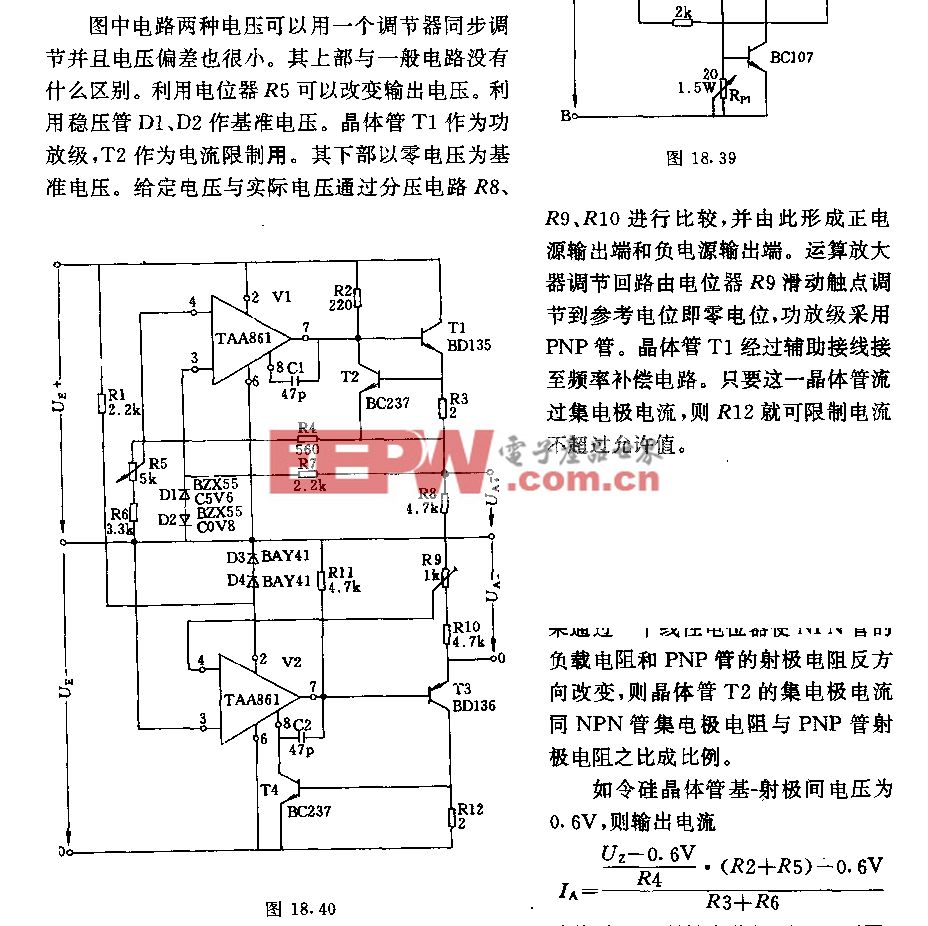
北大、微軟提出NGra:高效大規模圖神經網絡計算

目前,深度學習技術通常以深度神經網絡(DNN)的形式展現。由于其在語音、視覺和自然語言處理等領域所取得的成功,深度學習技術越來越受歡迎。在這些領域中,底層數據表征的坐標通常具有規則的網格結構,這有利于包含大量類似于單指令多數據流(SIMD)數據并行運算的硬件加速機制(例如 GPU)。
目前,將深度學習模型應用在具有不規則圖結構的數據上成為了一種新興的趨勢 ,這種趨勢是由諸如社交網絡、知識圖譜、以及生物信息學和神經科學(例如,蛋白質之間的交互或大腦中的神經元連接)中的圖形的重要性所驅動的。這種趨勢也促使人們在其目標應用(例如,分類、嵌入、問答系統)上取得了當前最佳的結果。這些基于圖的神經網絡(GNN)通常將神經網絡模型應用在圖中與頂點和邊相關的特征上,傳播運算結果并進行聚合,從而生成下一級的特征。
現有的解決方案都不能很好地支持 GNN。現有的圖處理引擎往往會提供一個類似于信息收集(Gather)——應用(Apply))——結果分發(Scatter)的 GAS 頂點程序模型,但這種方式無法在圖結構中表達和支持神經網絡架構。TensorFlow、PyTorch、MxNet[8]、CNTK等深度學習框架旨在將神經網絡表示為數據流圖,但并不直接支持圖傳播模型。此外,它們都不能提供處理大型圖所需的可擴展性,也不支持基于 GPU 的圖傳播 operator(將圖傳播轉換為稀疏操作)的高效實現。當前缺乏對這些需求的支持嚴重限制了充分挖掘大規模 GNN 潛力的能力,同時也為 DNN 與大型圖結構的結合在系統層面上提出了巨大的挑戰。
在本文中,作者介紹了首次實現支持大規模 GNN 的 NGra 系統,它從一個易于表達的編程模型發展到一個可擴展的、高效 GPU 并行處理引擎。NGra 將數據流與頂點程序的抽象自然地結合在了一個名為 SAGA-NN(Scatter-Apply Edge Gather-Apply Vertex with Neural Networks)的新模型中。SAGA 可以被認為是一個 GAS 模型的變體,SAGA-NN 模型中由用戶定義的函數使用戶能夠通過使用數據流抽象(而不是使用那些為處理傳統圖問題如 PageRank、連通分量、最短路徑而設計的算法)在頂點或邊數據(以張量形式被處理)上表達神經網絡計算。
與在深度神經網絡上的情況一樣,高效使用 GPU 對 GNN 的性能至關重要,而且由于處理大型圖結構的額外挑戰,對 GPU 的使用就顯得更為關鍵了。為了實現超越 GPU 物理限制的可擴展性,NGra 顯式地將圖結構劃分(頂點和邊數據)成塊,將一個在 SAGA-NN 模型中表達的 GNN 算法轉成了具有塊粒度 operator 的數據流圖,通過該數據流圖,作者可以在單個或多個 GPU 上進行基于塊的并行流處理。
然后,NGra 引擎的效率在很大程度上取決于 NGra 如何管理和調度并行流的處理過程,以及如何在 GPU 上實現關鍵的圖傳播 operator(結果分發和信息收集)。NGra 十分關注數據的位置,從而盡量減少 GPU 內存內外的數據交換,最大限度地提高 GPU 內存中數據塊的重用性,同時以流形式同時進行數據遷移和計算。對于多 GPU 的情況,它使用了一種基于環的流機制,通過在 GPU 之間直接交換數據塊來避免主機內存中的冗余數據遷移。SAGA-NN 模型中的結果分發和信息收集階段執行沿著邊的頂點數據傳播,在稀疏結構上表現為矩陣乘法。眾所周知,在像 GPU 這樣數據并行的硬件上執行稀疏的矩陣操作是非常困難的。因此,NGra 將圖傳播引擎支持的特殊 operator 引入到數據流圖中,并優化其在 GPU 上的執行。請注意,與其 基于 GPU 的圖引擎所關注的傳統圖處理場景不同,在 GNN 的場景下,由于每個頂點的數據可能就是一個特征向量,而不是簡單的標量,可變頂點數據本身可能無法被容納到 GPU 設備內存中。因此,本文的方案更傾向于利用每個頂點數據訪問中的并行性來提高內存訪問效率。
作者使用頂點程序抽象和用于圖傳播過程的自定義 operater 對 TensorFlow 進行擴展,從而實現 NGra。結果證明 NGra 可以被擴展,然后通過利用單個服務器的主機內存和 GPU 的計算能力,實現在(包含數百萬頂點和數百特征維度以及數億邊的)大型圖上對 GNN 算法的支持,而這不能直接通過使用現有的深度學習框架實現。與可以通過 GPU 支持的小型圖上的 TensorFlow 相比,NGra 可以取得大約 4 倍的運算加速。作者還對 NGra 中的多個優化所帶來的性能提升進行了廣泛的評估,以證明它們的有效性。

圖 1:雙層 GNN 的前饋運算過程

圖 3:GNN 中每一層的 SAGA-NN 運算流程
NGra 系統
NGra 以用戶接口的形式提供了數據流和定點程序抽象的組合。在這種抽象之下,NGra 主要由以下幾部分組成:(1)一個將 SAGA-NN 模型中實現的算法轉換為塊粒度數據流圖的前端,它使得大型圖上的 GNN 計算可以在 GPU 中被實現;(2)一個制定最小化主機與 GPU 設備內存之間數據遷移調度策略的優化層,它能夠找到進行融合操作和去除冗余計算的機會;(3)一組高效的傳播操作內核,它支持針對 GPU 中重復的數據遷移和計算的基于流的處理;(4)在運行時執行數據流。由于 NGra 在很大程度上利用了現有的基于數據流的深度學習框架來實現在運行時執行數據流,因此作者將重點放在本節前三個框架的設計上,因為它們是 NGra 系統的主要貢獻。

圖 4:用于 G-GCN 層上目標區間 V0 的基于塊的數據流圖。為了得到更清晰的可視化結果,在連接到 D2H 時,SAG 階段輸出張量置換被隱藏在了 SAG 的子圖中。

圖 13:TensorFlow(TF),cuSPARSE,以及 NGra(NG)在不同密度的圖上傳播內核的時間。

圖 16:在大型圖上的不同應用中使用 NGra 的加速情況
論文:Towards Efficient Large-Scale Graph Neural Network Computing

論文地址:https://arxiv.org/abs/1810.08403
最近的深度學習模型已經從低維的常規網格(如圖像、視頻和語音)發展到了高維的圖結構數據(如社交網絡、大腦連接和知識圖譜)上。這種演進催生了基于大型圖的不規則和稀疏模型,這些模型超出了現有深度學習框架的設計范圍。此外,這些模型不容易適應在并行硬件(如 GPU)上的有效大規模加速。
本文介紹了基于圖的深度神經網絡(GNN)的第一個并行處理框架 NGra。NGra 提出了一種新的 SAGA-NN 模型,用于將深度神經網絡表示為頂點程序,其每一層都具有定義好的(結果分發、應用邊、信息收集、應用頂點)圖操作階段。該模型不僅可以直觀地表示 GNN,而且便于映射到高效的數據流表示。NGra 通過自動圖形劃分和基于塊的流處理(使用 GPU 核心或多個 GPU),顯式地解決了可擴展性的挑戰,它仔細考慮了數據位置、并行處理和數據遷移的重疊等問題。NGra 雖然是稀疏的,但通過對 GPU 上的結果分發/信息收集 operator 進行高度優化,進一步提高了效率。本文的評估結果表明,NGra 可以擴展到任何現有框架都無法直接處理的大型真實圖結構上,同時即使是在小規模的 TensorFlow 的多基線設計上,也可以實現高達 4 倍的加速。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。