基于FPGA的并行可變長解碼器的實現技術

可變長編碼(VLC)是一種無損熵編碼,它廣泛應用于多媒體信息處理等諸多領域。在H.261/263、MPEG1/2/3等國際標準中,VLC占有重要地位。VLC的基本思想是對一組出現概率各不相同的信源符號,采用不同長度的碼字表示,對出現概率高的信源符號采用短碼字,對出現概率低的信源符號采用長碼字。Huffman編碼是一種典型的VLC,其編碼碼字的平均碼長非常接近于數據壓縮的理論極限——熵。
本文引用地址:http://www.104case.com/article/80914.htm可變長解碼(VLD)是VLC的逆過程,它從一組連續的碼流中提取出可變長碼字,并將之轉換為對應的信源符號。由于在VLC過程中,碼字之間通常不會加入任何分隔標識,這就造成了在解碼過程中識別碼字的困難。因此,在VLD過程中,變長碼字必須逐一識別,只有碼流中居前的碼字被識別之后,才能定位后序碼字的起始位置,這一點在很大程度上限制了VLD運行的效率。
本文討論一種新型的VLD解碼結構,它通過并行偵測多路碼字,將Buffer中的多個可變長碼一次讀出,這將極大地提高VLD的吞吐量和執行效率。然后采用FPGA對這種并行VLD算法的結構進行驗證,最終得出相應結論。
1 算法描述
由于碼流中的可變長碼之間具有前向依賴性,因此如何確定可變長碼碼字在連續碼流中的起始位置是VLD的關鍵所在。傳統的VLD解碼方案主要為位串行解碼方案和位并行解碼方案兩種。
在位串行解碼方案中,碼流逐位送入解碼器,解碼器通過逐位匹配實現可變長碼的解碼。這種過程實質上是一種建造Huffman樹的反過程,從根節點出發,直至葉子節點為止。由于這種方式采用逐位操作方式,而可變長碼的碼長又各不相同,使得碼字識別所需的運行周期也不相同。在解碼長較短的碼字時,其解碼速度較快,而在解碼長較長的碼字時,其解碼速度較慢。顯然,位串行解碼方案效率相對較低,解碼速度因碼字長度不同而不同,無法滿足某些對實時性要求較高的應用場合。
針對位串行解碼方案的不足,多種位并行解碼方案被提出。位并行解碼方案采用并行方式工作,通過對可變長碼的碼字進行排序(Ordering)、分割(Partitioning)和簇化(Clustering),采用基于邏輯塊的匹配模式中其它樹的匹配模式來實現。并行解碼方案大大提高了可變長碼的解碼效率,而且可以確何每個運行周期輸出一個解碼碼字,實現穩定的解碼輸出。在高級的位并行解碼方案中,還可以將解碼過程分解為若干階段,引入流水線操作,進一步提高解碼效率。
在傳統的VLD解碼方案的基礎之上,采用并行操作方式,增加硬件資源和相應的控制邏輯,可實現一個運行周期輸出多個解碼碼字,使可變長碼的解碼效率進一步得到提高。
由于可變長碼長度不同,在解碼過程中碼字存在前向依賴性。如果采用多路并行操作方式,在所有可能成為可變長碼碼字的起始位置同時進行預測,然后通過后續控制篩選出合法的碼字,就可以對多個可變長碼實現同時解碼。這就是多符號可變長并行解碼方案的基本思想。
具體說明如下:假設某個信源符號集有K個符號,K個符號所對應的變長碼字用Ck=(cok,…,cimk-1)|ckl∈{0,1},k=0,…,k-1表示,這些變長碼的長度為集合L,其中最長的碼長用ln表示,最短的碼長用l1表示;具有相同碼長的碼字最多為dmax個。現采用分頁方式重新組織這些可變長碼,將具有相同碼長的碼字存入一個頁內,那么易知一個頁內最多可能擁有dmax個碼字。為了識別一個頁內的不同碼字,還需要引入頁內偏移量,然后采用線性結構將這些頁面重新組合。
下面給出一個依據該思想重新組織信源符號的實例:
對于存儲在Buffer中的等待解碼的數據碼流X,用滑動窗口從中截取前N位,這里的N應當大于或等于可變長碼中最長碼字的碼長,即N≥ln。由于可變長碼最短的碼長為l1,因此在這N位碼流中,最多可包含M=[N/l1]個可變長碼。為了表示方便,這里用Wi(i=0,1,…,M-1)表示這M個可變長碼。
雖然,對于W0,其起始位置必然為0;如果W0的碼長為L0,那么W1的起始位置則為L0;如果W1的碼長為L1,那么W2的起始位置為L0+L1,依此類推。由于在解碼開始時,L0的取值無法明確,其可能取值范圍是l1≤L0≤Ln,因此每個Wi的可能起始位置分別由一組值組成。
為了實現并行解碼,采用多個可變長碼檢測單元從所有可能的起始位置同時偵測,一旦W0的碼長L0被偵測出,就可以從所有已解碼的可能的變長碼中找出W1,并確定W1的碼長L1,由此W2的起始位置也就得以確定。依此類推,最多可逐次將Wi(i=0,1,…,M-1)個變長碼解出。
每個Wi的解碼過程只比Wi-1的解碼過程多一個加法操作的延遲,相對于變長碼的識別,加法操作的延遲非常的小。當然,如果滑動窗口N的取值過大,每個Wi之間的加法操作的延遲將累加,這將降低解碼的整體效率。因此對于滑動窗口N的選擇,需要結合實際應用中可變長碼編碼的特點來權衡。
設某個待解碼流為B={110110100011000011001111,…}。這里采用長度N=12的滑動窗口進行碼流提取,由于變長碼的長度從2~8不等,因此每個運動周期至少可以解碼出1個碼字,最多可解碼出6個碼字,這6個變長碼字可能的起始位置分別為W0:{0};W1:{2,3,4,5,6,7,8};W2:{4,5,6,7,8,9,10};W3:{6,7,8,9,10};W4:{8,9,10};W5:{10}。
綜合起來,可能成為該可變長碼起始位置的集合為{0,2,3,4,5,6,7,8,9,10},因此在應用上共需要10個可變長碼檢測單元并行執行。
2 實現與驗證
多碼字并行解碼方法實現的關鍵在于解碼過程的并行性,采用硬件方案實現起來并不 難。上例中10個可變長碼檢測單元可采用經典的位并行解碼方案實現,因為位并行解碼方案能夠保證不同長度碼字的輸出時間基本相同,為其后的操作帶來便利。在本文中,采用基于查找表的方式來實現。
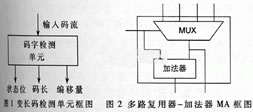
碼字檢測單元所檢測到的可變長碼的碼長及頁內偏移量(這里采用碼字的最右位作為頁內偏移量),在識別過程中可能存在沒有任何有效碼字的情況。為此,增加了一位有效狀態位,作為輸出是否有效的標志。變長碼檢測單元CD的結構框圖如圖1所示。
由于前一個有效碼字Wi-1的碼長控制著碼字Wi的選取,而對應Wi-1的檢測單元Cdi-1輸出了Wi-1的碼長,因此在實現上可以采用將Cdi-1的輸出作為有效碼字Wi選取的控制位,它通過控制一個多路選擇器MUX,從所有對應可能是Wi起始位置的CD輸出中選取有效的輸出作為有效碼字Wi。在有效字Wi被成功識別后,需要將其碼長即Cdi的輸出與Cdi-1的輸出相加,作為有效碼字選擇的控制。這些功能通過一個復合的多路復用器-加法器MA實現,多路復用器-加法器MA的結構如圖2所示。
在所有有效碼字的起始位置被識別后,根據對應CD單元的輸出,即碼長信息和頁內偏移量,可以通過查表將對應的碼長數據轉換成相應的信源符號或存儲相應信源符號的地址。這些功能由信號轉換單元SYMBOL完成。
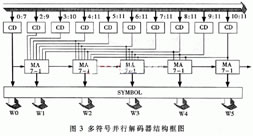
根據上面的討論,設計出用于上例的多符號并行解碼器,其結構圖如圖3所示。
為了驗證這種這種結構,采用FPGA器件實現它,選擇的是一片Xilinx xc2s400e-6ft256器件,其規模為145000門。在這里,采用VHDL語言進行RTL級描述,利用XST進行綜合,并在ModelSim5.8中進行仿真。結果驗證正確,其仿真結果如圖4所示。

實驗表明,系統允許最大時鐘頻率為44.172MHz,占用了197個SlICe(4%),74個Slice Flip Flops(<1%),347個四輸入查找表(12%)和1個全局時鐘(25%)。




評論