量子計算第二里程碑!谷歌實現量子糾錯突破,150多位作者成果登Nature

2019年,谷歌首次宣稱實現量子霸權,創下首個里程碑。3年之后,這家公司宣布已經達到通往構建大型量子計算機道路上的第二個關鍵里程碑(M2)。
即有史以來首次通過增加量子比特來降低計算錯誤率!
 官方博客稱,量子糾錯(QEC)通過多個物理量子比特,即「邏輯量子比特」,對信息進行編碼。這一方法被認為是大型量子計算機降低錯誤率來進行計算的唯一方法。最新研究成果已發表在Nature期刊上。
官方博客稱,量子糾錯(QEC)通過多個物理量子比特,即「邏輯量子比特」,對信息進行編碼。這一方法被認為是大型量子計算機降低錯誤率來進行計算的唯一方法。最新研究成果已發表在Nature期刊上。

物理量子比特到邏輯量子比特
2020年,谷歌曾發布了一份量子計算路線圖,共有六個關鍵里程碑。量子霸權第一,而當前最新成果代表了M2。最后一個里程碑M6是實現100萬個物理量子比特組成的量子計算機,編碼1000個邏輯量子比特,到那時便可以實現量子計算機商業應用的價值。
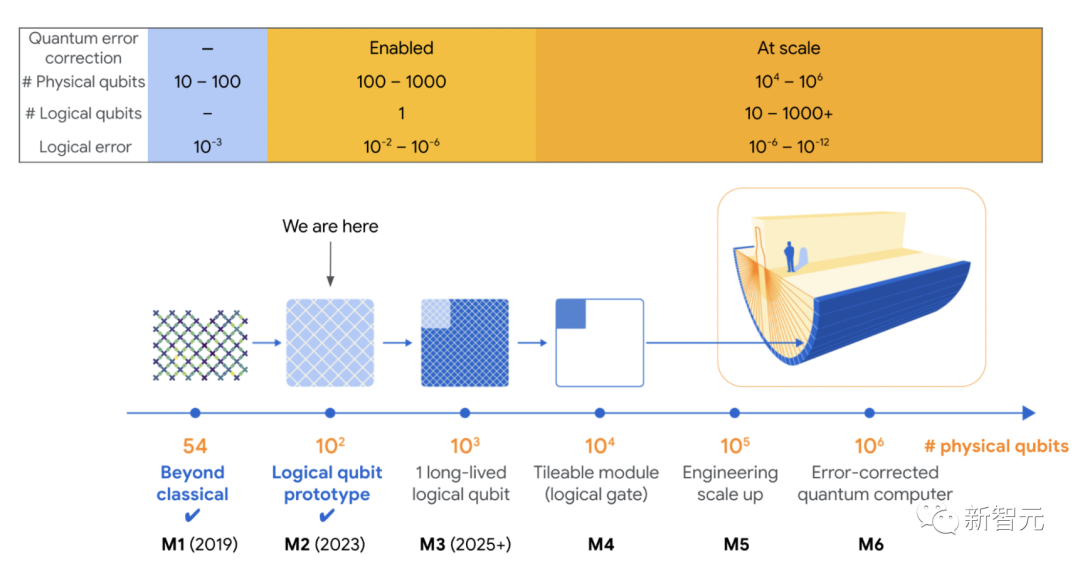 為什么要糾錯呢?需要明確的是,所有計算機都會出錯。要想量子計算機能夠處理普通計算機無法解決的問題,比如將大整數分解為素數,糾錯是不可避免的。對于普通計算機來講,其芯片以位(可以表示0或1)的形式存儲信息,并將一些信息復制到冗余的糾錯位中。當發生錯誤時,芯片可以自動發現問題并進行修復。然而,在量子計算中,卻無法做到這一點。量子比特是量子信息的基本單位,量子比特是0和1的量子疊加。如果一個量子比特的完整量子態不可挽回地丟失,則無法讀出信息,也就意味著它的信息不能簡單地復制到冗余量子比特上。
為什么要糾錯呢?需要明確的是,所有計算機都會出錯。要想量子計算機能夠處理普通計算機無法解決的問題,比如將大整數分解為素數,糾錯是不可避免的。對于普通計算機來講,其芯片以位(可以表示0或1)的形式存儲信息,并將一些信息復制到冗余的糾錯位中。當發生錯誤時,芯片可以自動發現問題并進行修復。然而,在量子計算中,卻無法做到這一點。量子比特是量子信息的基本單位,量子比特是0和1的量子疊加。如果一個量子比特的完整量子態不可挽回地丟失,則無法讀出信息,也就意味著它的信息不能簡單地復制到冗余量子比特上。現在,谷歌量子團隊找到了一種全新的量子糾錯方案:
即通過在一組物理量子,而不是單個量子中編碼信息的量子比特,稱為「邏輯量子比特」。
,時長03:59
另外,使用多個量子比特進行量子糾錯的優勢在于它可以不斷擴展(Sacling)。當然,物極必反,添加更多量子比特也會導致其中兩個量子同時受到錯誤影響的機會。為了解決這一問題,谷歌研究人員對量子芯片Sycamore的量子比特進行了改進,研究了2種不同大小的邏輯量子比特。一個是由17個量子比特組成,一次能夠從一個錯誤中糾錯;另一個由49個量子比特組成,可以從兩個同時發生的錯誤中糾錯。實驗結果顯示,其性能優于17個量子比特的版本。

表面碼邏輯量子比特糾錯
谷歌團隊是如何具體地實現這一成果呢?舉一個經典通信中的簡單例子:Bob想通過噪音的通信信道向Alice發送一個讀為「1」的位。他認識到如果該位翻轉為「0」則消息丟失,因此改為發送三個位「111」。如果一個人錯誤地翻轉,Alice可以對所有接收到的位進行多數表決(一個簡單的糾錯碼),仍然能夠理解預期的消息。若將信息重復三次以上,即增加編碼的「大小」,將使編碼能夠糾正更多個別錯誤。表面碼則采用了這一原則,并設想了一個實用的量子實現。它必須滿足兩個額外的約束。
 首先,表面碼必須能夠糾正不只是位翻轉(從0到1個取一個量子比特),而且相位翻轉。這個錯誤是量子態所獨有的,并將量子比特轉換為疊加態,例如從0+1到0-1。其次,檢查量子比特的狀態會破壞其疊加態,因此需要一種無需直接測量狀態即可檢測錯誤的方法。為了突破這些限制,我們在棋盤上排列了2種類型的量子比特。頂點上的「數據」量子比特構成邏輯量子比特,而每個正方形中心的「測量」量子比特用于所謂的穩定器測量。這些測量結果告訴我們這些量子比特是否完全相同/不同,表明發生了錯誤,但實際上并沒有揭示各個數據量子比特的值。
首先,表面碼必須能夠糾正不只是位翻轉(從0到1個取一個量子比特),而且相位翻轉。這個錯誤是量子態所獨有的,并將量子比特轉換為疊加態,例如從0+1到0-1。其次,檢查量子比特的狀態會破壞其疊加態,因此需要一種無需直接測量狀態即可檢測錯誤的方法。為了突破這些限制,我們在棋盤上排列了2種類型的量子比特。頂點上的「數據」量子比特構成邏輯量子比特,而每個正方形中心的「測量」量子比特用于所謂的穩定器測量。這些測量結果告訴我們這些量子比特是否完全相同/不同,表明發生了錯誤,但實際上并沒有揭示各個數據量子比特的值。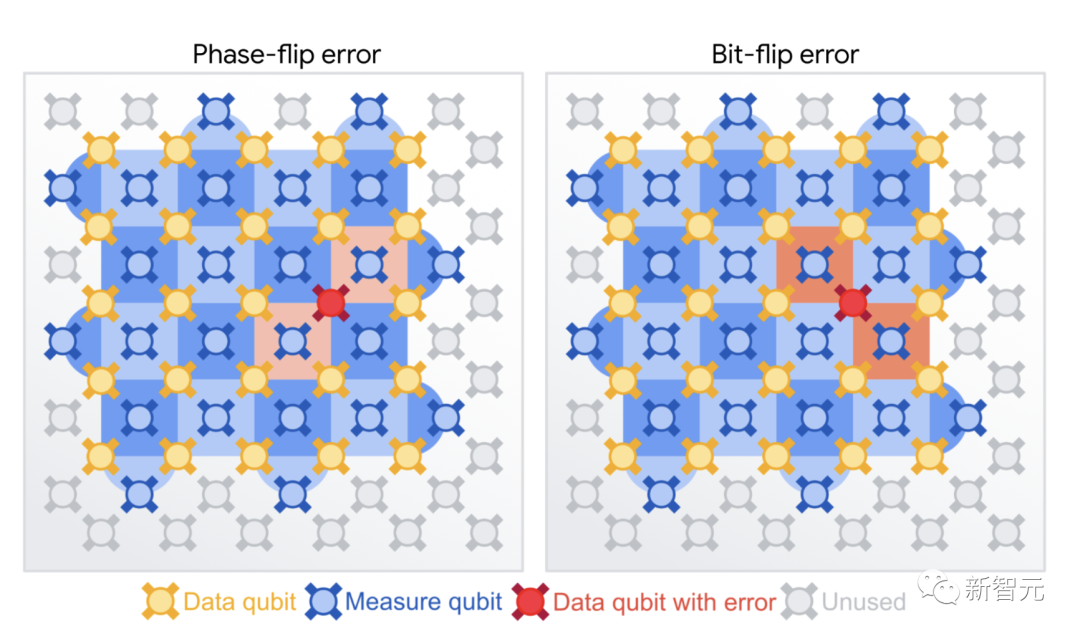 通過棋盤模式平鋪兩種類型的穩定器測量,以保護邏輯數據免受位翻轉和相位翻轉的影響。如果一些穩定器測量值記錄了錯誤,則使用穩定器測量值中的相關性來識別發生了哪些錯誤以及發生在何處。就比如上面例子中Bob給Alice的消息隨著編碼大小的增加而變得更加強大,一個更大的表面碼可以更好地保護它所包含的邏輯信息。表面碼可以承受一定數量的位和相位翻轉誤差,每個誤差小于距離的一半,其中距離是在任一維度上跨越表面代碼的數據量子比特數。問題是每個物理量子比特都容易出錯,所以編碼中的量子比特越多,出錯的幾率就會越大。為此,物理量子比特的誤差必須低于所謂的「容錯閾值」。對于表面碼來說,這個閾值是相當低的。最新實驗便證明了這一點。實驗運行在谷歌最先進的第三代Sycamore處理器架構,為QEC進行了優化,使用了全面改進的表面碼。為此,研究人員對其量子計算機的所有部件進行了7大改進,包括量子比特的質量、控制軟件,再到用于將計算機冷卻到接近絕對零度的低溫設備。
通過棋盤模式平鋪兩種類型的穩定器測量,以保護邏輯數據免受位翻轉和相位翻轉的影響。如果一些穩定器測量值記錄了錯誤,則使用穩定器測量值中的相關性來識別發生了哪些錯誤以及發生在何處。就比如上面例子中Bob給Alice的消息隨著編碼大小的增加而變得更加強大,一個更大的表面碼可以更好地保護它所包含的邏輯信息。表面碼可以承受一定數量的位和相位翻轉誤差,每個誤差小于距離的一半,其中距離是在任一維度上跨越表面代碼的數據量子比特數。問題是每個物理量子比特都容易出錯,所以編碼中的量子比特越多,出錯的幾率就會越大。為此,物理量子比特的誤差必須低于所謂的「容錯閾值」。對于表面碼來說,這個閾值是相當低的。最新實驗便證明了這一點。實驗運行在谷歌最先進的第三代Sycamore處理器架構,為QEC進行了優化,使用了全面改進的表面碼。為此,研究人員對其量子計算機的所有部件進行了7大改進,包括量子比特的質量、控制軟件,再到用于將計算機冷卻到接近絕對零度的低溫設備。 研究人員通過實驗來比較基于17個物理量子比特distance-3表面碼(ε3)和基于49個物理量子比特distance-5表面碼(ε5)的邏輯錯誤率之間的比率。
研究人員通過實驗來比較基于17個物理量子比特distance-3表面碼(ε3)和基于49個物理量子比特distance-5表面碼(ε5)的邏輯錯誤率之間的比率。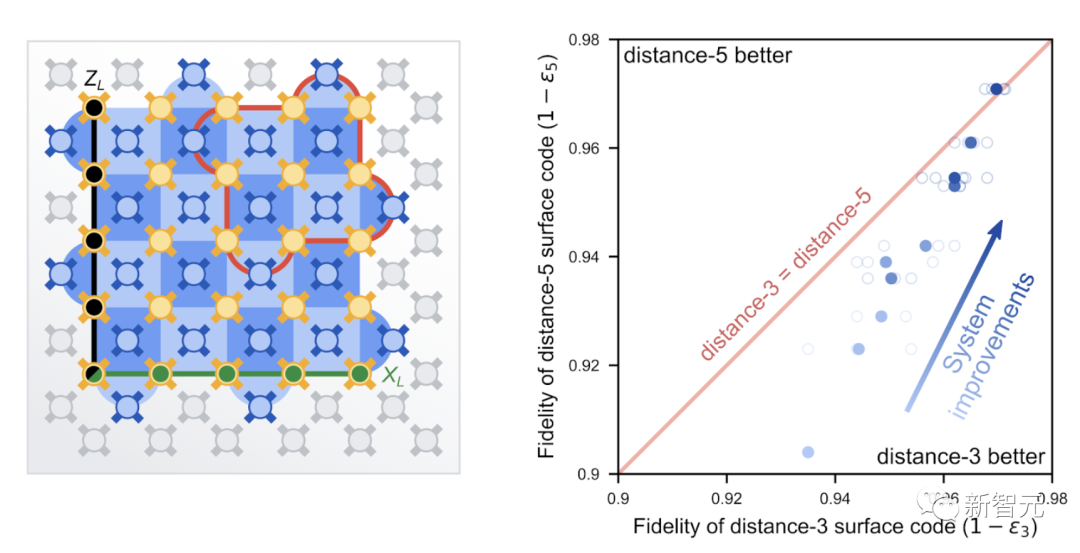 實驗結果如上圖右所示,較大表面碼展現出能夠實現更好的邏輯量子比特性能(每周期2.914%邏輯錯誤),優于較小的表面碼(每周期3.028%邏輯錯誤)。谷歌稱,雖然這可能看起來是一個小的改進,但是不得不強調這一結果是自Peter Shor的1995年QEC提案以來該領域的首創。較大編碼優于較小編碼是QEC的關鍵特征,所有量子計算架構都需要跨過這一障礙,才能降低量子應用的低錯誤率。
實驗結果如上圖右所示,較大表面碼展現出能夠實現更好的邏輯量子比特性能(每周期2.914%邏輯錯誤),優于較小的表面碼(每周期3.028%邏輯錯誤)。谷歌稱,雖然這可能看起來是一個小的改進,但是不得不強調這一結果是自Peter Shor的1995年QEC提案以來該領域的首創。較大編碼優于較小編碼是QEC的關鍵特征,所有量子計算架構都需要跨過這一障礙,才能降低量子應用的低錯誤率。未來之路
上面這些結果表明,我們正進入一個實用的QEC新時代。
過去幾年,谷歌的Quantum AI團隊一直在思考:該如何定義這個新時代的成功,如何衡量一路走來的進步?他們的最終目標是,展示一種在有意義的應用中,使用量子計算機所需的低錯誤的途徑。因此,專家們的目標仍然是在每個QEC周期中達到10^6分之一或更低的邏輯錯誤率。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
