多核計算機的程序設計

采用多核處理器芯片構成計算機系統是一個片內多處理器的并行計算機系統。這種并行計算機系統過去只出現超級計算中心和集群計算機系統中。現在,隨著處理器芯片進入多核時代,使得千家萬戶的計算機系統都成為多處理器的并行計算機系統。這種并行計算機系統是一種并行進程和并行線程的系統,多個進程和線程可以真正地并行運行,而不是像在單處理器系統中那樣輪流地在CPU上運行。但是在多核系統中,原有的單個程序的運行速度并不能得到提高。要提高單個程序的運行性能,需要重新設計原有程序,將單個計算任務分解成多個并行的子任務,讓這些子任務分別在不同的處理器核上運行。這樣,需要采用不同的程序設計手段。隨著多核時代的到來,并行程序設計將成為軟件行業的必備知識和技能。

多核與程序設計
與單處理器系統不同,運行在多處理器系統中的程序是多線程的程序。這種程序必須是可重入的,即程序代碼能夠被重疊地啟動并且同時運行在多個上下文中,這些運行上下文構成多個線程。代碼的可重入意味著在多次進入同一段代碼的線程之間避免競態(race condition)現象。競態現象發生在對資源的共享訪問情況下。當兩個運行的線程需要訪問相同的數據結構或硬件資源時,兩個線程會因為資源的共享而相互干擾。為避免競態,需要建立起線程間的通信和同步機制。
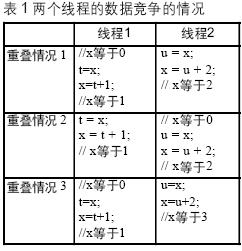
數據競爭出現在兩個數據相關的線程之間。這時,線程的運行結果與線程的運行順序有關。例如,對于以下兩個線程:
// 線程1
t = x;
x = t + 1;
// 線程2
u = x;
x = u + 2;
兩個線程的并行運行情況有以下三種可能,導致三種不同的結果,使得x的分別為1、2和3,如表1所示。解決這個問題需要采用同步機制和互斥機制。同步機制是并行系統中保持各并行程序正確運行的必要的控制機制。它用于在并行的線程之間進行時間上的協調。互斥機制則是實現同步機制的基礎。在單處理器系統中,這種機制可以建立在存儲器變量的基礎上。在單處理器系統中,線程的訪存操作本身就是一種互斥的機制。而在多核系統中,這種機制需要通過存儲器一致性機制和現成通信機制來實現。
并行程序的概念
多處理器系統并行程序設計中需要進行任務劃分、數據劃分和數據流劃分。任務劃分的目的是使得各個處理器都能分配到平衡的工作負載,從而提高運算的并行性。數據劃分是將數據對象劃分成多個并行處理的數據子集。數據流劃分是根據數據的處理過程進行劃分,在不同的處理階段進行不同的數據劃分。
以下用兩個例子分別介紹在共享存儲器和分布存儲器多處理器系統進行上節中對64000個數據累加的方法。在共享存儲器系統中,假定有8個處理器以單總線方式連接。在求和運算時,數據A存儲在集中共享的存儲器中,每個處理器對共享數據中的劃分成不同子集進行訪問和累加。設Pn為處理器數,所有處理器通過分別運行以下程序對子集中的數據進行部分和計算:
sum[Pn]=0;
for(i=8000*Pn;i<8000*(Pn+1);i=i+1)
sum[Pn]=sum[Pn]+A[i]; /* sum the assigned areas */
這個循環將子集的數據從共享存儲器中取出。然后將數據與部分和相加,形成部分和之后再求得總和。每個處理器的部分和也存放在共享的存儲器中,用一個數組sum[]表示這些部分和。
求總和的程序段必須在各個處理器的部分和都計算完成時才開始進行,因此需要一種同步機制來協調程序的執行時間。在并行程序中,必須明確規定關鍵點的同步。對于本例,求總和的程序可以采用synch()函數進行同步操作。synch()函數是一個屏障同步函數,它使得所有處理器中的有關線程都執行到這一點時才繼續執行以后的指令,先到達同步點的線程必須等待。即當一個或部分線程調用這個函數時,函數不返回,只有當所有的線程都調用了這個函數時,這個函數才返回,使得所有的線程都可以進行下一步的操作。
在分布消息傳遞型多處理器系統中,假設有64個處理器,通過某種互連網絡相互連接。進行上述求和運算的第一步是進行數據劃分,將數據子集分發到各局部存儲器中,數據子集存儲在各局部存儲器中后成為數組A1。計算步驟是先計算部分和,然后對部分和計算總和,程序為:
sum=0;
for(i=0;i<1000;i=i+1) /* loop over each array */
sum=sum+A1[i]; /* sum the local arrays */
limit=64;
half=64; /* 64 processors in this MIMD */
do {
half=half/2; /* send vs. receive dividing line */
if(Pn>=half && Pn<limit) send(Pn%half,sum);
if(Pn<half) sum=sum+receive();
limit=half; /* upper limit of senders */
} while (half>1); /* exit with final sum */
該程序同時運行在多個進程或處理器中,因為都是在不同的地址空間訪問數據,通過消息發送操作傳遞數據。程序的前三行計算部分和,后七行對部分和進行求和。為了匯集各個進程的部分和,這里程序將所有的處理器分成發送方和接收方,編譯程序需要將send函數轉換成對發送消息的庫函數調用,將receive函數轉換成對接受消息的庫函數調用。
并行程序的實現
并行程序中,任務的劃分可以由程序員完成,也可以由編譯程序完成。一般而言,實現并行程序設計的方法有3種:
1. 庫函數。庫函數方法在串行程序的標準庫的基礎上增加新的支持并行操作的函數。如MPI的消息傳遞庫和POSIX的Pthread多線程庫。庫函數方法比較容易實現,不需要改變編譯程序。但是程序中的并行性問題沒有經過編譯程序的檢查、分析、優化。程序設計的難度較大,容易出現錯誤。
2. 新的語言構造。在原有的程序設計語言中增加新的構造語句,以表達并行的操作。在對并行構造語句進行分析的時候,編譯程序可以進行檢查,發現并行運行中存在的問題和錯誤。但是這種方法需要采用新的編譯程序,并且增加了編譯程序的復雜性。
3. 編譯指導。在原有的語言中增加表達并行運算的編譯指導語句。編譯指導語句能夠被并行編譯程序識別,串行編譯程序則忽略這些語句。并行編譯程序跟據這些指導語句將相關代碼轉換成在并行計算機中運行的代碼。這種方法的例子如OpenMP。這種方法的特點是介于上述兩種方法之間。
多線程的編程需要利用操作系統或者軟件開發環境提供的庫函數實現線程操作,線程操作函數包括線程的創建和消除、線程的啟動運行和終止運行、線程同步機制的建立和刪除、線程互斥機制的建立和刪除、臨界區機制的建立和刪除等。最常見的創建新進程或者新線程的機制是分叉和匯集(fork-join),調用fork函數創建一個新的進程或線程并制定進程或線程的執行入口,調用join函數則可以結束新進程或新線程的執行。在并行線程的程序設計中,程序員需要安排線程的創建、線程的同步和線程間的通信等,需要考慮到同一段代碼將在多個線程中同時運行而不能相互影響。因此,在采用庫函數方式下,多線程程序設計是對程序員的一個挑戰。
一般情況下,在消息傳遞型多處理器系統中,每個處理器執行的是各不相同的程序。每個結點上運行的進程或線程的程序代碼都要由程序員分別編寫,進程和線程之間的通信通過MPI消息傳遞函數庫實現。程序員需要安排好每個結點的程序中消息的發送和對應的接收函數的調用,否則就會造成處理器間的等待,甚至死機。因此程序設計的工作量很大,而且程序的調試工作十分復雜。
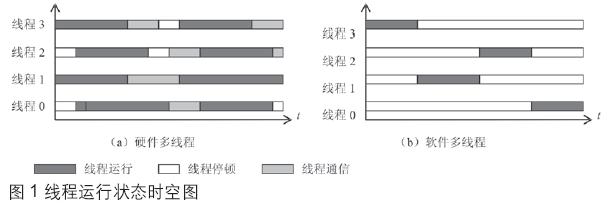
多線程的并行運行可以在單個處理器上進行,形成軟件多線程;也可以在支持多線程的處理器核、多個處理器核或者多個處理器芯片上運行,形成硬件多線程。多線程的運行情況可以用線程運行狀態時空圖來表示。圖1是較宏觀的線程時空圖的一個例子。圖中用不同的灰度的條形圖表示線程所處的不同狀態。其中,線程通信時間包括線程等待鎖的時間、同步操作花費的時間和消息發送與接收的時間。在軟件多線程方式下,各個線程輪流地使用處理器核資源。這一點在線程運行狀態時空圖上可以清楚地看到,同一個核上的線程運行的狀態相互不會出現重疊的情況,線程之間的通信也不是通過互連網絡直接進行的,而是通過緩存空間進行。在硬件多線程中,運行在多個邏輯處理器上的多線程具有不同的硬件資源,構成真正的并行運行方式。
OpenMP與多核程序設計
OpenMP標準在1997年形成,作為編寫可移植的多線程應用程序的API。OpenMP是對基本語言的擴展,標準內容可以從www.openmp.org上獲得。OpenMP適用于共享存儲器的多處理器系統,線程間通過共享變量傳遞數據結果。
OpenMP的程序設計模型提供了一種與平臺無關的編譯指導命令(pragma)、編譯指示符、函數調用和環境變量,顯式地告訴編譯程序在應用程序如何使用并行性,在哪里使用并行性。它提供了一個編寫可移植的多線程應用程序的API,可以實現循環程序的多線程化。許多循環程序可通過插入一條pragma變成多線程的,只要相關性不妨礙程序的并行執行。OpenMP支持多線程間的同步和局部數據變量,它采用分叉和匯集(fork-join)的執行模式建立多線程,使得編譯和運行庫能夠有效地編譯和運行程序,減少線程執行的開銷。通過將實現細節留給編譯程序和實時運行庫,程序員不需要對線程的創建和刪除進行編程,可以將精力集中于確定哪些循環程序段需要并行化,以及如何測試并行線程的性能。程序員不需要對線程的同步操作進行詳細編程,也不需要在程序中增加大量的代碼來創建、初始化、管理和終止線程以實現并行性。用戶對串行程序添加編譯指導命令的過程就類似于進行顯式并行程序設計。
OpenMP可以對循環程序進行按循環迭代的任務劃分,創建多個線程,每個線程完成若干個循環迭代的計算子任務。例如,以下循環程序是加入了OpenMP編譯指導的程序:
#pragma omp parallel for
for (i=0; i<MAX; i++)
A[i] = c*A[i] + B[i];
其中,pragma表示編譯指導命令,表示這是一條編譯指令;omp表示它是OpenMP的編譯指令,采用OpenMP的規范;parallel表示對下面一條語句進行并行化,表示多線程并行代碼區域的開始;for表示對for循環語句進行多線程分解。這樣,這段程序將被生成多個線程的代碼。每個線程完成循環中的一個迭代。對于多重循環,OpenMP只能將最外層的循環分解成并行多線程,OpenMP的循環程序分解不能嵌套進行。
在大的應用程序中,關鍵的循環體中常常有遞歸操作。循環程序中最常見的相關性是遞歸相關性。為此,OpenMP提供了一種遞歸(reduction)子句,它有效地結合一些變量的算術遞歸運算對循環中的變量進行計算。對于存在遞歸相關性的情況,可以采用遞歸的編譯指令reduction。例如,對于以下求和的遞歸循環程序:
sum = 0;
for (i=0; i < 100; i++)
{
sum += array[i];
}
如果分解成多個線程的話,sum變量就是線程之間的共享變量。可以加入遞歸的OpenMP編譯指令,變成:
sum = 0;
#pragma omp parallel for reduction(+;sum)
for (i=0; i < 100; i++)
{
sum += array[i];
}
這時,OpenMP能夠處理各個線程對共享變量的訪問互斥性,不需要應用程序員操心。
在編寫多線程程序時,理解哪些數據是共享的、哪些數據是私有的成為一個極其重要的問題。OpenMP將這種區別通過一套子句呈現給程序員,例如shared、private和default。OpenMP還可以有條件地進行并行執行,方法是使用if子句,該子句可以被加到任何并行結構上。如下面的例子中,在循環次數大于16時才啟動并行線程,以避免多線程帶來的開銷:
#pragma omp parallel for if(n>=16)
for ( k = 0; k < n; k++ ) fn2(k);
一個循環程序可以分解成大量的線程,將這些線程分配給處理器時需要考慮各處理器的負載平衡,使得所有的處理器差不多同時完成各自的線程,良好的負載平衡可以獲得最佳的并行處理性能,程序中必須進行有效的循環程序的線程調度和劃分。OpenMP能夠自動根據運行的環境確定最佳線程的數量,以實現使用任意個數線程都能具有良好性能的程序。因此,OpenMP是一個容易入門的多線程程序設計手段。
并行程序軟件工具
并行程序設計環境包括并行程序調試器。并行程序調試器應當能夠通過對程序代碼的分析發現程序中問題,應當能夠快速準確地定為這些問題。對并行程序的分析包括數據相關性分析、鎖的分析等,分析出并行程序中的數據競爭現象和死鎖現象等程序員難以看出的問題。集群系統的調試器是一種能夠在跨平臺、異構開發環境中的使用的并行程序開發工具。
并行程序的優化包括分析程序中各個函數之間的調用關系,從而分析程序中的關鍵調用路徑;分析程序中的熱點,即執行時間最長地函數;分析線程的負載平衡情況等。多線程的程序中包含多個執行流,這些執行流在同步點上是相互相關的。關鍵路徑是其中執行時間最長的執行路徑。例如,對于圖2(a)所示的線程執行流,在時間軸上的關鍵路徑的例子如圖2(b)所示,其中關鍵路徑用特粗線表示,中粗線表示非關鍵路徑上執行的線程,細線表示空閑的線程。良好的并行程序設計環境應當能夠分析出這種關鍵路徑,從而為程序減少程序的總體執行時間提供幫助。在圖3示的線程流程圖上,線程1是貫穿整個執行流程的線程,成為主線程。其余線程是在需要并行執行的期間建立的線程,成為子線程。

分析線程的運行狀態對于優化多線程程序設計十分重要,這種分析有助于程序員了解哪些程序段是影響整個程序運行時間的關鍵。從線程之間關系的角度,可以將線程的運行狀態分成以下4種:
·巡航狀態。這時線程處于獨立的執行狀態,保持高速運行,線程的運行不受其他線程的影響,也不影響其他線程的運行。
·開銷狀態。這是線程操作的開銷,如線程的創建、關閉等。
·阻塞狀態。這時線程正在等待外部事件,如同步和通信的等待。
·影響狀態。這時線程處于執行狀態,它阻礙了其他線程的執行,其他線程正在等待該線程。
線程的并行化狀況反映系統中創建的線程數量,可以分成空閑(idel)、串行(serial)、偏少(under-subscribed)、并行(parallel)和偏多(oversubscribed)幾種情況。程序員在調試程序中去分析這種線程數量狀況是一件煩瑣的事情,通常借助于并行程序調試工具。
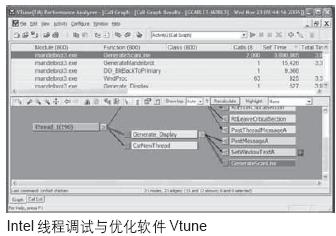
支持這種線程調試和優化軟件工具如Intel的Vtune。Vtune是一個性能測試工具軟件,能夠從程序的試運行中收集系統性能數據,顯示出性能數據的時空圖,包括顯示函數調用關系圖和程序中的熱點。通過這個軟件工具,可以對各種計算機系統的軟件性能進行分析測試,包括各種采用Intel系統結構的嵌入式系統和多核的桌上型計算機系統,從而對并行程序進行調試和優化。該軟件具有Windows版本和Red Hat Linux版本。
Vtune使用高級性能分析技術查找性能瓶頸,能夠提供程序流程的圖形化視圖,以幫開發人員快速確定關鍵函數和調用順序并獲得程序執行情況的高級別算法視圖。Vtune能夠對程序的運行中進行實時采樣,經過分析后顯示出線程的關鍵路徑(critical path view),可以在線程時空圖上標出線程的運行狀態(timeline view),可以統計出線程在各種狀態下所經歷的時間比例(profile view),還可以分析出線程并行的狀況以及時間比例(thread view)。調用關系圖中清晰地顯示出程序的流程,包括子程序調用關系以及程序的關鍵路徑。
Vtune的分析功能包括熱點分析。所謂熱點是指系統中發生大量活動的位置,如cache失效、分支預測失效、流水線停頓等。在Vtune中使用“計數器監視器”可以在運行時跟蹤系統活動與資源消耗情況,幫助快速確定系統層面的性能問題。

存儲器相關文章:存儲器原理


評論