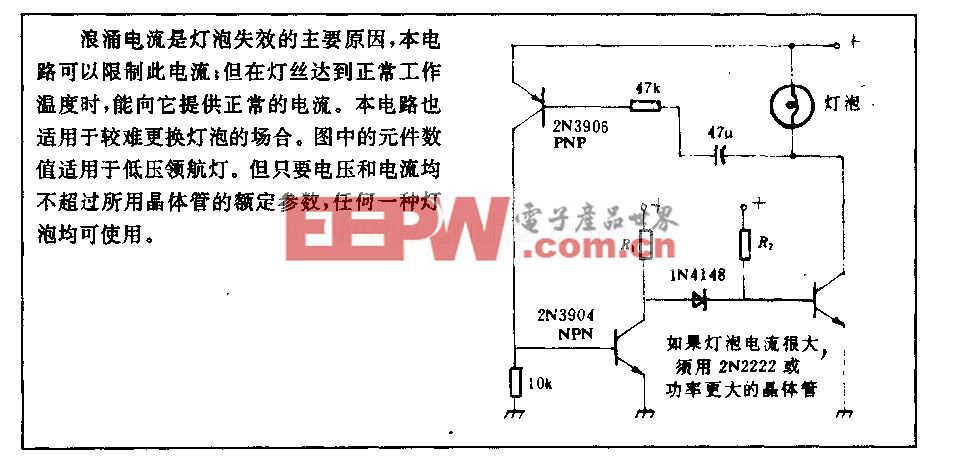
OpenAI新模型曝光:給它半張圖片,能夠猜測補全

如今,該實驗室正在探索若在相同的算法中輸入某張圖片的一部分會發生什么。在本周的機器學習國際會議(ICML 2020)上,這一研究成果獲得了最佳論文的榮譽稱號,為圖像生成開辟了一條新的路徑。
GPT-2 的核心其實是一個強大的預測引擎。它通過查看從互聯網各處搜索得來的數十億單詞、句子和段落,學習并掌握了英語這門語言的結構。掌握了這一結構,GPT-2 就可以從統計學的角度預測單詞出現的順序,從而操縱單詞,將不同的單詞組成新的句子。
因此,OpenAI 的研究人員決定將單詞換成像素,在 ImageNet(最受歡迎的深度學習圖像庫)上用圖片訓練相同的算法。由于該算法最初是為處理一維數據(例如文本字符串)而設計的,于是研究人員將圖片展開為單像素序列。他們將新模型命名為 iGPT,發現它可以理解視覺世界的二維結構。提供給該模型某張圖片上半部分的像素序列,它就可以合乎情理地預測出圖片的下半部分。
iGPT 的這一訓練結果讓人非常吃驚,它展示了開發計算機視覺系統的一條新路徑,即利用在無人為標簽的數據上進行訓練的無監督學習。事實上,2005 年左右,早期的計算機視覺系統就曾試用過這一技術,但由于當時使用人為標簽數據的監督學習更為成功,這一技術就遭到了冷落。但是,無監督學習的優勢就在于 AI 系統可以在沒有人工過濾器的前提下去了解世界,大大減少了標記數據的體力勞動。
iGPT 與 GPT-2 使用相同算法的,這一事實也顯示了 iGPT 具有良好的適應能力。這也與 OpenAI 的最終目標一致,即創造出更通用的機器智能。
同時,該方法為生成深度偽造圖片提供了一種新思路。在過去,生成式對抗網絡(GAN)是生成深度偽造圖片最常用的算法類別,必須用高度精確的數據進行訓練。例如,若想用 GAN 生成一張臉,那么訓練的數據也只能是臉。相反,iGPT 通過數百萬和數十億的圖片學習了視覺世界的結構,從而可以生成極有可能真實存在的圖片。雖然從計算層面上來看,訓練這一模型成本太過昂貴,為其進入圖像庫設下了一道天然的屏障,但這一問題在不久的將來很快就可以得到解決。 OpenAI 沒有接受采訪,但在《麻省理工科技評論》去年參加的一次內部政策小組會議上,其政策總監杰克·克拉克(Jack Clark)對 GPT 式生成模型未來存在的風險進行了思考,包括將其應用于圖像領域會發生什么。他基于自身所見,預測了該領域的研究軌跡走向并說到,“很快會應用到視頻。大概再過 5 年,就可以在 5 到 10 秒的間隔內完成條件視頻生成。”接著,他描述了自己想象的情景:輸入一張政客的照片,照片上政客的旁邊發生了爆炸,該模型就很可能輸出該政客被謀殺的信息。
*博客內容為網友個人發布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。