摩鴻途?H30存算一體的大算力AI芯片,大家在外面展臺也可以看到它的實物,它的算力是256TOPS。這里面說的算力是物理算力,而不是稀疏化的算力,典型的功耗只有35W,這個功耗也是在跑實際算法過程中實測出來的。以上是對我們公司和產品的簡單介紹,下面從存算一體技術、AI處理器架構和軟件工具鏈這三個方面來介紹一下我們公司成立兩年多來的工作。
02.基于定制化電路結構,實現高效存內并行計算
首先介紹一下什么是存算一體。概念上講,存算一體就是在存儲單元的內部,完成部分或者全部的計算,它是解決芯片性能瓶頸,提高能效比的有效技術手段。大家知道,在AI計算過程中,大量的數據在存儲單元和計算單元之間交互,數據一行一行地從存儲器中讀取出來,送到計算單元中進行計算,再一行行地把結果寫到存儲單元當中。這樣做的話,訪存的功耗會急劇增加,并且會發生計算單元等待輸入數據的情況,從而降低了計算單元的利用效率。相比于卷積為主的神經網絡模型,以矩陣乘為主的Transformer類的計算,它的訪存和計算比例更大,這個問題會更加嚴重。這張圖就是我們存算一體電路的架構框圖。淺色的部分是標準的SRAM電路,深色的部分是我們在它旁邊加入了一些定制化的電路結構,包括Activation Driver、乘法器、加法樹和累加器等等。這些定制化的電路結構和傳統的SRAM電路整合在一起,就可以實現高效的存內并行計算。存儲單元內部的數據可以在同一時刻一起讀出,這相比于一行一行的讀取方式,極大地提高了并行性。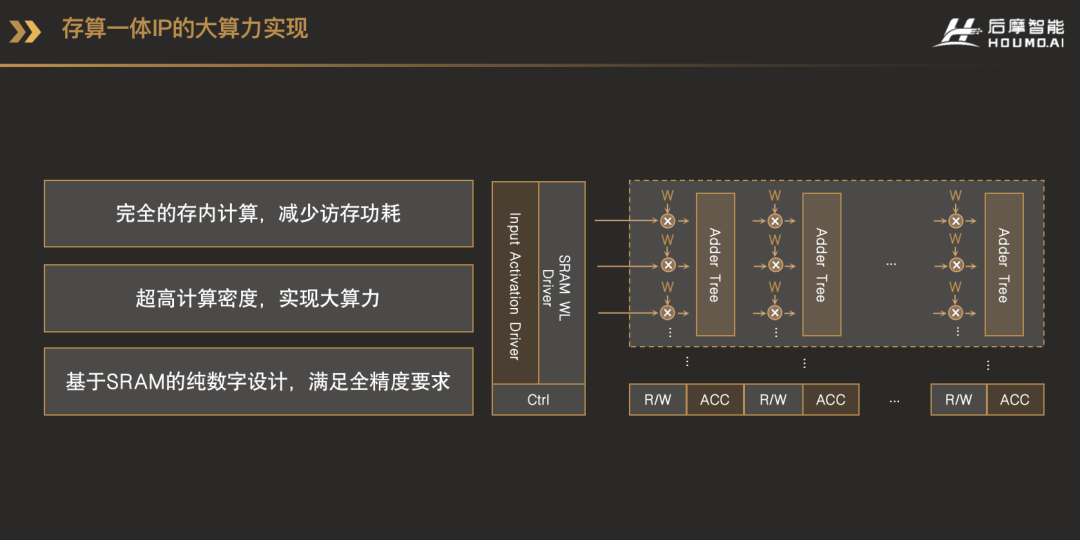
計算電路緊挨著存儲單元,數據被讀取出來之后,馬上就可以在原地參與乘加計算,數據在存儲單元和計算單元之間的傳輸開銷也就相應地減少了。計算單元方面,我們的定制化電路和存儲單元的Bit Cell(存儲單元)電路完全融合在一起,帶來了更規整的電路結構,因而有更緊湊的電路設計,電路面積也就相應減少了。這里面的定制化電路,不管是存儲電路,還是乘法、加法、累加等等,都是純數字的設計,不會有任何計算的誤差。因為我們面向的市場是自動駕駛,所以自然少不了車規方面的考慮,除了標準SRAM模式下的Memory BIST,我們還設計了用于計算模式的CIM BIST機制,CIM是Computing In Memory的首字母簡稱。我們還通過冗余設計,以及加入行和列修復電路,提高量產良率和可靠性。有了錯誤檢測機制和冗余設計,還可以在電路空閑時,通過軟件的方式檢測并修復電路中可能出現的錯誤。我們還改變了傳統SRAM中Bit Cell的電路,消除了6T Bit Cell里的競爭現象,進一步提高了可靠性和穩定性。這就是我們已經發布的后摩鴻途?H30芯片里所采用的存算一體電路的一些規格參數,采用的是12nm工藝,單個AI核內的存儲容量已經到了MB級別,在INT8全精度條件下能效比是30到150TOPS/W,30到150TOPS/W有一個范圍,是因為跟輸入數據相關的pattern 。面效比大于4TOPS每平方毫米,這是傳統電路的3倍以上。我們還支持軟硬件修復功能。目前我們已經在12nm、16nm、22nm、28nm工藝下進行過流片測試,7nm的測試樣片也已經流片,明年會推出量產產品。
03.自研IPU架構,探尋集中式與分布式計算的“中庸之道”
有了這么好的存算IP核,怎么把它充分利用好,就是考驗AI處理器架構和芯片設計能力的問題了。為此,后摩智能基于存算一體,專為萬物智能而設計了IPU(Intelligence Processing Unit),并規劃了三代IPU架構:第一代命名為天樞架構,專門為智能駕駛打造的;第二代天璇架構,可以覆蓋更多的場景,從成本、面積、功耗都非常敏感的終端場景,到自動駕駛,再到大模型等云端場景都可以覆蓋;第三代天璣架構的IPU,為通用人工智能打造的IPU。下面我將帶大家了解一下我們的IPU架構設計。首先是我們怎么思考AI處理器這件事的。在早期的時候,AI芯片通過堆積大量的計算資源,以提高并行性,從而提高性能。其典型的代表是左圖中特斯拉的FSD,采用集中式的存儲和計算架構,可以達到很好的性能提升。但是對于算力要求更大,靈活性要求更高的場景,如果只靠單純的堆砌更多的計算資源,到了一定程度后,由于物理實現的限制,或者輸入輸出數據的規模等方面的限制,計算資源的利用效率會急劇降低,因為單個任務計算并行性已經無法匹配計算資源的并行性了。我把集中式計算和存儲架構類似為建筑設計里面的中式庭院,向內圍合形成一個小院子,各種功能集于一身,使得人與人、人與自然可以高效地溝通,但問題是院落面積終究是有限的,能容納的居住者數量也就有限,而且設計建造這樣的庭院開銷和難度很大,因此可擴展性差。這時候一個自然的想法就是利用多核,或者硬件多線程的方式,如右中間的這個Tenstorrent Wormhole所示,這張圖和特斯拉的FST都出于一個人之手,這個人叫Jim Keller。他把算力很大的核拆成若干個小核。這樣做到極致,就是用眾多的CPU小核,在旁邊配上小塊的SRAM,組成一個二維陣列,業界也有人稱這種架構為“近存計算”。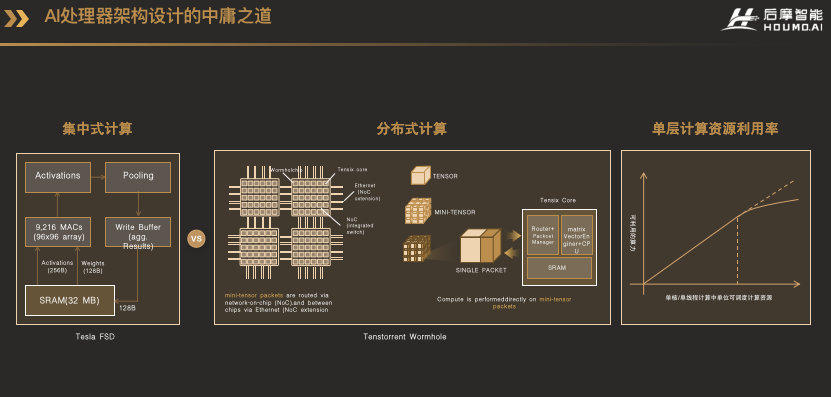
這樣做的好處是對物理實現非常友好,并且提供了非常靈活的編程性。但一個問題就是對于終端推理,尤其是自動駕駛這樣相對特定的應用場景,能效比和面效比比大核的形式差一些。這種分布式的計算和存儲結構,可以類比為建筑設計里面西方的高層公寓,采用獨立簡單的小單元,在三維空間上可以很好的擴展,能夠容納更多的人,但因為單元相對封閉,人和人之間的溝通就會比較差了。所以我們認為在單核或單線程可以調度的計算資源,與真實的可以利用的計算資源之間,存在一條Roofline的曲線關系。我們的設計邏輯就是找到這條Roofline曲線的拐點,當遇到拐點的時候,再通過多核或者多線程的方式來擴展算力。這樣的設計理念類似于融合了東西方建筑的特點,先設計一個簡單優美的庭院,再保障了計算資源利用效率的同時,再通過高層公寓的方式,在三維空間上靈活擴展算力。這張圖就是我們已經推出的H30芯片里天樞架構IPU的架構框圖。大家可以看到我們的芯片里有4個IPU核,都掛在系統總線NoC上,每個核是完全一樣的設計。每個核又由4個Tile組成,每個Tile就對應了一個硬件線程。在Tile內部,包括了一個CPU、Tensor Engine、Special Function Unit、Vector Processor和多通道DMA。其中Tensor Engine就是由我們的存算電路和一個Feature Buffer,還有相應的控制電路組成。這些計算單元全部在CPU的調度之下進行運行,CPU除了可以調度不同的計算單元之外,還可以進行一些簡單的靈活的,但是算力要求不高的計算。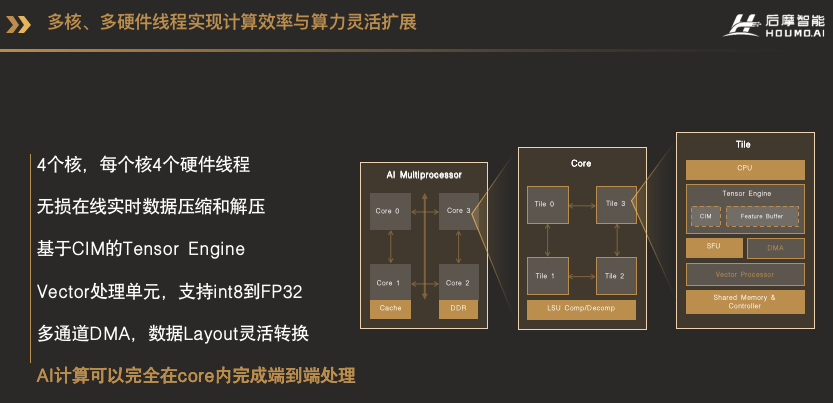
這樣的架構使得AI計算不但不用在多個處理器,例如CPU、GPU、DSP之間分配任務,甚至數據不用出AI核,就可以完成端到端的AI計算。從Memory Hierarchy的結構來看,整個系統包括了4級緩存,最外的緩存是片外的DDR,片內的第一級緩存我們叫L2緩存,是所有的CPU芯片都可以共享的緩存。L1的緩存就是Core內部一個共享存儲資源,Core內部所有的計算資源都可以共享這個Shared Memory。L0的緩存就是CIM,也就是存算單元。這四級的緩存都是可以被軟件分配和管理,這樣的設計使得軟件有更大的空間對不同類型的任務進行存儲空間的分配,從而減少數據搬運,并且更好地利用數據復用性。說過了存和算,這個架構里還有一個重要的部分就是數據的傳輸。就像我們人和人之間需要更好的溝通一樣,計算單元之間,也需要非常靈活的共享數據和消息。因此,我們設計了專用的數據傳輸總線,有了這個傳輸數據總線,就可以靈活的在各個Tile,以及各個Core之間建立高速的直接的數據傳輸通道,而不需要通過系統的總線和緩存了。通過自定義的總線,各Tile和各Core之間,可以非常靈活地組成不同的拓撲結構。我們的天樞架構IPU采用雙環的拓撲結構,四個Tile組成第一級的環,四個核又組成第二級的環。AI計算里數據復用是一個很重要的特性,利用數據的復用性可以減少片外帶寬的壓力。因此我們設計了多播的傳輸機制,也就是說一個Tile里的數據,可以通過一次DMA傳輸,廣播給需要這個Tile數據的所有的其他的Tile,而不需要多次重復地從同一個地址去讀取同樣的數據。多核加多播的傳輸機制,帶來的一個問題就是數據和消息的同步問題。例如Tile 0把數據傳給Tile1、2、3,然后四個Tile一起開始一次計算,這類的數據同步問題其實是多線程編程里面經常會遇到的問題。我們通過專用的消息傳遞通道和同步機制,可以讓四個Tile乃至四個核(Core)在收到消息的同一時間一起開始工作。大家看到,因為我們第一代IPU和H30芯片所用的核數和Tile的數量都比較少,14個,它形成了環形拓撲結構。但如果我們根據算力的需要,把這個核的力度切得更小,或者當算力需要更多的核的時候怎么辦呢?在這里提前預告一下我們下一代的天璇架構的IPU設計:基于Mesh互聯的AI Cluster,它可以將計算單元靈活的配置成M行N列,根據場景需求,AI算力規模可大可小。除了互聯拓撲外,存算電路CIM核的改進,我們自研的CPU和向量處理器的性能提升,針對AI算法更高效,尤其是大模型的計算,更加高效的SFU和數據傳輸機制,最終體現在更好的整體性能和靈活性。大家可以想象一下,如果這個二維陣列在二維空間甚至三維空間上繼續擴展下去,那么我們的芯片可以做些什么?總之,敬請期待。
04.提供2倍以上的真實算力,功耗可以降低50%
當然,H30 這樣一個大芯片,再加上純自研的存算一體電路,很多工程實現方面的挑戰需要解決,其中最關鍵的就是存算一體電路的特有驗證問題、仿真加速及FPGA原型問題以及電源完整性問題。為了實現大算力存算一體電路的仿真驗證,我們打造了一個存算電路的行為模型,使其與真實的電路的行為完全一致,也就是做Formal 驗證。這么大算力大規模的電路,加速仿真驗證也是一大考驗。我們單核的 IPU 規模就已經超過能找到的任何一款 FPGA 規模,所以我們團隊巧妙地將設計裁剪、分割 Partition 到多塊 FPGA。至于電源完整性的問題,大算力AI芯片需要考慮動態IR drop對性能的影響,特別是對于定制化存算電路,計算密度巨大,需處理IR drop問題及其對周邊電路的影響。我們采取多種方法降低峰值電流影響,因為存算電路與標準電路不同,無法按標準電路要求進行Sign-off。這是我們H30芯片的架構框圖和芯片規格。主要的規格參數包括256TOPS INT8精度的物理算力,DDR帶寬128GB/s,16路FHD的編解碼,8x PCIe4.0接口。典型功耗35W,采用12nm工藝。
我們通過底層的存算電路和AI處理器架構的創新,帶來性能指標上的突破。這是我們12nm芯片和某國際巨頭7nm芯片的性能和功耗對比,在同樣功耗下,我們的H30芯片可以提供2倍以上的真實算力,端到端的AI計算能力;在同樣的性能條件下,我們的功耗可以降低50%。上面講完了硬件架構設計,相當于我們的芯片有了一個強健的身體,下面介紹一下我們芯片的靈魂:編譯器和工具鏈。我們的芯片采用HDPL語言編程,即Houmo Data Parallel Language的縮寫,它是我們對主流并行編程模型的擴展,能高效的解決數據并行問題,并且支持消息傳遞機制。我們的Tile內部是由異構的計算單元組成的,采用SIMD的編程模型,而Tile間以及IPU核間是同構的,采用SIMT的編程模型。我們出色的軟件工具鏈工程師已經把剛才講到的Tile間和核間數據共享和消息傳輸的復雜機制都封裝了起來,用戶可以很容易地用我們的模型開發SDK,或者算子開發SDK,在我們的IPU上進行軟件和算法的開發。其中模型開發SDK允許用戶使用我們的算子庫進行模型和算法的開發。算子開發SDK則允許用戶開發自己的定制化算子。編譯優化方面,除了常用的不同計算單元之間可以以流水的方式并行以外,我們的每個Tile,以及每個Core之間,也可以獨立并行執行不同的任務,也可以將一個任務切分到不同的Tile,或者不同的核上,并且以Pipeline的形式并行。例如對CV類的處理,在追求Throughput,也就是高吞吐率的場景下,可以讓一張輸入圖片,同時進行多個網絡的計算,也可以讓多張圖片在多個Title或者多個核上,同時進行同一個網絡的計算。在追求低延時的場景下,可以將一張大圖拆成若干份,同時利用多個Tile,或者多個Core的算力進行計算。在2D Mesh的拓撲結構下,任務的流水線是在2維空間,甚至未來會在3維空間上進行流水,這也就是類似Spatial Computing(空間計算)的概念。H30芯片在一些現在最先進網絡已經有視頻效果呈現,包括激光雷達的一個處理網絡、BEV的網絡。我們的第一代量產產品后摩鴻途?H30現在已經可以提供給客戶送測了;第二代產品預計2024年可以提供給客戶。以上就是我分享的全部內容,謝謝大家!以上是陳亮演講內容的完整整理。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。

