
AI芯片大比拼或許在2024下半年。編輯 | GACS
9月14日~15日,2023全球AI芯片峰會(GACS 2023)在深圳南山圓滿舉行。在首日開幕式上,燧原科技創始人兼COO張亞林分享了題為《生成式人工智能的革命》的主題演講。張亞林談道,AIGC將持續帶動算力需求增長。參數量高達數千億的大模型,依賴分布式計算、更大的內存容量和帶寬、更高算力、更實惠的成本或性價比,對AI芯片生態提出更高要求。他打了一個形象的比喻:Transformer正通過統一的大模型,濃縮出一個“大樹型”的AIGC平臺生態,算力是“樹根”,大模型是“樹干”,行業模型庫是“樹枝”,應用是“樹葉”。相比原來碎片化的CV、NLP中小模型,大模型的“大樹型”生態的算力需求更加明確和聚焦。對此,他倡導聯合生態伙伴,通過統一的大模型技術生態棧解決算力瓶頸問題。如何針對統一的大模型技術生態棧進行加速?張亞林認為,支持大模型需求,AI芯片廠商需要“芯片硬件+軟件”雙管齊下。“不能僅定位于AI芯片本身,而是從硬件、軟件、系統、方案整體賦能一個數據中心或客戶。這一高抽象的四大層次需要有緊密的生態伙伴一起加持,達到一個統一生態棧來解決算力瓶頸問題。”為此,燧原科技推出的智算2.0,從基礎大模型和垂類大模型兩個方面進行探索。在基礎大模型訓練方面,其強調更高的性能,以及算力集群化催生創新前瞻性;面向垂類大模型,則以算力性價比推進產業規模化。目前,其已為大型科技機構打造千卡規模AI訓練算力集群,并與大型互聯網公司合作打磨技術。在方案方面,燧原科技還推出了大模型應用平臺——燧原曜圖,希望通過系統化產品的更具象方式以觸達更多客戶。從AI芯片商業化來說,所有產品發布都要擬合時間點和節奏。張亞林預測,2023年將是大模型預訓練元年,2024年可能是大模型部署元年,2025年則是大模型真正成熟的元年。很多人認為今年中國這一波大模型訓練已經結束,而實際上當2024年數據飛輪轉起來,勢必要重構大模型訓練,誰能在明年下半年提供更有價值的預訓練產品,變得十分關鍵。以下為張亞林的演講實錄:各位朋友,大家好!很榮幸站在這里跟大家分享我們燧原對生成式人工智能革命的一些理解。今天我的分享分為基本介紹、市場分析、生態和計算范式的變革、系統戰略四部分。
01.面向AIGC萬億級市場,百模大戰帶動算力需求爆發
這是我們看到的AIGC未來預測,生成式的模型橫跨了文本生成、音頻生成、圖像生成、視頻生成、跨模態生成、策略生成、Game AI、虛擬人生成等。下面這張圖是2020年到2030年十年間以及更遠,我們大概可以看到的文本生成、代碼生成、圖片生成、視頻3D生成、游戲AI的發展路徑。
據我們看到的情況,現在真正能夠實現商業化或者已經有了商業價值的,還是在圖像生成部分。我們看到的很多媒體公司、廣告公司、電商以及游戲公司,已經利用了文本生成圖像的方式,實現了一些商業價值的變現、用戶體驗的增長。緊接著我們看到的就是代碼生成和文本生成,很多大語言訓練模型都在各地開花,代碼生成也成為了大語言模型的一部分。所以我們預計,到今年底或明年,會有一波大語言模型,以文字生成文字或者文字生成代碼的方式落地。再進一步,可能到了明年,我們會看到一些文字生成視頻和3D的文生視頻的雛形。現在已經有大概一分鐘的(文字生成)短視頻出現,明年預計會有更高質量、更長時間的視頻生成出現。游戲AI會變得更加智能化,決策、智能化會隨著AI的方式變得更加豐富。所以在很多的游戲公司也在嘗試用生成式AI,調整AI的智慧大腦。這是一個簡單的AIGC市場規模預測,我們截取了一個智庫的說法:在2023年整個AIGC市場規模將達170億人民幣,預測到十年之后或者2030年底將達到萬億級別。這個預測是非常瘋狂的,基本七到八年要實現大幾十倍,甚至一百倍的增長。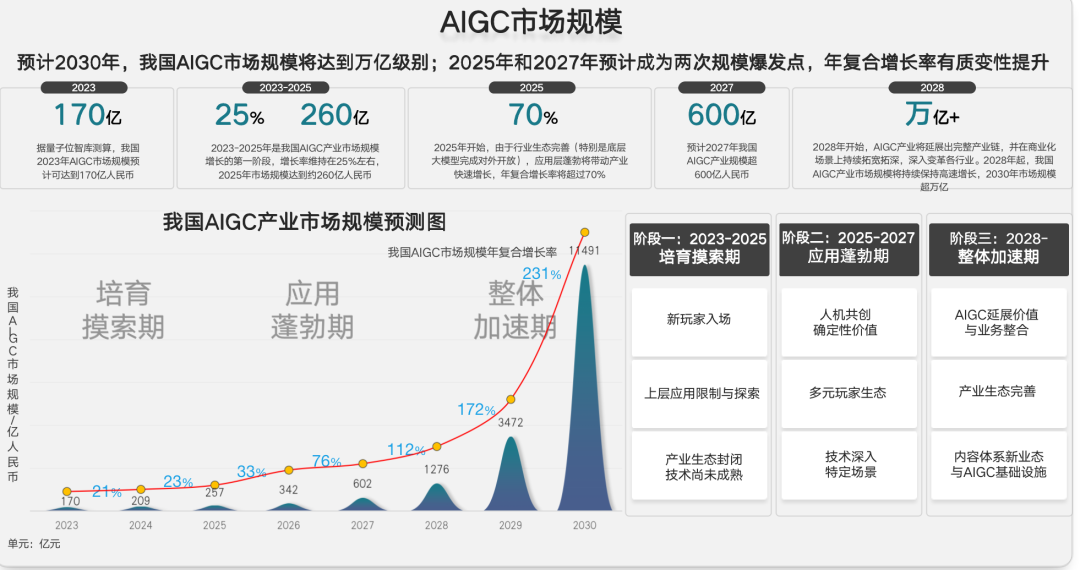
整個增長分成三個部分:2023到2025年是起勢階段,這兩年生成式AI還在進行算法、部署、商業模式一系列的探索;到2025年到2028年是生態的成熟期,開始進入各行各業,產生一些真正更大規模的商業價值;2028到2030年是井噴,生態爆發,進入所有人的生活。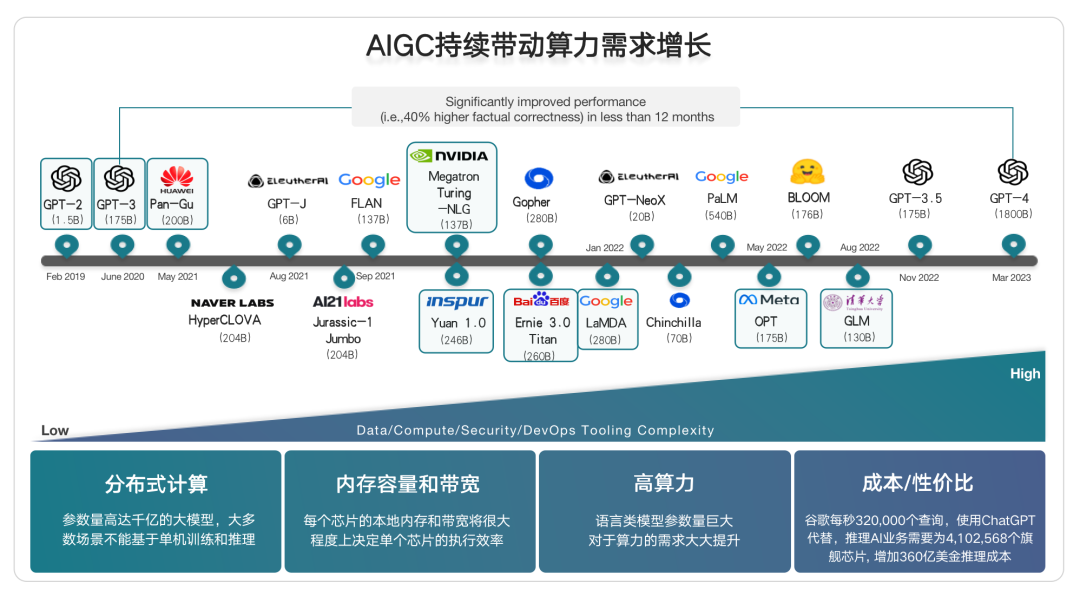
大模型的訓練依賴于分布式計算、內存容量和帶寬不停地增加、更好的算力,同時更多算力精度的表達,還有非常可觀的成本和性價比,直接決定了大模型的應用和部署。
02.大模型引發計算范式變革,帶來“大樹型”生態格局
這張圖是樹狀圖,描述了基于Transformer的統一大模型新的生態格局。原來我們在各行各業面對的模型是比較碎片化的,我們原來看到的模型是非常碎片化的模型。Transformer目前被認為是第一個統一大模型,以它的模型底座構建的生態會成為樹狀的結構。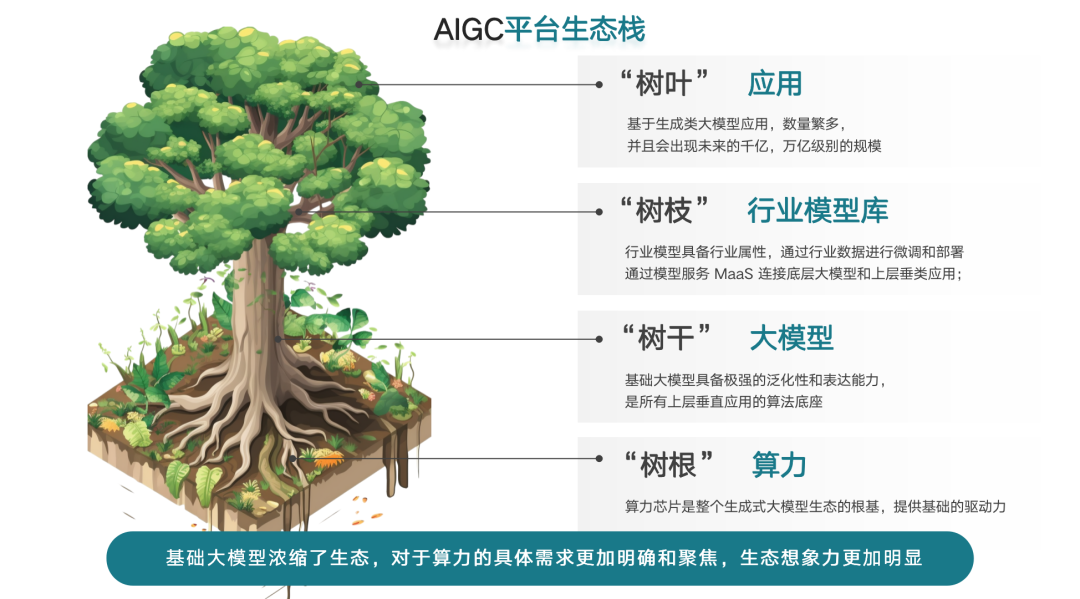
這個樹狀的結構從底下的樹根算力支持,就是剛才提到的底下的集群、互聯,各種各樣的底層軟件棧和軟件系統,到上層對于統一大樹干和多模態的支持,再到上面各行業垂類的模型,基于大模型生長出來能夠觸達千行百業的垂類模型,再到基于垂類模型生長出的枝葉,就是所謂的應用。這樣一種大樹的結構,是使得我們現在面臨的問題不再是跟樹林的小樹苗做生態的連接,更多是整個算力全棧,如何更好地支撐大模型為基礎的樹狀發展,以及在上面如何開枝散葉,變成更多的行業應用。這是我們現在看到的五層的MaaS結構——Model as a Service是一種在云體系里面的新提法,跟傳統的IaaS、SaaS、PaaS有區別,它主要是基于模型即服務的概念。也就是說,它的生態棧基本上是五層的構建棧,從底下的算力提供商、算力系統,以及更大的算力集群,通常成為算力底座的提供商,到上面的云服務商,以騰訊云、阿里云、百度云等一系列為代表的云服務商,對上提供抽象的云服務組件,然后在上面增長出通用基礎大模型。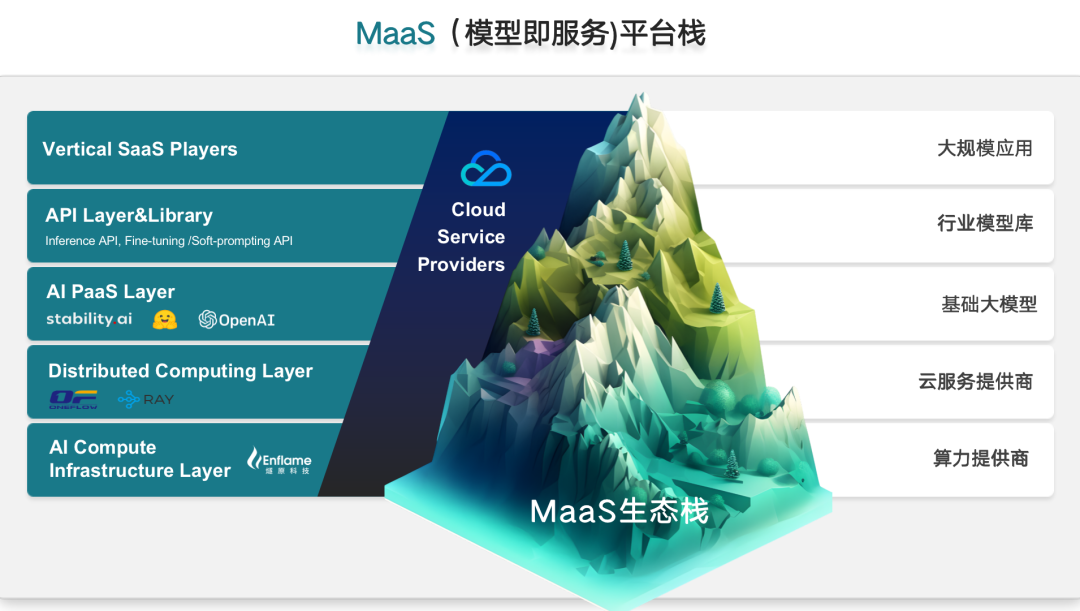
這些大模型有開源的也有閉源的,但它是通用基礎類的,然后在上面生長出行業的模型庫,基于這種通用大模型進行微調精調,和一些行業數據的加入,生長出來行業模型庫,再到上面根據行業模型庫,所有的應用廠商和客戶端來進行調用,并且進行開發自己的應用。在這五層模型里面,很多的公司都有自己的定位:云服務公司既提供云服務,也提供MaaS,去支撐自己匯聚的大模型通用庫,來服務更多的垂類模型和用戶;有一些做通用模型的公司,他們既做基礎類的大模型,也嘗試做垂類大模型,甚至還有一些模型公司也有自己的應用,所以他們也跨在不同的層次上。但不管怎么說,這五層是從底下的算力系統能夠觸達到整個大面積的應用客戶之間的五層體系結構,它本身把整個用戶的方式變得更加高層。也就是今天我作為一個用戶開發者,在頂層根本不太需要知道底層的算力系統,只要知道行業模型庫的調用、付費、效用是否能達到我的需求。所以,這樣一個高抽象的結構,讓整個AIGC能走入更多的用戶,整個界面也變得更加單純和抽象。
03.MaaS服務模式下,底層芯片差別在用戶端被屏蔽
這是我們在中國的數據中心或者新的數據中心看到的“L”型生態。我們一直在講中國在做大規模的計算中心建設,這個計算中心的建設就是一個數據中心的技術棧和數據中心的產業鏈。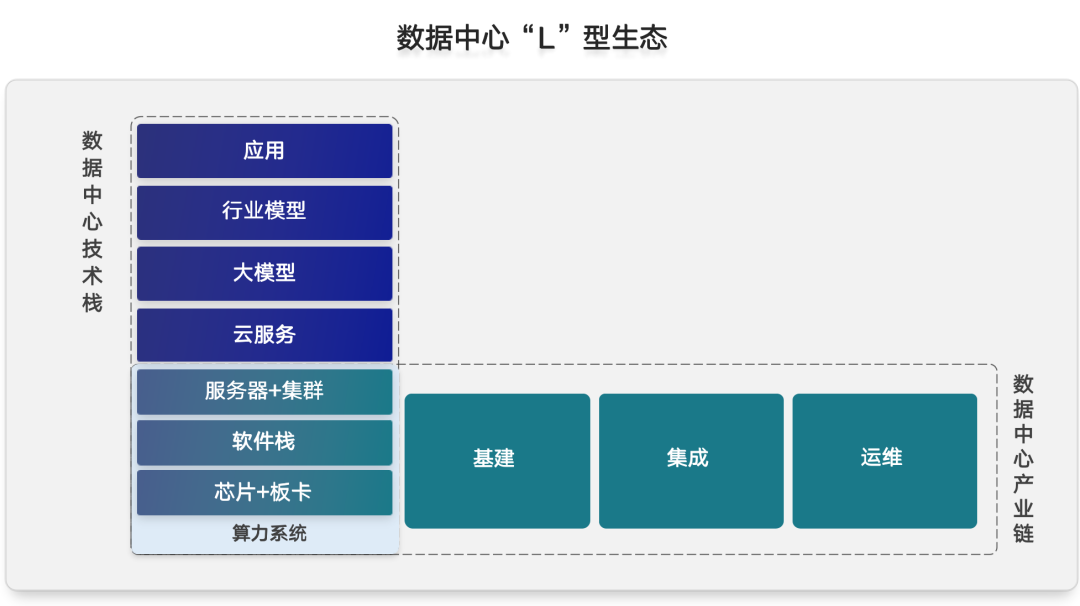
這個“L”型的結構的Y軸,是五層的技術棧結構,它包括了底下的算力系統:芯片、板卡、軟件棧、服務器集群,上面是云服務大模型、行業模型和應用。這個L型的軟件棧的Y軸,決定的是算力的部署和算力的利用,到底有沒有消納方,有沒有生態的伙伴來消納這個東西。“L”型生態的X軸,決定了作為算力系統提供商能不能跟基建、集成、部署、運維這些生態方在一起,能經過三五年的運營,進入正常的階段。所以在這樣的圖里面,如果我們真正落一個計算中心,或者說一個東數西算工程中的新基建,必須具備“L”型的拼盤,而不是簡單地只是做算力的提供方,沒有算力的消納方,或者沒有算力的運維方。這樣完整的拼盤把整個中國計算中心的業態擴大了,它需要一個更開源開放式的生態聯盟,來做這樣一件事情,最終把在中國的計算中心的生態拼盤真正落實。不然的話,缺少任何一個軸,里面的數據中心都會用不起來,或者運維不起來,或者出現沒有需求方這樣的問題。這是我們看到的一些趨勢,隨著算力集群和AI芯片在整個芯片系統作為底座,很多軟件框架包括加速庫、AI的框架等,我們在上面又加了分布式的框架,這個分布式的框架以更抽象的方式,能夠讓更多大模型的編程者可以更好地使用各種模型變形、數據變形等變形策略,能更好地調用底下更大規模的算力。
這種分布式的框架已經成為了一個更高抽象的代表,在它上面構建出所有的大模型、行業模型、大規模應用,也就是MaaS棧。在這樣的情況下,底下的算力越來越海量,但上面的編程越來越海量,當我作為一個大模型的編程者,我要使用的算力本身,已經不再像以前這么具象了,不只是面對一張卡一個芯片這樣的方式,以什么樣的抽象方式更好地真正地使能編程。所以它從底下來看,從芯片到集群,本身就是一個大的系統抽象。因為很多的編程者根本不太關心芯片的實際指標,只關心作為一個集群的呈現,能提供什么樣的價值。所以從系統化來看,本身就是在往上抽象的。另外,Transformer的出現,讓更好的部署和微調變得更加專注。以前可能要面對千行百業不同種類的模型,現在開始變得更加聚焦、匯聚,如何針對統一大模型以及統一大模型上面的垂直模型進行專門的加速,能夠讓它變得更加高性價比。整個編程在往上移動,平臺在往上抽象,所以一切的一切都在從底下的芯片往更高層次用戶觸達。同時基礎大模型的更新并不像以前的中小模型一樣更新迭代非常快。大家看到ChatGPT至少有半年甚至更長時間更新一次,所以這種更新迭代的過程中,遷移的東西怎么樣能夠更好地匹配它的開發周期,在更大的開發尺度上,怎么樣讓它變得更有效,而不是像原來的中小模型一樣,兩三周甚至一個月迭代一次,這也變成非常大的挑戰。所以我們想表達的是,系統的高抽象、更高編程的層次和框架,以及更大規模用戶的觸達,以及系統性上更高的復雜度,讓大模型真正能夠被產生和訓練,這在更大程度上增加了在AIGC技術上的壁壘和生態的難度。再講到L型生態,整個AIGC其實是給整個業內生態布局和更大規模的開源開放,創造了一個大的可能。
04.芯片硬件+軟件雙管齊下,燧原試水文生圖AIGC平臺
對于我們燧原科技來說,在2.0里面把生態分成了兩個部分:一個是以預訓練為代表的大集群、大模型,高互聯、大帶寬這樣一種方式,我們叫Pre-train,它是大模型的產生。但在右邊我們會看到,當統一大模型變成垂類大模型進入千行百業,甚至賦能更多用戶應用的時候,它其實是通過微調Fine-tune或者Prompt-tune以及推理的部署來做到的,所以在右邊我們更強調極致性價比,在左邊強調的是更高性能、更好的前瞻性。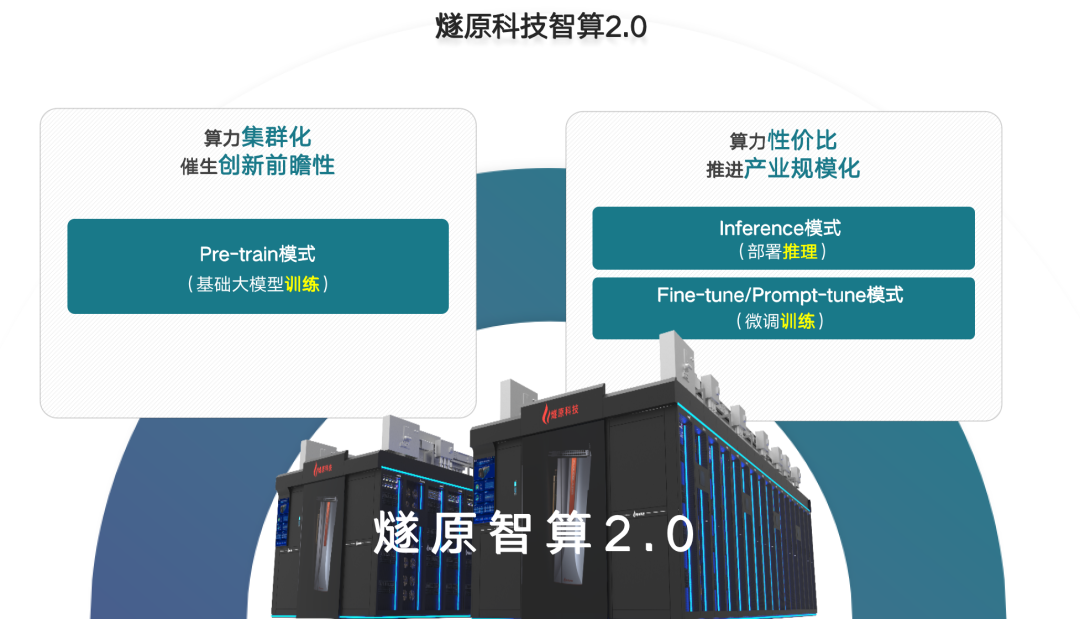
目前為止我們看了很多的商業模式,大語言模型在真正實現商業化的路徑上還有很多的挑戰。OpenAI都還沒有賺錢,那誰愿意為它付費?怎么讓大語言模型真正能夠實現商業的正向價值?這個其實跟右邊的部署系統和生態極其相關,而所有的用戶看重的就是能不能把你的部署性價比拉到極限。而極限每在性價比上增加一步,在整個大規模的部署上省的錢就更加可觀,這是我們看到業內非常明顯的點。我們現在在中國已經推出了這樣的集群系統來賦能,當然這個生態需要一定的建立,所以選擇一些國家的實驗室、國央企,來作為更好的推動力和訓練上更好的試水,是整個生態成長的必要階段。同時,跟大的互聯網戰略客戶進行完全匹配部署,是我們在推理和部署上非常關鍵的抓手。因為大的互聯網公司戰略客戶,它會在所有真正的內容理解、智能交互、智能會議、推薦搜索、大模型的應用,包括游戲等場景。他們會極致關注性價比,要求你做到跟競爭對手更好的性價比,他才會進行試用。所以跟大的互聯網客戶進行極致打磨,把性價比做上去,這也是符合大模型未來部署市場里面非常關鍵的點。同樣在中國的計算中心里面,我們如何能夠在中國計算中心里面有這樣的落地抓手,能夠保證我們剛才講的“L”型生態,包括數據中心的業態能更好地建立,這也需要我們的最佳實踐,保證這個業態在生態上很好的抓手。所以一個以前定位AI芯片的公司,在AIGC的風潮里面,肯定不能只定位在AI芯片的本身,這離我們剛才講的用戶更大的生態、更高的抽象離得太遠。這樣一個金字塔的結構,必須得是從底下的軟件、硬件,各種各樣的裸金屬底座,到整個軟件;我們剛才講了所有分布式的大模型支撐、各種內存、計算的優化,還有各種大模型的部署;然后再在系統層面對業務,端到端進行部署,最后才是整合整體的方案,整體賦能,一個大的數據中心或者一個大的客戶。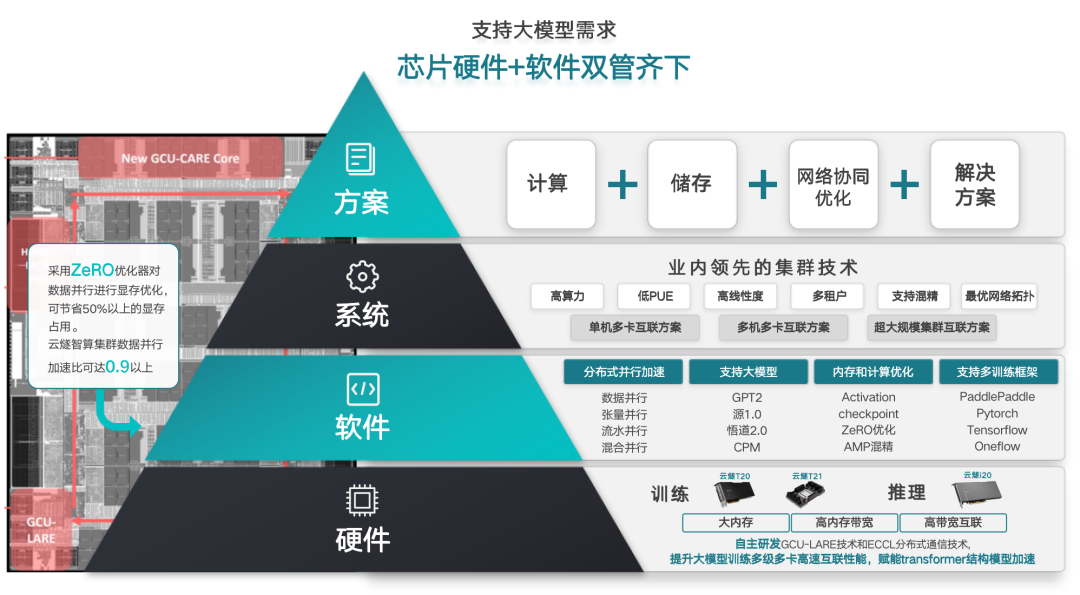
所以從硬件、軟件、系統、方案這么高的四個層次,需要有一些非常緊密的生態伙伴一起加持這個事情,然后達到真正通過統一棧,幫助中國解決算力瓶頸的問題。這是我們在今年兩個月前發布的曜圖,這是一個文生圖的平臺,我們緊接著會有一個文生文的平臺發布,做這個平臺的目的就是為了讓燧原的系統化和方案的能力直接通過這個產品的展示,直接觸達高層用戶。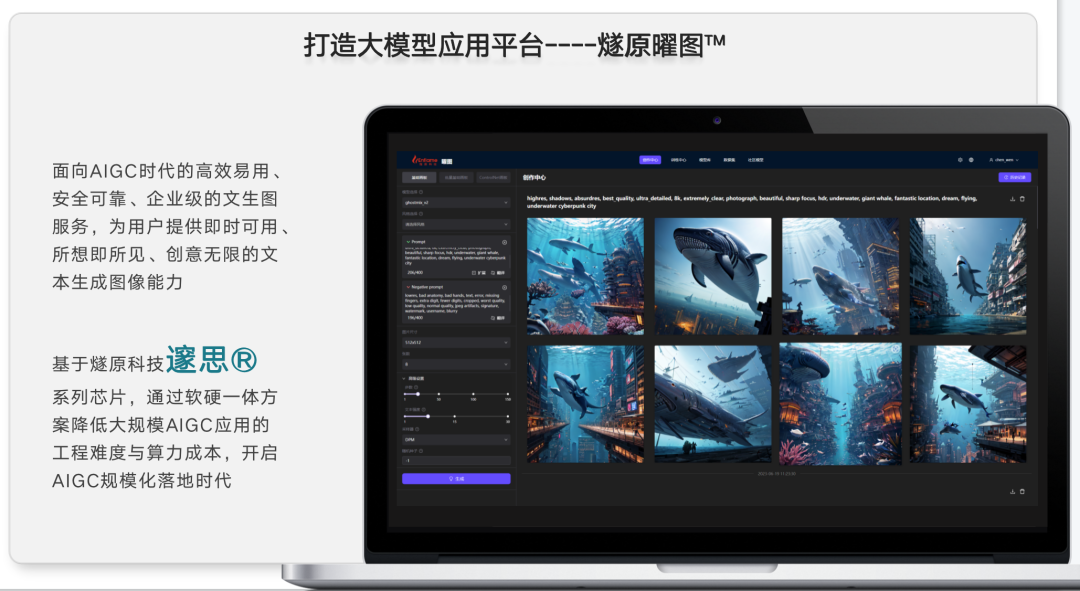
因為如果你定位是一個芯片公司或者是一個硬件提供商,你很難通過一種具像的方式去跟應用方、模型方聊,而這樣的一種系統化產品的搭建,讓你輕易地以產品原型的方式去觸達更多的客戶,這種方式本身就是擬合了文生圖,能夠在燧原所有的全棧軟硬件里面直接體現它的價值。當然它最終落地在商業化的時候,一定要跟行業或者跟生態伙伴進行結合,但它的方式可以讓我們很快地觸達到更多抽象的客戶,能夠讓客戶用比較簡單輸入的語言來理解你的產品,來實現你的產品價值。
05.AI芯片大比拼或在2024下半年
最后這張是我們的產品節奏。所有產品的發布和生態的建立,都必須得擬合時間點和節奏。在對的時間點出來一個錯誤的產品,那是完全不符合市場需求的。所以我們從2022年把模型分成了LLM和多模態,這兩條線看上去現在情況差不多。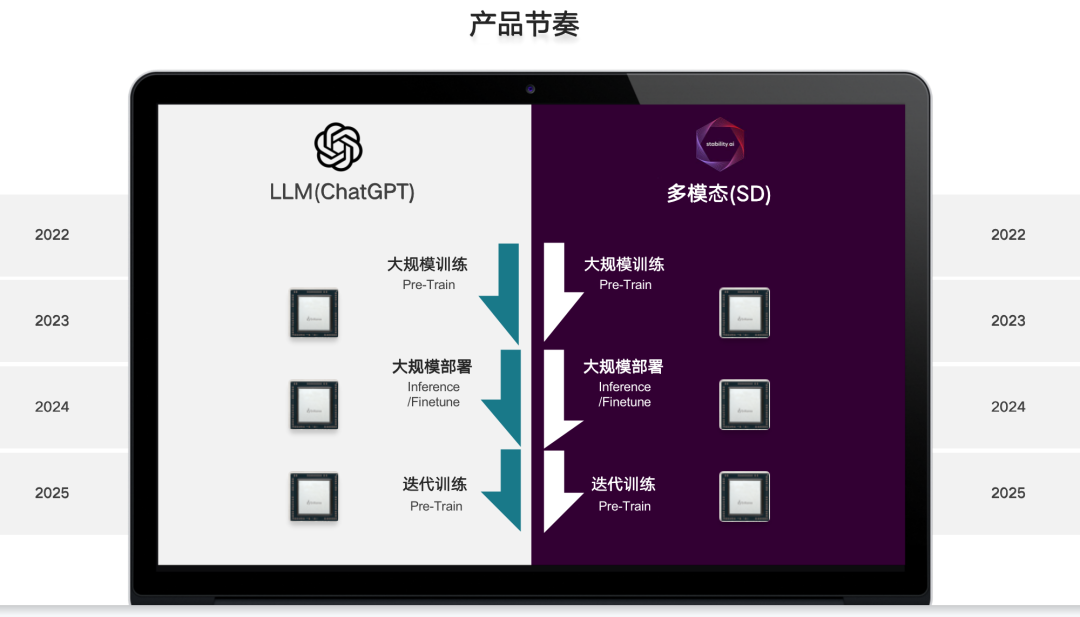
我們在2022年是剛剛啟動的階段,包括年底的ChatGPT。2023年在中國我們稱之為大模型訓練的元年,所謂的百模大戰、千模大戰都會用非常高端的訓練卡,用最快的時間,把整個大語言模型和多模態模型訓練出來,搶時間,然后更好地建立自己的護城河。但是到了現在,基本上所有的看法都認為,中國的第一波大訓練已經結束了,如果現在才進入這個局面已經沒有機會了。現在不管是從大的互聯網公司還是從比較大型的初創公司,還是從媒體類公司,都進入了一個新的階段,就是怎么樣把我訓練的模型進行商業變現,花了這么多錢,怎么體現商業價值,讓企業獲益,這是所有人面臨的終極問題。這也是為什么文生文還在這個階段中,怎么樣商業變現,但文生圖已經實現了商業價值,已經有很多上市公司因為它而賺到了第一桶金。所以今年年底,誰能真正幫助大模型去部署,去推理,同時打造極致性價比,這樣的事情會在明年真正使能大模型更大規模的部署,所以明年我們認為是大模型的部署元年。明年也會有更多更有趣的大模型商業模式出現,包括剛才講的訂閱式方式收費,這也是大模型以前的時代沒有經歷過的。所以在明年大模型的部署元年開始之后,我們可以再想象一下,當數據的飛輪重新轉起來,所有的大模型以及應用開始收到用戶大量數據,勢必在明年下半年要開始重構他的訓練,所以我們叫它再訓練。這樣的數據飛輪轉起來之后,誰能在明年的下半年提供真正更有性價比,或者更高性能,或者幫助用戶的預訓練產品,能把大模型2.0時代真正推動起來,把數據的迭代轉起來,又變得更加關鍵。2023年,我們認為是大模型的預訓練元年;2024年,我們認為是大模型的商業部署元年;2025年,我們認為是大模型2.0真正成熟的元年。所以如果各位的產品也好,整個市場的需求也好,是放在這里的。以極致部署的性價比,更好的算力和系統的彈性化,能夠使能大模型的2.0,這被認為是未來發展的關鍵。我的演講就到這里,我最后想說的是:我認為這是開天辟地的時代,這是第四次工業革命的核心,讓我們進一步地向AIGC靠近,也希望跟各位業內專家伙伴一起打造AIGC的生態,不負這個時代,一起幫助中國把這個算力支撐起來。謝謝大家!以上是張亞林演講內容的完整整理。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。






