拼寫、常識(shí)、語法、推理錯(cuò)誤都能糾正,云從提出基于BART的語義糾錯(cuò)方法

云從科技語音組提出了一種基于 BART 預(yù)訓(xùn)練模型的語義糾錯(cuò)技術(shù)方案,它不僅可以對(duì) ASR 數(shù)據(jù)中常見的拼寫錯(cuò)誤進(jìn)行糾正,還可以對(duì)一些常識(shí)錯(cuò)誤、語法錯(cuò)誤,甚至一些需要推理的錯(cuò)誤進(jìn)行糾正。
近些年來,隨著自動(dòng)語音識(shí)別(ASR)技術(shù)的發(fā)展,識(shí)別準(zhǔn)確率有了很大的提升。但是,在 ASR 轉(zhuǎn)寫結(jié)果中,仍然存在一些對(duì)人類來說非常明顯的錯(cuò)誤。我們并不需要聽音頻,僅通過觀察轉(zhuǎn)寫的文本便可發(fā)現(xiàn)。對(duì)這類錯(cuò)誤的糾正往往需要借助一些常識(shí)和語法知識(shí),甚至推理的能力。得益于最近無監(jiān)督預(yù)訓(xùn)練語言模型技術(shù)的發(fā)展,基于純文本特征的糾錯(cuò)模型可以有效地解決這類問題。
本文提出的語義糾錯(cuò)系統(tǒng)分編碼器和****兩個(gè)模塊,編碼器著重于理解 ASR 系統(tǒng)輸出文本的語義,****的設(shè)計(jì)重在使用規(guī)范的詞匯重新表達(dá)。

論文鏈接:https://arxiv.org/abs/2104.05507
引言
文本糾錯(cuò)是一項(xiàng)提升 ASR 識(shí)別準(zhǔn)確率的重要方法,常見的文本糾錯(cuò)有語法糾錯(cuò),拼寫糾錯(cuò)等。由于 ASR 系統(tǒng)轉(zhuǎn)寫的錯(cuò)誤分布與上述的錯(cuò)誤分布差異較大,所以這些模型往往并不適合直接用在 ASR 系統(tǒng)中。這里,云從科技語音組提出了一種基于 BART 預(yù)訓(xùn)練模型 [1] 的語義糾錯(cuò)(SC)技術(shù)方案,它不僅可以對(duì) ASR 數(shù)據(jù)中常見的拼寫錯(cuò)誤進(jìn)行糾正,還可以對(duì)一些常識(shí)錯(cuò)誤、語法錯(cuò)誤,甚至一些需要推理的錯(cuò)誤進(jìn)行糾正。在我們一萬小時(shí)數(shù)據(jù)的實(shí)驗(yàn)中,糾錯(cuò)模型可以將基于 3gram 解碼結(jié)果的錯(cuò)字率(CER)相對(duì)降低 21.7%,取得與 RNN 重打分相近的效果。在 RNN 重打分的基礎(chǔ)上使用糾錯(cuò),可以進(jìn)一步取得 6.1% 的 CER 相對(duì)降低。誤差分析結(jié)果表明,實(shí)際糾錯(cuò)的效果比 CER 指標(biāo)顯示的要更好。
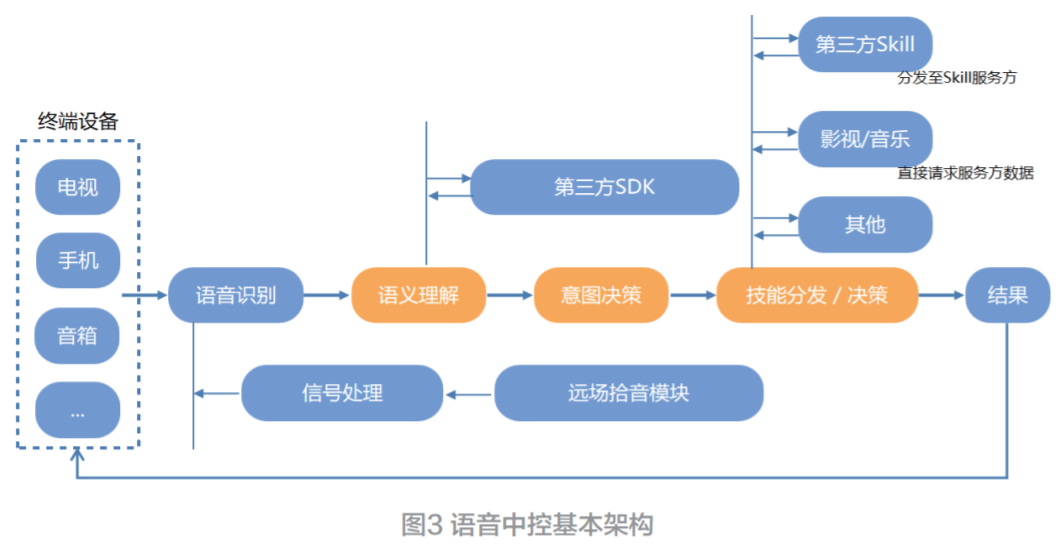
模型
1)ASR 語義糾錯(cuò)系統(tǒng)設(shè)計(jì)
ASR 語義糾錯(cuò)流程如圖 1 所示。語義糾錯(cuò)模塊可以直接應(yīng)用在第一遍解碼結(jié)果上,作為重打分模塊的替代方案。另外,它也可以接在重打分模型之后,進(jìn)一步提升識(shí)別準(zhǔn)確率。

Figure1 集成語義糾錯(cuò)模型的 ASR 系統(tǒng)
2)基線 ASR 系統(tǒng)
作者選取的 baseline 聲學(xué)模型結(jié)構(gòu)為 pyramidal FSMN[2],在 1 萬小時(shí)普通話音頻數(shù)據(jù)上訓(xùn)練。在第一遍解碼中使用的 WFST 由 3gram 語言模型,發(fā)音詞典,雙音素結(jié)構(gòu)以及 HMM 結(jié)構(gòu)構(gòu)成。在重打分中分別使用 4gram 和 RNN,訓(xùn)練數(shù)據(jù)為這些音頻對(duì)應(yīng)的參考文本。聲學(xué)模型和語言模型使用 Kaldi 工具 [3] 訓(xùn)練。
3)語義糾錯(cuò)模型結(jié)構(gòu)
研究者提出的語義糾錯(cuò)模型基于 Transformer [4]結(jié)構(gòu),它包含 6 層 encoder layer 和 6 層 decoder layer,建模單位為 token。在使用 Teacher forcing 方法訓(xùn)練過程中,ASR 輸出的文本輸入到模型的輸入側(cè),對(duì)應(yīng)的參考文本輸入到模型的輸出側(cè),分別使用輸入嵌入矩陣和輸出嵌入矩陣進(jìn)行編碼,使用交叉熵作為損失函數(shù)。在語義糾錯(cuò)模型推理過程中使用束搜索(beam search)進(jìn)行解碼,beam 寬度設(shè)置為 3。

Figure 2 基于 Transformer 的語義糾錯(cuò)模型
實(shí)驗(yàn)
1,糾錯(cuò)訓(xùn)練數(shù)據(jù)準(zhǔn)備
我們基線 ASR 模型的訓(xùn)練集為 1 萬小時(shí)普通話語音數(shù)據(jù),包含約 800 條轉(zhuǎn)寫文本。側(cè)試集由 5 小時(shí)混合語音數(shù)據(jù)組成,包含 Aishell, Thchs30 等側(cè)試集。為了對(duì) ASR 系統(tǒng)識(shí)別的錯(cuò)誤分布充分采樣,我們?cè)跇?gòu)建糾錯(cuò)模型訓(xùn)練數(shù)據(jù)集時(shí)采用了以下幾個(gè)技巧:
使用弱聲學(xué)模型生成糾錯(cuò)訓(xùn)練數(shù)據(jù),這里采用 10% 的語音數(shù)據(jù)單獨(dú)訓(xùn)練一個(gè)小的聲學(xué)模型,用于生成訓(xùn)練數(shù)據(jù);
對(duì) MFCC 特征增加擾動(dòng),將 MFCC 特征隨機(jī)乘上一個(gè) 0.8 到 1.2 之間的系數(shù);
將帶噪聲的特征輸入到弱聲學(xué)模型,取 beam search 前 20 條結(jié)果,并根據(jù)錯(cuò)字率閾值篩選樣本。最后,我們將篩選后的解碼結(jié)果和他們對(duì)應(yīng)的參考文本配對(duì),作為糾錯(cuò)模型訓(xùn)練數(shù)據(jù)。通過對(duì)全量音頻數(shù)據(jù)解碼,將閾值設(shè)置在 0.3,我們獲得了約 3 千萬糾錯(cuò)樣本對(duì)。
2,輸入輸出表示層
在語義糾錯(cuò)模型中,輸入和輸出的文本使用相同詞典。但是輸入文本中的錯(cuò)字相對(duì)于其規(guī)范的用法蘊(yùn)含更多的語義,而輸出文本中僅使用規(guī)范的字詞進(jìn)行表達(dá)。因此,將輸入和輸出側(cè)的 token 采用獨(dú)立的表示,更符合糾錯(cuò)任務(wù)的需求。表一的結(jié)果證明了我們的這個(gè)推論。實(shí)驗(yàn)結(jié)果表明在輸入輸出嵌入矩陣共享權(quán)重時(shí),糾錯(cuò)模型會(huì)帶來負(fù)面效果。當(dāng)輸入輸出 token 采用獨(dú)立的表示時(shí),系統(tǒng)的 CER 可以取得 5.01% 的相對(duì)降低。

3,BART vs BERT 初始化
這里,研究者預(yù)訓(xùn)練語言模型技術(shù),將它從大規(guī)模語料中學(xué)習(xí)到的語義知識(shí)遷移到糾錯(cuò)場(chǎng)景中,使得糾錯(cuò)模型在相對(duì)較小的訓(xùn)練集上獲得較好的魯棒性和泛化性。我們對(duì)比隨機(jī)初始化,BERT[5]初始化和 BART[1]初始化方法。在初始化過程中,因?yàn)?BART 預(yù)訓(xùn)練任務(wù)和模型結(jié)構(gòu)于 Transformer 相同,因此參數(shù)可以直接復(fù)用。在 BERT 初始化中,Transformer 的編碼器和****都適用 BERT 的前 6 層網(wǎng)絡(luò)參數(shù)[6]。

表二結(jié)果顯示 BART 初始化可以將基線 ASR 的錯(cuò)字率降低 21.7%,但是 BERT 初始化的模型相對(duì)隨機(jī)初始化模型的提升非常有限。我們推側(cè)這可能是因?yàn)?BERT 和語義糾錯(cuò)模型的結(jié)構(gòu)以及訓(xùn)練目標(biāo)差異過大,知識(shí)沒有得到有效地遷移。
此外,糾錯(cuò)模型對(duì)于語言模型重打分后的輸出再進(jìn)行糾正,識(shí)別率可以獲得進(jìn)一步提升。相對(duì) 4gram,RNN 重打分之后的結(jié)果,CER 可以分別相對(duì)降低 21.1% 和 6.1%。

4,糾錯(cuò)模型 vs 大語言模型
一般而言,ASR 系統(tǒng)使用更大的語言模型可以獲得更好的識(shí)別效果,但也會(huì)消耗更多的內(nèi)存資源并降低解碼效率。這里,我們?cè)谡Z音數(shù)據(jù)參考文本的基礎(chǔ)上,加入大量爬蟲或者開源的純文本語料,新訓(xùn)練 3gram, 4gram 和 RNN 語言模型,并稱之為大語言模型。基線 ASR 系統(tǒng)中使用的稱為為小模型。對(duì)比發(fā)現(xiàn),在小模型基礎(chǔ)上加上糾錯(cuò)的識(shí)別準(zhǔn)確率超越了單獨(dú)使用大模型的效果。另外,在大模型的基礎(chǔ)上使用語義糾錯(cuò),識(shí)別率可以獲得進(jìn)一步提升。

部分糾錯(cuò)示例如下:

5,誤差分析
在對(duì) 300 條糾正失敗的例子進(jìn)行誤差分析時(shí),我們發(fā)現(xiàn)語義糾錯(cuò)實(shí)際效果要比 CER 指標(biāo)評(píng)估的明顯要好,有約 40% 的錯(cuò)誤幾乎不影響語義,比如,一些音譯的外國(guó)人名或者地名有多種表達(dá)方式,一些人稱代詞因?yàn)槿狈ι舷挛模瑫?huì)造成“她他它“的混用,還有一些是不影響語義的語氣詞替換。另外有 30% 的錯(cuò)誤因?yàn)樯舷挛男畔⒉蛔悖贿m合基于純文本特征的模型做糾正。剩下有 30% 的錯(cuò)誤為語義糾錯(cuò)模型的語義理解或表達(dá)能力不足所致。

總結(jié)
本文提出了一種基于 BART 的語義糾錯(cuò)模型,它具有良好的泛化性,對(duì)多種 ASR 系統(tǒng)的識(shí)別結(jié)果有一致性地提升。另外,研究者通過實(shí)驗(yàn)驗(yàn)證了在文本糾錯(cuò)任務(wù)中,輸入輸出采用獨(dú)立表示的重要性。為了更充分地對(duì) ASR 系統(tǒng)識(shí)別錯(cuò)誤分布進(jìn)行采樣,本文提出了一種簡(jiǎn)單有效的糾錯(cuò)數(shù)據(jù)生成策略。
最后,我們提出的語義糾錯(cuò)方法雖然取得了一定收益,但還有可以優(yōu)化的空間,比如:
1,引入聲學(xué)特征,有助于模型辨識(shí)文本是否存在錯(cuò)誤,降低誤觸率。
2,引入更多上下文信息,可以消除文本中一些語義上的歧義或者缺失的信息。
3,針對(duì)垂直業(yè)務(wù)場(chǎng)景進(jìn)行適配,提升一些專業(yè)術(shù)語的識(shí)別準(zhǔn)確率。
參考文獻(xiàn)
[1]M. Lewis et al., “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension,” 2019, [Online]. Available: http://arxiv.org/abs/1910.13461.
[2]X. Yang, J. Li, and X. Zhou, “A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition,” vol. 1, Oct. 2018, [Online]. Available: http://arxiv.org/abs/1810.11352.
[3]D. Povey et al., “The Kaldi Speech Recognition Toolkit,” IEEE Signal Process. Soc., vol. 35, no. 4, p. 140, 2011.
[4]A. Vaswani et al., “Attention Is All You Need,” Jun. 2017, doi: 10.1017/S0140525X16001837.
[5]J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” 2018, [Online]. Available: http://arxiv.org/abs/1810.04805.
[6]O. Hrinchuk, M. Popova, and B. Ginsburg, “Correction of Automatic Speech Recognition with Transformer Sequence-to-sequence Model,” ICASSP 2020 - 2020 IEEE Int. Conf. Acoust. Speech Signal Process., pp. 7074–7078, Oct. 2019, [Online]. Available: http://arxiv.org/abs/1910.10697.
*博客內(nèi)容為網(wǎng)友個(gè)人發(fā)布,僅代表博主個(gè)人觀點(diǎn),如有侵權(quán)請(qǐng)聯(lián)系工作人員刪除。