康奈爾中國博士生打造AI聲吶眼鏡,能連續識別31條無聲語音指令,主要成本不超過400元

 圖 | 圖中張瑞東佩戴的眼鏡就是 EchoSpeech 設備(來源:Photo Courtesy of Dave Burbank)EchoSpeech 是一款新型可穿戴無聲語音識別系統 ,它可以連續識別 31 條無聲語音指令,準確率達到 95%,最高電池續航時間約 10 小時。其中,傳感器成本不超過 100 元,單片機處理器成本 300 元左右。00:29(來源:ACM)無聲語音指的是只動嘴、而聲帶不發聲的說話方式,有些類似于耳語(不嚴格區分的話,耳語也可以算作無聲語音)。不過,耳語本身必須發出一些聲音,而無聲語音則無需發出任何聲音。正在閱讀這篇文章的你可以嘗試一下耳語,但是不要送出氣流,這樣幾乎不會發出任何聲音,而嘴唇和舌頭依然會動。對于公眾來說,無聲語音可能仍然是一個新鮮事物。但是,大家在日常中或多或少都會接觸到。比如,開會時和別人交流時的耳語。相比有聲語音來說,無聲語音最大的優勢就是“無聲”。在一些安靜的場合,比如圖書館、會議中等,出聲地說話是不合適的;另外,在特別嘈雜的環境中,語音交流也會容易受到噪聲的影響。在這種情況之下,都可以使用耳語。而對于聲帶損傷者或殘疾人士來說,無聲語音可能是最接近語音交流的唯一選擇。在這個意義上,關于無聲語音的相關應用具備很大的潛力。09:30(來源:ACM)對于無聲語音識別這項技術,已經有很多課題組在研究。最成熟、最流行的是依靠計算機視覺的方案:即使用相機直接捕捉面部運動尤其是嘴唇的運動。這種方法的缺點十分明顯:它必須在用戶面前放置相機,而這就涉及到普適性、功耗、隱私等問題。也正因此,目前面向可穿戴領域的解決方案多數還不成熟,在穿戴舒適度、功耗、系統等方面依舊欠佳。例如,在多支團隊的研究成果中,都需要在口腔內放置傳感器來追蹤舌頭運動。絕大多數方案只能識別說得比較清晰、語速較慢的離散指令,例如能識別單獨說出來的、中間有暫停的 1-2-3,但是無法識別連續說出來的 123。而張瑞東所在團隊研發的 EchoSpeech,在穿戴舒適度和連續識別上有著明顯優勢。在 EchoSpeech 的設計中,傳感器即小揚聲器的麥克風,被安裝在眼鏡框的下邊緣。這時,通過采用聲波感知技術,就能探測面部運動尤其嘴唇的運動,并以此來識別無聲語音。與同類成果相比,EchoSpeech 具有體積小、佩戴舒適、功耗低、隱私保護好等優勢。同時,在識別連續詞組/句子的能力上,EchoSpeech 也有著很大提升。
圖 | 圖中張瑞東佩戴的眼鏡就是 EchoSpeech 設備(來源:Photo Courtesy of Dave Burbank)EchoSpeech 是一款新型可穿戴無聲語音識別系統 ,它可以連續識別 31 條無聲語音指令,準確率達到 95%,最高電池續航時間約 10 小時。其中,傳感器成本不超過 100 元,單片機處理器成本 300 元左右。00:29(來源:ACM)無聲語音指的是只動嘴、而聲帶不發聲的說話方式,有些類似于耳語(不嚴格區分的話,耳語也可以算作無聲語音)。不過,耳語本身必須發出一些聲音,而無聲語音則無需發出任何聲音。正在閱讀這篇文章的你可以嘗試一下耳語,但是不要送出氣流,這樣幾乎不會發出任何聲音,而嘴唇和舌頭依然會動。對于公眾來說,無聲語音可能仍然是一個新鮮事物。但是,大家在日常中或多或少都會接觸到。比如,開會時和別人交流時的耳語。相比有聲語音來說,無聲語音最大的優勢就是“無聲”。在一些安靜的場合,比如圖書館、會議中等,出聲地說話是不合適的;另外,在特別嘈雜的環境中,語音交流也會容易受到噪聲的影響。在這種情況之下,都可以使用耳語。而對于聲帶損傷者或殘疾人士來說,無聲語音可能是最接近語音交流的唯一選擇。在這個意義上,關于無聲語音的相關應用具備很大的潛力。09:30(來源:ACM)對于無聲語音識別這項技術,已經有很多課題組在研究。最成熟、最流行的是依靠計算機視覺的方案:即使用相機直接捕捉面部運動尤其是嘴唇的運動。這種方法的缺點十分明顯:它必須在用戶面前放置相機,而這就涉及到普適性、功耗、隱私等問題。也正因此,目前面向可穿戴領域的解決方案多數還不成熟,在穿戴舒適度、功耗、系統等方面依舊欠佳。例如,在多支團隊的研究成果中,都需要在口腔內放置傳感器來追蹤舌頭運動。絕大多數方案只能識別說得比較清晰、語速較慢的離散指令,例如能識別單獨說出來的、中間有暫停的 1-2-3,但是無法識別連續說出來的 123。而張瑞東所在團隊研發的 EchoSpeech,在穿戴舒適度和連續識別上有著明顯優勢。在 EchoSpeech 的設計中,傳感器即小揚聲器的麥克風,被安裝在眼鏡框的下邊緣。這時,通過采用聲波感知技術,就能探測面部運動尤其嘴唇的運動,并以此來識別無聲語音。與同類成果相比,EchoSpeech 具有體積小、佩戴舒適、功耗低、隱私保護好等優勢。同時,在識別連續詞組/句子的能力上,EchoSpeech 也有著很大提升。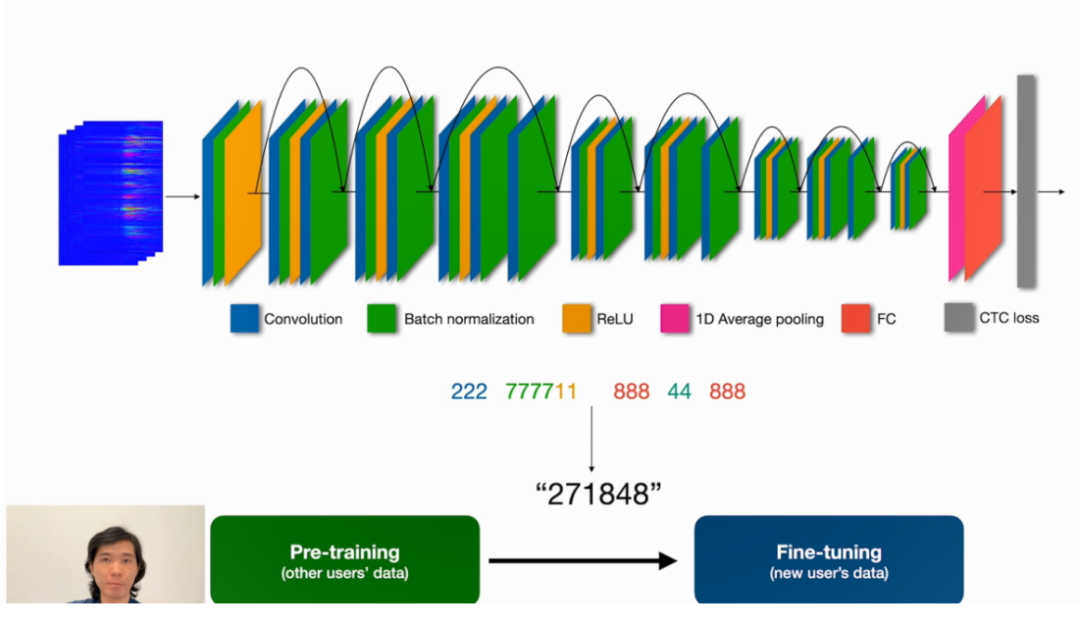 (來源:ACM)長期來看,無聲語音識別技術很有潛力作為普通語音識別的替代和補充。有研究顯示,隱私和社交尷尬是用戶不愿使用語音識別的重要因素 [1,2]。而無聲語音恰好解決這兩個問題,原因在于它可以擴展語音輸入整體的應用。另一方面,無聲語音還能把語音識別技術擴展到更多場景中,例如有望讓用戶在工作環境下使用無聲語音控制設備,同時也能讓用戶使用無聲語音來與 AI 使用自然語言交流,這樣一來既能大大提高工作效率,也不會打擾到周圍人。不過短期來看,由于詞匯量、識別準確率等方面的限制,要想實現大規模的應用可能還不成熟。目前,最有希望將 EchoSpeech 用于控制音樂播放和社交軟件等。03:53(來源:ACM)張瑞東表示:“一直以來,我們實驗室都專注于可穿戴交互設備的研究。我的上一個項目 SpeeChin,也是一個無聲語音識別的工作。不同之處在于,SpeeChin 采用掛在項鏈上的紅外相機來捕捉下巴運動,進而去推斷無聲語音。”相比之前的工作,SpeeChin 在識別準確率和設備舒適性上有著極大提高。但是,作為一種采用相機的方案,其依然存在功耗高、侵犯隱私等問題。正因為這些原因,該團隊一直在開發應用范圍更廣泛的感知技術,比如聲波感知技術等。張瑞東表示:“為此我參與了一個名為 EarIO 的項目,期間我們利用耳機上的揚聲器和麥克風,借助聲波感知技術通過捕捉耳后皮膚的微小震動來重建面部表情。在 EarIO 獲得成功時,我們立刻意識到了這項技術在其他方面的巨大潛力。于是開啟了本次 EchoSpeech 的項目。”立項之后,有兩個難題擺在張瑞東面前:一是尋找最合適的設備形態,包括設備本身的形態,以及傳感器的位置、角度和數量;二是提高系統性能,尤其是識別連續短語和句子的能力。在尋找設備形態上,他們嘗試了很多方案,比如耳機+外延的結構、以及環繞頭部固定器+外延結構等。但是,這類結構的主要問題在于,在多次佩戴之后穩定性欠佳。他們也嘗試過入耳式耳機、頭戴式耳機等結構,不過由于距離主要“發音器”(即說話時活動的部分例如嘴唇、舌頭)比較遠,故在同等條件之下識別準確率不甚理想,同時所需要的數據也更多。后來,張瑞東的導師想到了眼鏡。“導師強烈建議我試一試眼鏡框,我之前對眼鏡框不是很有信心,因為它離主要的‘發聲器’太遠了。而且由于位置和角度的原因,并沒有合適的直線傳播路徑。但是,在嘗試中我意識到對于信號來說,其實并不需要直線傳播。”張瑞東說。眼鏡的好處之一在于穩定性高,一般情況下眼鏡會被貼合地佩戴在頭上,在多次佩戴之后依然具備較好的穩定性。并且,眼鏡和主要“發聲器”之間的相對距離比較穩定。直到這時,裝置的最終形態終于被確定下來:即在眼鏡框下緣布置傳感器,其中一側放置揚聲器,另一側放置麥克風。在提高系統性能上,他們并未使用先切割出來說話部分、再進行識別的方法,而是使用端到端的方法,一次性地完成切割任務和識別任務。這樣一來,當佩戴者不說話的時候,系統就會輸出空標簽。至此,前面提到的兩個難題均被攻克,關于 EchoSpeech 的課題也正式宣告結束。日前,相關論文以《EchoSpeech:由聲學傳感驅動的最小干擾眼鏡上的連續無聲語音識別》(EchoSpeech: Continuous Silent Speech Recognition on Minimally-obtrusive Eyewear Powered by Acoustic Sensing)為題發在 2023 ACM 人機交互國際會議上,該會議也被認為是人機交互領域最負盛名的會議。張瑞東是論文第一作者,康奈爾大學教授張鋮擔任通訊作者 [3]。
(來源:ACM)長期來看,無聲語音識別技術很有潛力作為普通語音識別的替代和補充。有研究顯示,隱私和社交尷尬是用戶不愿使用語音識別的重要因素 [1,2]。而無聲語音恰好解決這兩個問題,原因在于它可以擴展語音輸入整體的應用。另一方面,無聲語音還能把語音識別技術擴展到更多場景中,例如有望讓用戶在工作環境下使用無聲語音控制設備,同時也能讓用戶使用無聲語音來與 AI 使用自然語言交流,這樣一來既能大大提高工作效率,也不會打擾到周圍人。不過短期來看,由于詞匯量、識別準確率等方面的限制,要想實現大規模的應用可能還不成熟。目前,最有希望將 EchoSpeech 用于控制音樂播放和社交軟件等。03:53(來源:ACM)張瑞東表示:“一直以來,我們實驗室都專注于可穿戴交互設備的研究。我的上一個項目 SpeeChin,也是一個無聲語音識別的工作。不同之處在于,SpeeChin 采用掛在項鏈上的紅外相機來捕捉下巴運動,進而去推斷無聲語音。”相比之前的工作,SpeeChin 在識別準確率和設備舒適性上有著極大提高。但是,作為一種采用相機的方案,其依然存在功耗高、侵犯隱私等問題。正因為這些原因,該團隊一直在開發應用范圍更廣泛的感知技術,比如聲波感知技術等。張瑞東表示:“為此我參與了一個名為 EarIO 的項目,期間我們利用耳機上的揚聲器和麥克風,借助聲波感知技術通過捕捉耳后皮膚的微小震動來重建面部表情。在 EarIO 獲得成功時,我們立刻意識到了這項技術在其他方面的巨大潛力。于是開啟了本次 EchoSpeech 的項目。”立項之后,有兩個難題擺在張瑞東面前:一是尋找最合適的設備形態,包括設備本身的形態,以及傳感器的位置、角度和數量;二是提高系統性能,尤其是識別連續短語和句子的能力。在尋找設備形態上,他們嘗試了很多方案,比如耳機+外延的結構、以及環繞頭部固定器+外延結構等。但是,這類結構的主要問題在于,在多次佩戴之后穩定性欠佳。他們也嘗試過入耳式耳機、頭戴式耳機等結構,不過由于距離主要“發音器”(即說話時活動的部分例如嘴唇、舌頭)比較遠,故在同等條件之下識別準確率不甚理想,同時所需要的數據也更多。后來,張瑞東的導師想到了眼鏡。“導師強烈建議我試一試眼鏡框,我之前對眼鏡框不是很有信心,因為它離主要的‘發聲器’太遠了。而且由于位置和角度的原因,并沒有合適的直線傳播路徑。但是,在嘗試中我意識到對于信號來說,其實并不需要直線傳播。”張瑞東說。眼鏡的好處之一在于穩定性高,一般情況下眼鏡會被貼合地佩戴在頭上,在多次佩戴之后依然具備較好的穩定性。并且,眼鏡和主要“發聲器”之間的相對距離比較穩定。直到這時,裝置的最終形態終于被確定下來:即在眼鏡框下緣布置傳感器,其中一側放置揚聲器,另一側放置麥克風。在提高系統性能上,他們并未使用先切割出來說話部分、再進行識別的方法,而是使用端到端的方法,一次性地完成切割任務和識別任務。這樣一來,當佩戴者不說話的時候,系統就會輸出空標簽。至此,前面提到的兩個難題均被攻克,關于 EchoSpeech 的課題也正式宣告結束。日前,相關論文以《EchoSpeech:由聲學傳感驅動的最小干擾眼鏡上的連續無聲語音識別》(EchoSpeech: Continuous Silent Speech Recognition on Minimally-obtrusive Eyewear Powered by Acoustic Sensing)為題發在 2023 ACM 人機交互國際會議上,該會議也被認為是人機交互領域最負盛名的會議。張瑞東是論文第一作者,康奈爾大學教授張鋮擔任通訊作者 [3]。 圖 | 相關論文(來源:ACM)基于本次成果,張瑞東也將開展語音合成、以及擴展詞匯量。假如可以實現語音合成,那么就能用于發音障礙人群身上,從而給他們提供一個真正的語音交互接口。而之所以打算拓展詞匯量,是因為如果想把無聲語音識別真正做成一個有用的產品,就必須能夠識別更多的單詞。長期來看,該團隊希望無聲語音識別技術的表現,能夠和普通語音識別相媲美,只有這樣才能討論更加長遠的應用。另據悉,張瑞東所在的團隊專注于研究智能傳感器件,此前他們還曾造出可以檢測表情的耳機等創新設備。目前,該團隊已有超過 20 項正在申請的美國專利和國際專利。
圖 | 相關論文(來源:ACM)基于本次成果,張瑞東也將開展語音合成、以及擴展詞匯量。假如可以實現語音合成,那么就能用于發音障礙人群身上,從而給他們提供一個真正的語音交互接口。而之所以打算拓展詞匯量,是因為如果想把無聲語音識別真正做成一個有用的產品,就必須能夠識別更多的單詞。長期來看,該團隊希望無聲語音識別技術的表現,能夠和普通語音識別相媲美,只有這樣才能討論更加長遠的應用。另據悉,張瑞東所在的團隊專注于研究智能傳感器件,此前他們還曾造出可以檢測表情的耳機等創新設備。目前,該團隊已有超過 20 項正在申請的美國專利和國際專利。 *博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
