利用多目標(biāo)建模技術(shù)降低ECU軟件成本
 加入技術(shù)交流群
加入技術(shù)交流群

掃碼加入
和技術(shù)大咖面對(duì)面交流
海量資料庫查詢
圖2就是具有數(shù)據(jù)對(duì)象的工作區(qū)例子。可以賦于數(shù)據(jù)對(duì)象的數(shù)據(jù)屬性包括了初始值、數(shù)據(jù)類型、存儲(chǔ)類、描述、最小和最大值等。除此之外,還可以賦于定點(diǎn)屬性,如字長度、小數(shù)長度或二進(jìn)制小數(shù)點(diǎn)、有符號(hào)或無符號(hào)等等。使用數(shù)據(jù)對(duì)象進(jìn)行仿真和代碼生成的通用模型如圖3所示。這些例子描述的技術(shù)并不代表Visteon公司專有的產(chǎn)品數(shù)據(jù)或模型。
本文引用地址:http://www.104case.com/article/82873.htm 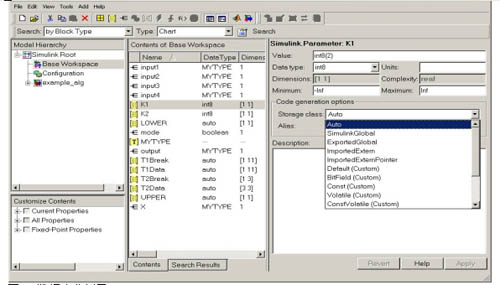
圖2:數(shù)據(jù)字典例子。
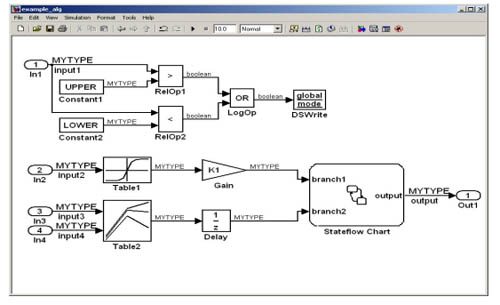
圖3:通用模型例子。
在建立通用模型后,Visteon公司的軟件工程師就要為他們需要的目標(biāo)架構(gòu)創(chuàng)建并換成特定的數(shù)據(jù)字典,然后使用這個(gè)數(shù)據(jù)字典進(jìn)行仿真和代碼生成。然而,創(chuàng)建一個(gè)優(yōu)秀的定點(diǎn)數(shù)據(jù)字典需要花很長的時(shí)間,這是因?yàn)樵诖_定換算系數(shù)時(shí)需要做多方面的折衷考慮。工程師需要選擇能夠提供足夠精度但在已知范圍內(nèi)的換算系數(shù)。如果換算系數(shù)的選擇不夠充分,那么當(dāng)結(jié)果超過字長時(shí)可能發(fā)生數(shù)字上溢或下溢。
在選擇換算系數(shù)時(shí)自動(dòng)換算工具被證明是非常有用的。這些工具能夠非常容易地確定仿真期間是否會(huì)發(fā)生上溢或下溢。圖4是來自Simulink定點(diǎn)用戶接口工具的輸出例子。在這個(gè)例子中,數(shù)據(jù)記錄顯示了仿真過程中信號(hào)獲得的最小和最大值。在這種情況下,所有信號(hào)都在范圍之內(nèi)。如果發(fā)生上溢或飽和,數(shù)據(jù)記錄會(huì)標(biāo)志這一事件,從而促使設(shè)計(jì)工程師調(diào)查問題原因,并選擇新的正確的換算系數(shù)。
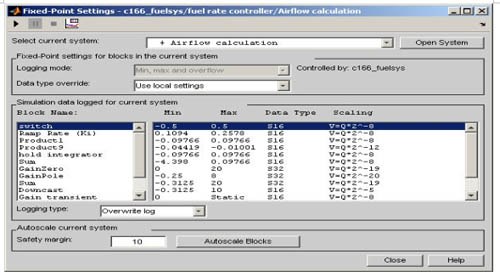
圖4:自動(dòng)換算工具和記錄結(jié)果例子。
如果需要額外的保護(hù),設(shè)計(jì)師可以使用由Simulink在模塊參數(shù)對(duì)話框中提供的飽和設(shè)置在計(jì)算中增加上溢保護(hù)。飽和檢查對(duì)生成代碼的效率來說非常重要,下面的結(jié)論部分將提到這一點(diǎn)。
產(chǎn)品ECU程序的結(jié)果
Visteon動(dòng)力系統(tǒng)實(shí)現(xiàn)了用于發(fā)動(dòng)機(jī)管理系統(tǒng)的產(chǎn)品化浮點(diǎn)和定點(diǎn)的應(yīng)用。對(duì)開發(fā)過程來說最大的好處是顯著減少了時(shí)間和成本。在有個(gè)案例中,Visteon公司在三個(gè)月內(nèi)就完成了ECU軟件的開發(fā),如果采用手工編碼方案的話起碼要6個(gè)月。
與人工編碼相比,浮點(diǎn)自動(dòng)代碼的效率也有所提高,使用的RAM和ROM空間要少5%左右。定點(diǎn)自動(dòng)代碼效率幾乎接近手工編碼效率。在對(duì)導(dǎo)航程序中定點(diǎn)代碼的初始分析過程中,Visteon公司將對(duì)前面討論過的飽和檢查進(jìn)行確認(rèn),這將對(duì)定點(diǎn)代碼效率起關(guān)鍵作用。如果每次定點(diǎn)計(jì)算都激活了飽和檢查,那么代碼長度會(huì)有顯著增加。然而,如果象在手工編碼中做的那樣只在需要時(shí)做飽和檢查,那么生成代碼所需的RAM和ROM空間基本上等于手工編碼所需的空間。
另外需要注意的是,為了確保獲得高質(zhì)量的代碼,開發(fā)人員仍要使用靜態(tài)分析工具和MISRA檢查器對(duì)自動(dòng)代碼進(jìn)行檢查。
linux操作系統(tǒng)文章專題:linux操作系統(tǒng)詳解(linux不再難懂)





評(píng)論