存算一體技術是什么?發展史、優勢、應用方向、主要介質

 本文****的介紹存算一體技術的概念、發展歷史、技術優勢、應用方向、主要介質、技術比對等。作者: 陳巍 博士 資深芯片專家,人工智能算法-芯片協同設計專家,擅長芯片架構與存算一體。國內首個可重構存算處理器架構(已在互聯網大廠完成原型內測),首個醫療領域專用AI處理器(已落地應用),首個RISC-V/x86/ARM平臺兼容的AI加速編譯器(與阿里平頭哥/芯來合作),國內首個3D NAND芯片架構與設計團隊建立(與三星對標),國內首個嵌入式閃存編譯器(與臺積電對標),國內首個90nm閃存芯片架構(與Cypress/SST對標)作者:耿云川 博士 資深SoC設計專家,軟硬件協同設計專家,擅長人工智能加速芯片設計。國內首個可重構存算處理器架構(已在互聯網大廠完成原型內測),日本NEC電子EMMA-mobile構架多媒體計算系統,日本瑞薩電子車載計算SoC芯片構架(唯一外籍專家),日本瑞薩電子R-Mobile/R-Car系列車載計算芯片,支持ADAS的車載計算硬件
本文****的介紹存算一體技術的概念、發展歷史、技術優勢、應用方向、主要介質、技術比對等。作者: 陳巍 博士 資深芯片專家,人工智能算法-芯片協同設計專家,擅長芯片架構與存算一體。國內首個可重構存算處理器架構(已在互聯網大廠完成原型內測),首個醫療領域專用AI處理器(已落地應用),首個RISC-V/x86/ARM平臺兼容的AI加速編譯器(與阿里平頭哥/芯來合作),國內首個3D NAND芯片架構與設計團隊建立(與三星對標),國內首個嵌入式閃存編譯器(與臺積電對標),國內首個90nm閃存芯片架構(與Cypress/SST對標)作者:耿云川 博士 資深SoC設計專家,軟硬件協同設計專家,擅長人工智能加速芯片設計。國內首個可重構存算處理器架構(已在互聯網大廠完成原型內測),日本NEC電子EMMA-mobile構架多媒體計算系統,日本瑞薩電子車載計算SoC芯片構架(唯一外籍專家),日本瑞薩電子R-Mobile/R-Car系列車載計算芯片,支持ADAS的車載計算硬件01 什么是存算一體
存算一體(Computing in Memory)是在存儲器中嵌入計算能力,以新的運算架構進行二維和三維矩陣乘法/加法運算。
存算一體技術概念的形成,最早可以追溯到上個世紀70年代。隨著近幾年云計算和人工智能(AI)應用的發展,面對計算中心的數據洪流,數據搬運慢、搬運能耗大等問題成為了計算的關鍵瓶頸。在過去二十年,處理器性能以每年大約55%的速度提升,內存性能的提升速度每年只有10%左右。結果長期下來,不均衡的發展速度造成了當前的存儲速度嚴重滯后于處理器的計算速度。在傳統計算機的設定里,存儲模塊是為計算服務的,因此設計上會考慮存儲與計算的分離與優先級。但是如今,存儲和計算不得不整體考慮,以最佳的配合方式為數據采集、傳輸和處理服務。這里面,存儲與計算的再分配過程就會面臨各種問題,而它們主要體現為存儲墻、帶寬墻和功耗墻問題。
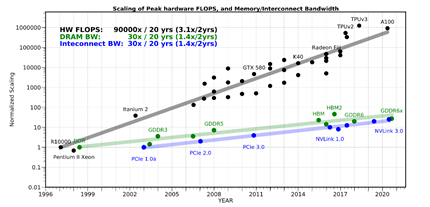 算力發展速度遠超存儲(來源:amirgholami@github)雖然多核(例如CPU)/眾核(例如GPU)并行加速技術也能提升算力,但在后摩爾時代,存儲帶寬制約了計算系統的有效帶寬,芯片算力增長步履維艱。從處理單元外的存儲器提取數據,搬運時間往往是運算時間的成百上千倍,整個過程的無用能耗大概在60%-90%之間,能效非常低,“存儲墻”成為了數據計算應用的一大障礙。特別是,深度學習加速的最大挑戰就是數據在計算單元和存儲單元之間頻繁的移動。
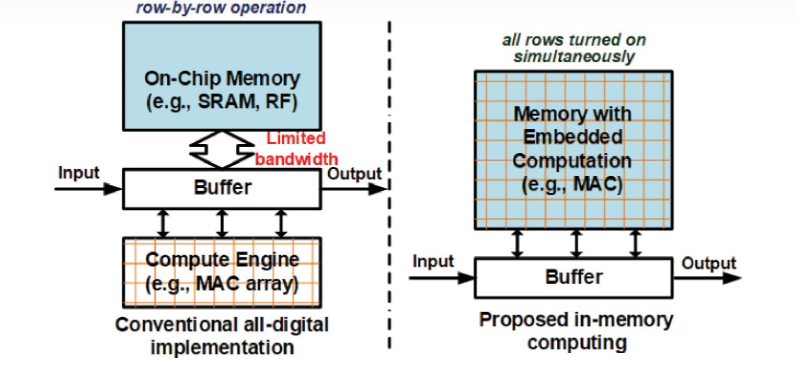
算力發展速度遠超存儲(來源:amirgholami@github)雖然多核(例如CPU)/眾核(例如GPU)并行加速技術也能提升算力,但在后摩爾時代,存儲帶寬制約了計算系統的有效帶寬,芯片算力增長步履維艱。從處理單元外的存儲器提取數據,搬運時間往往是運算時間的成百上千倍,整個過程的無用能耗大概在60%-90%之間,能效非常低,“存儲墻”成為了數據計算應用的一大障礙。特別是,深度學習加速的最大挑戰就是數據在計算單元和存儲單元之間頻繁的移動。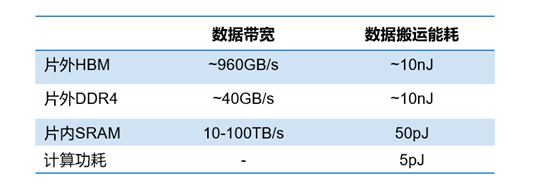 數據搬運占據AI計算的主要能耗存內計算和存內邏輯,即存算一體技術直接利用存儲器進行數據處理或計算,從而把數據存儲與計算融合在同一個芯片的同一片區之中,可以徹底消除馮諾依曼計算架構瓶頸,特別適用于深度學習神經網絡這種大數據量大規模并行的應用場景。需要注意的是,一般的存算一體指的是“compute-in-memory”或“compute-near-memory”,與存儲服務器的分布式設計或服務器內存計算不是一個細分領域的。對于國內一些做ssd controller+AI的芯片,個人建議直接稱之為“compute-in-ssd”或“compute-in-storage”,避免交流時的歧義。
數據搬運占據AI計算的主要能耗存內計算和存內邏輯,即存算一體技術直接利用存儲器進行數據處理或計算,從而把數據存儲與計算融合在同一個芯片的同一片區之中,可以徹底消除馮諾依曼計算架構瓶頸,特別適用于深度學習神經網絡這種大數據量大規模并行的應用場景。需要注意的是,一般的存算一體指的是“compute-in-memory”或“compute-near-memory”,與存儲服務器的分布式設計或服務器內存計算不是一個細分領域的。對于國內一些做ssd controller+AI的芯片,個人建議直接稱之為“compute-in-ssd”或“compute-in-storage”,避免交流時的歧義。
02 存算一體發展史
1969年,斯坦福研究所的Kautz等人提出了存算一體計算機的概念。但受限于當時的芯片制造技術和算力需求的匱乏,那時存算一體僅僅停留在理論研究階段,并未得到實際應用。
為了打破馮諾依曼計算架構瓶頸,降低“存儲-內存-處理單元”過程數據搬移帶來的開銷,學術界和工業界嘗試了多種方法。其中比較直接的方法是近存計算,減少內存和處理單元之間的路徑,如通過3D封裝技術實現3D堆疊,將多層DRAM堆疊而成的新型內存,能提供更大的內存容量和內存帶寬。此外,Intel和Micron合作開發的基于PRAM存儲介質的3D Xpoint屬于堆疊型內存,旨在縮短片上存儲與內存之間的路徑。但上述方案并沒有改變數據存儲與數據處理分離的問題,并不能從根本上解決馮諾依曼計算架構瓶頸。近年來,隨著半導體制造技術的突飛猛進,以及AI、元宇宙等算力密集的應用場景的崛起,為存算一體技術提供新的制造平臺和產業驅動力。2010年,惠普實驗室的Williams教授團隊用憶阻器實現簡單布爾邏輯功能。2016年,美國加州大學圣塔芭芭拉分校(UCSB)的謝源教授團隊提出使用RRAM構建存算一體架構的深度學習神經網絡(PRIME)。相較于傳統馮諾伊曼架構的傳統方案,PRIME可以實現功耗降低約20倍、速度提升約50倍,引起產業界廣泛關注。隨著人工智能等大數據應用的興起,存算一體技術得到國內外學術界與產業界的廣泛研究與應用。在2017年微處理器頂級年會(Micro 2017)上,包括英偉達、英特爾、微軟、三星、加州大學圣塔芭芭拉分校等都推出了他們的存算一體系統原型。
03 存算一體的優勢
存算一體的優勢是打破存儲墻,消除不必要的數據搬移延遲和功耗,并使用存儲單元提升算力,成百上千倍的提高計算效率,降低成本。
存算一體屬于非馮諾伊曼架構,在特定領域可以提供更大算力(1000TOPS以上)和更高能效(超過10-100TOPS/W),明顯超越現有ASIC算力芯片。除了用于AI計算外,存算技術也可用于感存算一體芯片和類腦芯片,代表了未來主流的大數據計算芯片架構。存算一體技術的核心優勢包括:
- 減少不必要的數據搬運。(降低能耗至1/10~1/100)
使用存儲單元參與邏輯計算提升算力。(等效于在面積不變的情況下規模化增加計算核心數)
04 存算一體的市場驅動力
目前,存算一體的商業驅動力主要源于AI和元宇宙算力的需求、并行計算在深度學習的廣泛應用。看向應用端,存算一體的市場發展驅動卻是非常強烈的。
以數據中心為例,百億億次(E級)的超級計算機成為各國比拼算力的關鍵點,為此美國能源部啟動了“百億億次計算項目(Exascale Computing Project)”;中國則聯合國防科大、中科曙光和國家并行計算機工程技術研究中心積極開展相關研究,計劃于推出首臺E級超算。但要想研制E級超算,科學家面臨的挑戰之中首當其沖的就是功耗過高問題。以現有技術研制的E級超算功率高達千兆瓦,需要一個專門的核電站來給它供電,而其中50%以上的功耗都來源于數據的“搬運”,本質上就是馮·諾依曼計算機體系結構計算與存儲的分離設計所致。基于神經網絡的人工智能的興起,大算力高能效比的存內計算獲得了廣泛關注。在神經網絡運算中,其運算權重固定,一般僅“輸入”是實時產生,因此可以將權重存在片上存儲器,等外部“輸入”進入后再進行高能效的存內計算。同時,隨著存算一體技術的進步,通過存內計算和存內邏輯,已經可以完成32位以上的高精度計算,普遍適用于從端到云的各類計算需求。此外,新型存儲器的出現也帶動了存算一體技術的發展,為存算一體技術升級方向提供可能。其中,阻變憶阻器RRAM使用等效器件電阻調制來實現數據存儲,可以實現更高的計算密度。新型存儲器與存算一體技術的結合,形成了新一代的算力元素,有望推動下一階段的人工智能發展。
05 存算一體技術分類
在馮諾伊曼架構中,計算單元與內存是兩個分離的單元。計算單元根據指令從內存中讀取數據,在計算單元中完成計算和處理,完成后再將數據存回內存。
在這個過程中,存儲器與處理器之間數據交換通路窄,以及由此引發的高能耗形成兩大難題,在存儲與計算之間筑起一道“存儲墻”。能耗方面,大部分能耗在數據搬運過程中產生,數據搬運功耗是計算功耗的1000倍。而數據搬運速度方面,AI運算需1PB/s,但DRAM 40GB-1TB/s 都遠達不到要求。
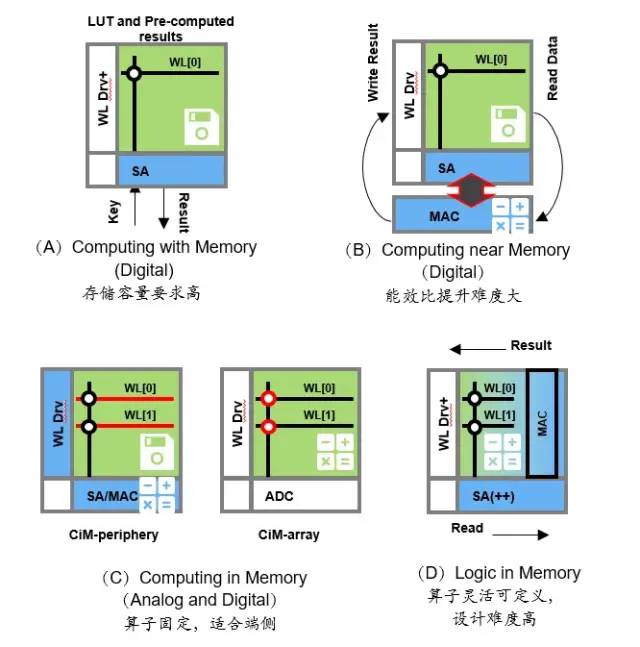
06 技術應用方向
AI和大數據計算
存算一體被多家技術趨勢研究機構確定為今后的科技趨勢。存算一體是突破AI算力瓶頸和大數據的關鍵技術。因為利用存算一體技術,設備性能不僅能夠得到提升,其成本也能夠大幅降低。通過使用存算一體技術,可將帶AI計算的中大量乘加計算的權重部分存在存儲單元中,在存儲單元的核心電路上做修改,從而在讀取的同時進行數據輸入和計算處理,在存儲陣列中完成卷積運算。由于大量乘加的卷積運算是深度學習算法中的核心組成部分,因此存內計算和存內邏輯非常適合人工智能的深度神經網絡應用和基于AI的大數據技術。感存算一體集傳感、儲存和運算為一體構建感存算一體架構,解決馮諾依曼架構的數據搬運的功耗瓶頸,同時與傳感結合提高整體效率。在傳感器自身包含的AI存算一體芯片上運算,來實現零延時和超低功耗的智能視覺處理能力。基于SRAM模數混合的視覺應用存內計算神經擬態芯片僅在檢測到有意義的時間才會進行處理,大幅降低能耗。類腦計算類腦計算(Brain-inspired Computing)又被稱為神經形態計算(Neuromorphic Computing)。是借鑒生物神經系統信息處理模式和結構的計算理論、體系結構、芯片設計以及應用模型與算法的總稱。近年來,科學家們試圖借鑒人腦的物理結構和工作特點,讓計算機完成特定的計算任務。目的是使計算機像人腦一樣將存儲和計算合二為一,從而高速處理信息。存算一體天然是將存儲和計算結合在一起的技術,天然適合應用在類腦計算領域,并成為類腦計算的關鍵技術基石。由于類腦計算屬于大算力高能效領域,因此針對云計算和邊緣計算的存算一體技術,是未來類腦計算的首選和產品快速落地的關鍵。
07 數字存算一體與模擬存算一體對比
存算一體的計算方式分為數字計算和多比特模擬計算。
數字存算一體主要以SRAM和RRAM作為存儲器件,采用先進邏輯工藝,具有高性能高精度的優勢,且具備很好的抗噪聲能力和可靠性。而模擬存算一體通常使用FLASH、RRAM、PRAM等非易失性介質作為存儲器件,存儲密度大,并行度高,但是對環境噪聲和溫度非常敏感。例如Intel和NVIDIA的算力芯片,盡管也可采用模擬計算技術提升能效,但從未有一顆大算力芯片采用模擬計算技術。數字存算一體適合大算力高能效的商用場景,而模擬存算一體適合小算力、不需要可靠性的民用場景。
08 存算一體的存儲介質對比
目前可用于存算一體的成熟存儲器有NOR FLASH、SRAM、DRAM、RRAM、MRAM等NVRAM。
早期創業企業所用FLASH屬于非易失性存儲介質,具有低成本、高可靠性的優勢,但在工藝制程有明顯的瓶頸。SRAM在速度方面和能效比方面具有優勢,特別是在存內邏輯技術發展起來之后具有明顯的高能效和高精度特點。DRAM成本低,容量大,但是速度慢,且需要電力不斷刷新。適用存算一體的新型存儲器有PCAM、MRAM、RRAM和FRAM等。其中憶阻器RRAM在神經網絡計算中具有特別的優勢,是除了SRAM存算一體之外的,下一代存算一體介質的主流研究方向。目前RRAM距離工藝成熟還需要2-5年,材料不穩定,但RRAM具有高速、結構簡單的優點,有希望成為未來發展最快的新型存儲器。從學術界和工業界的研發趨勢上看,SRAM和RRAM都是未來主流的存算一體介質。
| 存儲器類型 | 優勢 | 不足 | 適合場景 |
| SRAM(數字模式) | 能效比高,高速高精度,對噪聲不敏感,工藝成熟先進,適合IP化 | 存儲密度略低 | 大算力、云計算、邊緣計算 |
| SRAM(模擬模式) | 能效比高,工藝成熟先進 | 對PVT變化敏感,對信噪比敏感,存儲密度略低 | 小算力、端側、不要求待機功耗 |
| 各類NVRAM(包括RRAM/MRAM等) | 能效比高,高密度,非易失,低漏電 | 對 PVT變化敏感,有限寫次數,相對低速,工藝良率尚在爬坡中 | 小算力、端側/邊緣Inference、待機時間長的場景 |
| Flash | 高密度低成本,非易失,低漏電 | 對 PVT變化敏感,精度不高,工藝迭代時間長 | 小算力、端側、低成本、待機時間長的場景 |
| DRAM | 高存儲密度,整合方案成熟 | 只能做近存計算,速度略低,工藝迭代慢 | 適合現有馮氏架構向存算過渡 |
09 存算一體的應用場景
存算一體芯片適用于各類人工智能場景和元宇宙計算,如可穿戴設備、移動終端、智能駕駛、數據中心等。
按算力大小劃分:1)針對端側的可穿戴等小設備,對算力的要求遠低于智能駕駛和云計算設備,但對成本、功耗、時延、開發難度很敏感。端側競品眾多,應用場景碎片化,面臨成本與功效的難題。存算一體技術在端側的競爭力影響約占30%。(例如arm占30%,降噪或ISP占40%,AI加速能力只占30%)2)針對云計算和邊緣計算的大算力設備,是存算一體芯片的優勢領域。存算一體在云和邊緣的大算力領域的競爭力影響約占90%。邊緣端存算一體芯片在邊緣端具有高算力、低功耗、高性價比的優勢。而針對智能駕駛、數據中心等大算力應用場景,在可靠性、算力方面有較高要求云計算市場玩家相對集中。各家有各家的算法和生態細節,芯片售價較高。存算一體芯片以其高能效大算力優勢有望另辟蹊徑搶占云計算市場。

10 總結
存算一體已經被知名研究機構和產業方確定為下一代技術趨勢之一。
目前國內外存算一體企業,都是剛剛起步階段,差距尚不大。存算一體芯片在設計層面是創新的,沒有成熟的方法借用。存算一體是計算系統和存儲系統的整合設計,比標準模擬IP和存儲器IP更更復雜,依賴于多次存儲器流片而積累的經驗,需要創始團隊有充分的存儲器量產經驗和技術路線認知。目前行業主要兩類路徑,一類是從小算力1TOPS開始往上走,解決的是音頻類、健康類及低功耗視覺終端側應用場景,AI落地的芯片性能以及功耗問題。另一類主要是針對大算力場景>100TOPS,解決大算力問題,在無人車、泛機器人、智能駕駛,云計算領域提供高性能大算力和高性價比的產品。由于云計算和智能駕駛需求多樣,且各大廠的算法和生態有明顯的差異化,因此這些領域都有比較好的成長空間。隨著AI技術的加速落地,和元宇宙技術對于算力的大量需求,存算一體技術會不斷進步,成為繼CPU、GPU架構之后的算力架構“第三極”。來源:算力基建
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。
