網絡并行計算在多層快速多極子法中的應用

3 MPI軟件包及網絡并行計算技術
MPI(Message Passing Interface)是消息傳遞并行程序設計標準之一。指定該標準的主要目的是為了提高并行程序的可移植性和使用的方便性。有了標準,并行計算環境下的應用軟件庫以及軟件工具就可以透明的移植。各個廠商可以依據標準提供獨具特色和優勢的軟件實現和硬件支持,從而提高并行處理的能力。
我們選用國內外較流行的MPICH2版本與Compaq Visual FORTRAN 66相結合進行并行程序設計。MPICH2具有通用性強、系統規模小、成熟度高、可以免費獲得等優點,非常適合數值計算。
使用主從結構模式實現并行MLFMA,主機主要功能為初始化、任務的管理分配和最終結果的輸出,不參與具體計算;中間計算由從機負責。
并行算法可以用很多標準來評價,如加速比和并行效率[7,8]。
加速比定義為

并行效率定義為

搭建高性能高效率的并行計算機網絡平臺,計算機主要配置為Pentium IV雙核1.86GHz CPU,2GMB內存,Microsoft Windows XP操作系統,千兆以太網交換機。我們開發的并行多層快速多極子程序,用9臺計算機參加并行計算,其中1臺為主機,參加實際計算的為8臺從機。
4 數值結果
算例一:入射波頻率為1.6GHz,金屬球直徑17.067λ,未知量數目為172,680,計算出其雙站RCS曲線,見圖1。為了使曲線簡潔明了、易于辨認,僅給出0°~30°部分。計算結果與Mie解吻合較好。由表Ⅱ中數據算得并行加速比為7.78,并行效率為97%。
算例二:入射波頻率為1.6GHZ,金屬球直徑85.333λ,未知量數目為2,402,328,計算出其雙站RCS曲線,見圖2。為了使曲線簡潔明了、易于辨認,僅給出0°~30°部分。計算結果與Mie解吻合較好。每臺從機內存消耗為1.6GB。
表2 串行、并行程序單機內存消耗及時間比較
串行程序 | 并行程序 | |
單機消耗內存 | 534.74MB | 71.56MB |
程序總耗時 | 1028.82秒 | 132.26秒 |
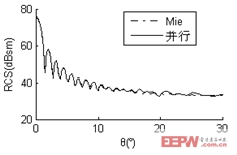
圖1 (a) φ=0°時直徑17.067λ金屬球雙站RCS曲線
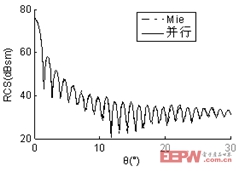
圖1 (b) φ=90°時直徑17.067λ金屬球雙站RCS曲線
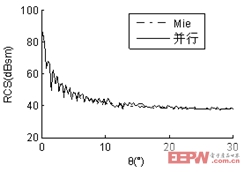
圖2 (a) φ=0°時直徑85.333λ金屬球雙站RCS曲線
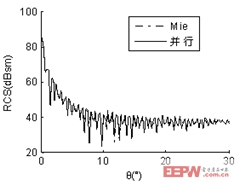
圖2 (b) φ=90°時直徑85.333λ金屬球雙站RCS曲線
5 結論
本文對網絡并行計算在多層快速多極子法中的應用作了探求,計算了含240萬未知量金屬球的雙站RCS,初步驗證了并行求解大未知量問題的可行性與高效性。增多參與計算的從機數目,優化并行MLFMA,則能夠計算更大規模的問題,這也是以后可以改進的方面。

評論