流水線處理技術在數據集成中的應用

隨著個人計算機和計算機網絡的飛速發展,以及信息化的高速推進,互聯網提供的信息總量也在迅猛增長。如果企業和社會組織實現數據共享,可以使更多的人更充分地利用已有的數據資源。可是為不同應用服務的信息都存儲在許多不同的數據源之中,數據內容以及數據格式千差萬別,且其管理系統也各不相同。如何對這些數據進行有效的集成管理,屏蔽這些信息的異構,并提供一個統一的訪問接口以透明地訪問各信息源,成為一些大型企業或社會組織關心的事情。數據集成正是在這一背景下提出的。
1 基于數據復制方法的集成模式
數據復制方法[1]是當前比較常用的數據集成模式,該方法將各個數據源的數據復制到與其相關的其他數據源上,并維護數據源整體上的數據一致性、提高信息共享利用的效率。這種方式可以復制信息源的整個數據,也可以是信息源的部分信息。數據復制方法在用戶使用某個數據源之前,將用戶可能用到的其他數據源的數據預先復制過來,如果用戶要使用的數據已經被復制,則只需要查詢該集成信息源,并與中介器/包裝器的虛擬數據集成[2]相比,大大提高了系統處理用戶請求的效率。
基于數據復制方式最常見的一種方法是數據倉庫方法[1]。該方法將各個數據的全部或者部分數據復制到數據倉庫,用戶像訪問普通數據庫一樣直接訪問數據倉庫。該方式實現了對物理數據庫語義異構的屏蔽和數據訪問的控制,提供了一個統一的數據邏輯視圖來隱藏底層的數據細節。圖1所示為一個典型的數據倉庫體系結構圖[3]。
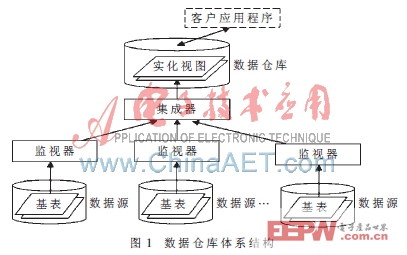
在該集成模型中,每一個數據源對應一個監視器(Monitor),監視器負責收集所需要集成的信息源中數據的變化以便上報給集成端(收集的方式有如下類別:針對信息源有日志的情況,可以通過日志分析提取要上報的增量;對于沒有日志情況可以通過觸發器方式或者快照差分方式獲取信息源的增量),同時監視器還具有一個包裝器的功能,提供信息源的數據查詢提取以及類型轉化功能。當作為數據查詢功能的時候,不僅將數據初始化同步到數據倉庫中,同時也相當于一個服務器,不斷偵聽來自于集成器的命令查詢請求,當有請求到達時,執行查詢,并將該監視器對應的數據源的數據包裝成基于公共類型的數據,或以XML文件的方式和固定大小對象數據塊的方式傳遞給集成器,然后集成器負責將提取后的數據進行合成。其中監視器與集成器中的通信流程如圖2所示。
2 基于內存控制的流水線處理方法
從上面的數據倉庫體系結構可知,監視器必須具備一個包裝器(wrapper)的功能。數據倉庫端保存的數據是各底層信息源的部分副本(一般情況為訪問非常頻繁),但是不是很頻繁的訪問數據還是保持在底層信息源端,當一個OLAP查詢(如下鉆)經過查詢分解后,不能在數據倉庫端獲取,而必須通過一個甚至幾個底層信息源端的查詢,然后在集成器端進行結果的合并(如要通過兩個底層數據庫中表的連接操作)才能獲取查詢結果。在實化視圖初始化時,提高查詢的效率以及提高實化視圖初始化的時間,是非常重要的。
本文關注的便是如何提高查詢效率、響應速度、集成端的處理效率,以及在提交查詢后,如何減少集成端的空閑等待時間,并且在大數據量的情況下同時做到內存控制,以防止在大數據量的情況下查詢導致內存溢出。
在解決提高查詢效率、響應速度、集成端的插入效率的同時,防止內存溢出以及在減少集成端的空閑等待時間方面,利用了基于生產者/消費者的流水線處理方法,該方式主要思想是實現服務器與客戶端的流水并行[4],查詢的結果以固定大小數據塊的形式分塊組裝,并在監視器端與集成端都使用一定大小的緩沖隊列來暫存這些數據塊,以有效防止內存溢出。以一次實化視圖的初始化過程為例,描述該方式的算法流程為:
(1)集成端發送帶全局查詢QID(該查詢QID為全局唯一的,通過客戶端API自動生成)的SQL查詢命令(結果查詢重寫),并通過通信平臺將該查詢命令放入服務器端執行隊列中,同時預設一個數據塊計數為sum(該計數為服務器端初始要發送的數據塊個數),然后集成端監聽接收隊列;
(2)監視器端從命令隊列中取出查詢命令,創建查詢管理器(Data Query Manager),并將該查詢管理器與查詢QID作為一個鍵值對放入進程全局的哈希表(Concurrent Hash Map)中,然后通過該查詢管理器中的excuteQurey()方法啟動查詢線程,該查詢線程將獲得的記錄組織成數據塊(Data Object Block),放入固定大小的數據塊緩沖隊列中,并在該隊列滿時,查詢線程暫停,不滿時繼續查詢,直到最后一塊為止。同時啟動發送固定大小的數據塊的線程,該發送線程從緩沖隊列中取出數據塊,發送給客戶端,直到發送的最后一塊,該發送線程終止;
(3)當有數據塊到達客戶端的數據塊接收隊列時,判斷該塊是否為最后一塊,如果是,則設置所有塊是否到達的標志“flag=true”,并通知客戶端進行處理,客戶端處理線程從隊列中取出一個數據塊進行處理(對實化視圖初始化,處理的方式就是將該數據塊插入到數據倉庫的實化視圖中),并將數據塊計數n減1,再判斷該數據塊計數是否小于客戶端要緩沖的個數N,并同時判斷flag的值,如果sumN,且flag= =false,則發送從服務器端調取固定數目K數據塊的命令(該命令帶QID,以便到服務器端時找到之前的查詢管理器),同時設置sum=sum+K;
(4)服務器端接收到客戶端的數據塊調取命令,分離出里面的QID,從進程全局的哈希表中找到與該QID對應的查詢管理器,并調用里面的發送固定數據塊的方法以啟動發送固定數目數據塊的線程,該線程與步驟(2)中發送線程相同;
(5)重復步驟(3)、步驟(4),直到查詢的最后一塊到達客戶端,與此同時,服務器端的查詢管理器也從全局的哈希表中移除。
3 性能測試與分析
與流水線處理方法相對應的一種方法為同步方法,即通過查詢先將底層信息源的結果組裝在一起,一次傳給集成端處理。由于采用的都是對象數據塊的形式,因此用于與流水線對比的同步方法的算法思想為:
(1)客戶端發送帶全局查詢QID(該查詢QID為全局唯一的,通過客戶端API自動生成)的SQL查詢命令(結果查詢重寫),并通過通信平臺將該查詢命令放入服務器端執行隊列中;
(2)服務器端接收到查詢命令,執行查詢,將所得的結果存放于文件中,然后一次發送給客戶端;
(3)客戶端接收到關于本次查詢結果集的文件,然后處理該結果集文件。
將基于內存控制的流水線處理方法與同步方法在以下實驗環境下進行測試對比,為減少誤差,多次測試得出平均值,有如下數據:
監視器端與集成端采用相同配置環境,相關配置為:
CPU:Intel(R) Core(TM)2 Duo CPU E4500 @ 2.2 GHz;操作系統:Windows XP;內存:2.0 GB;數據庫:Oracle 9i;JDK版本:1.6.0_07;開發工具:Myeclipse6.5。
本實驗性能測試如圖3所示,可以看出,與傳統的同步方法相比,采用本文算法具有較好的性能特性,主要在于基于內存控制的流水線處理過程是一個監視器端與集成器端并行流水線運行的過程,并充分應用了現在多處理器多線程處理的技術,減少了集成端空閑等待的時間。
設查詢信息源并包裝所有數據成公共類型數據塊的時間代價為Cost(Q),傳輸放入文件中的所有數據塊到集成端的時間為Cost(T),集成端將傳輸過來的數據解析并初始化到數據倉庫的時間為Cost(P),則基于同步方法的時間代價為:Cost(Q)+Cost(T)+Cost(P)。
設查詢信息源并包裝查詢的數據成公共類型數據塊為一塊的時間代價為:Cost(Q1),傳輸其中一塊數據塊到集成端的時間為Cost(T1),集成端將傳輸過來的一塊數據塊解析并初始化到數據倉庫的時間為Cost(P1),因為這里數據塊是個固定的常數,則基于本文的算法的時間代價為:Cost(Q1)+Cost(T1)+Cost(P1)+max(Cost(Q)-Cost(Q1),Cost(T)-Cost(T1),Cost(P)-Cost(P1)),其中max為各處理邏輯減去初始處理的最大時間。
從上面理論上可以分析得出,基于內存控制的流水線處理技術較同步技術可以更好地提高效率。同時還存在幾個問題:
(1)當集成端需要OLAP查詢或實化視圖初始化比較多時,仍然會出現內存溢出的問題,這時可以應用線程池技術[4],有效控制這類線程運行的數量,同樣,監視器端也使用這種方案。
(2)當集成端與監視器端進行流水線處理時,如果監視器端與集成端出現網絡中斷,或者其中一個出現突發事件(如斷電)時,之前的一些過程就需要重做,并回滾。特別是針對網絡中斷的情況,容易造成監視器端查詢線程的線程泄漏,即集成端認為之前的操作沒成功,然后重新進行操作,然而監視器端的處理線程卻還沒完。避免這些情況出現的解決方案為:設置一個超時,當達到設定時間而這一流水處理過程未進行時,自動中斷這些處理流程,或者可以在監視器端對查詢組裝后數據塊分塊存儲在硬盤上,然后進行文件數據塊的發送,這樣減少了塊之間的命令的交互邏輯,而且有效地控制了線程泄漏,但是也增加了文件的讀寫與控制,增加了I/O開銷。
數據集成仍然是一個比較熱門的研究點,在基于數據倉庫方法的數據集成中,分析了實化視圖初始化以及OLAP查詢中面對大數據量處理的問題,應用了基于內存控制的流水線處理方法,充分利用了Java的多線程處理技術,并從實驗和理論上分析了該方法較同步方法的優點。

評論