Pandas數(shù)據(jù)清理
 加入技術(shù)交流群
加入技術(shù)交流群

掃碼加入
和技術(shù)大咖面對(duì)面交流
海量資料庫(kù)查詢(xún)
推薦:使用NSDT場(chǎng)景編輯器快速搭建3D應(yīng)用場(chǎng)景介紹
如果您喜歡數(shù)據(jù)科學(xué),那么數(shù)據(jù)清理對(duì)您來(lái)說(shuō)可能聽(tīng)起來(lái)像是一個(gè)熟悉的術(shù)語(yǔ)。如果沒(méi)有,讓我向你解釋一下。我們的數(shù)據(jù)通常來(lái)自多個(gè)資源,并不干凈。它可能包含缺失值、重復(fù)項(xiàng)、錯(cuò)誤或不需要的格式等。對(duì)這些混亂的數(shù)據(jù)運(yùn)行實(shí)驗(yàn)會(huì)導(dǎo)致不正確的結(jié)果。因此,有必要在將數(shù)據(jù)饋送到模型之前準(zhǔn)備數(shù)據(jù)。通過(guò)識(shí)別和解決潛在的錯(cuò)誤、不準(zhǔn)確和不一致來(lái)準(zhǔn)備數(shù)據(jù)稱(chēng)為數(shù)據(jù)清理。
在本教程中,我將引導(dǎo)您完成使用 Pandas 清理數(shù)據(jù)的過(guò)程。
數(shù)據(jù)我將使用著名的鳶尾花數(shù)據(jù)集。鳶尾花數(shù)據(jù)集包含三種鳶尾花的四個(gè)特征的測(cè)量值:萼片長(zhǎng)度、萼片寬度、花瓣長(zhǎng)度和花瓣寬度。我們將使用以下庫(kù):
pandas: 用于數(shù)據(jù)操作和分析的強(qiáng)大庫(kù)
Scikit-learn: 提供用于數(shù)據(jù)預(yù)處理和機(jī)器學(xué)習(xí)的工具
使用 Pandas 的 read_csv() 函數(shù)加載鳶尾花數(shù)據(jù)集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()輸出:
| 編號(hào) | sepal_length | sepal_width | petal_length | petal_width | 物種 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 鳶尾花 |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | 鳶尾花 |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | 鳶尾花 |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | 鳶尾花 |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | 鳶尾花 |
header=0 參數(shù)指示 CSV 文件的第一行包含列名(標(biāo)題)。
2. 瀏覽數(shù)據(jù)集為了深入了解我們的數(shù)據(jù)集,我們將使用 pandas 中的內(nèi)置函數(shù)打印一些基本信息
print(iris_data.info()) print(iris_data.describe())
輸出:
RangeIndex: 150 entries, 0 to 149 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 150 non-null int64 1 sepal_length 150 non-null float64 2 sepal_width 150 non-null float64 3 petal_length 150 non-null float64 4 petal_width 150 non-null float64 5 species 150 non-null object dtypes: float64(4), int64(1), object(1) memory usage: 7.2+ KB None
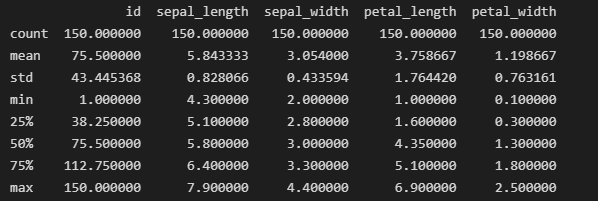
iris_data.describe() 的輸出
info() 函數(shù)可用于了解數(shù)據(jù)幀的整體結(jié)構(gòu)、每列中非空值的數(shù)量以及內(nèi)存使用情況。而匯總統(tǒng)計(jì)數(shù)據(jù)則提供了數(shù)據(jù)集中數(shù)值要素的概述。
3. 檢查類(lèi)分布這是了解類(lèi)如何在分類(lèi)列中分布的重要步驟,這是分類(lèi)的重要任務(wù)。您可以使用 pandas 中的 value_counts() 函數(shù)執(zhí)行此步驟。
print(iris_data['species'].value_counts())
輸出:
Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 Name: species, dtype: int64
我們的結(jié)果表明,數(shù)據(jù)集是平衡的,每個(gè)物種的表示數(shù)量相等。這為所有 3 個(gè)班級(jí)的公平評(píng)估和比較奠定了基礎(chǔ)。
4. 刪除缺失值由于從 info() 方法中可以明顯看出我們有 5 列沒(méi)有缺失值,因此我們將跳過(guò)此步驟。但是,如果遇到任何缺失值,請(qǐng)使用以下命令來(lái)處理它們:
iris_data.dropna(inplace=True)5. 刪除重復(fù)項(xiàng)
重復(fù)項(xiàng)可能會(huì)扭曲我們的分析,因此我們會(huì)將它們從數(shù)據(jù)集中刪除。我們將首先使用下面提到的命令檢查它們的存在:
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())輸出:
Number of duplicate rows: 0
此數(shù)據(jù)集沒(méi)有任何重復(fù)項(xiàng)。盡管如此,可以通過(guò) drop_duplicates() 函數(shù)刪除重復(fù)項(xiàng)。
iris_data.drop_duplicates(inplace=True)6. 獨(dú)熱編碼
對(duì)于分類(lèi)分析,我們將對(duì)物種列執(zhí)行獨(dú)熱編碼。執(zhí)行此步驟是由于機(jī)器學(xué)習(xí)算法傾向于更好地處理數(shù)值數(shù)據(jù)。獨(dú)熱編碼過(guò)程將分類(lèi)變量轉(zhuǎn)換為二進(jìn)制(0 或 1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)
圖片來(lái)源:作者
歸一化是將數(shù)值特征縮放為平均值為 0 且標(biāo)準(zhǔn)差為 1 的過(guò)程。執(zhí)行此過(guò)程是為了確保要素對(duì)分析的貢獻(xiàn)相同。我們將規(guī)范化浮點(diǎn)值列以實(shí)現(xiàn)一致的縮放。
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] scaled_data = scaler.fit(iris_data[cols_to_normalize]) iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
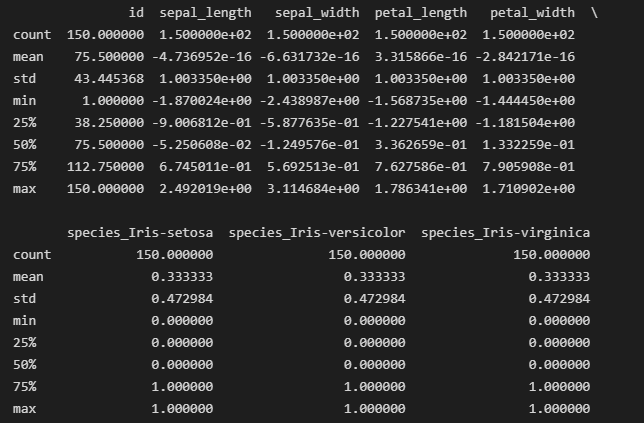
規(guī)范化
后 iris_data.describe() 的輸出
將清理后的數(shù)據(jù)集保存到新的 CSV 文件。
iris_data.to_csv('cleaned_iris.csv', index=False)總結(jié)祝賀!您已成功使用 pandas 清理了第一個(gè)數(shù)據(jù)集。在處理復(fù)雜數(shù)據(jù)集時(shí),您可能會(huì)遇到其他挑戰(zhàn)。但是,此處提到的基本技術(shù)將幫助您入門(mén)并準(zhǔn)備數(shù)據(jù)以進(jìn)行分析。
原文鏈接:Pandas數(shù)據(jù)清理 (mvrlink.com)
*博客內(nèi)容為網(wǎng)友個(gè)人發(fā)布,僅代表博主個(gè)人觀(guān)點(diǎn),如有侵權(quán)請(qǐng)聯(lián)系工作人員刪除。