基于DSP嵌入式說話人識別系統(tǒng)的設(shè)計

1.6 說話人身份識別的結(jié)果顯示
說話人的身份顯示通過LED的組合顯示確定。在DSK上有4只LED燈,將每個LED燈看成是一位二進(jìn)制數(shù)。則4個LED燈最大可表示16個人的身份。該系統(tǒng)取前10個組合來表示所識別的說話人的身份。
1.7 自舉的實現(xiàn)
以上程序都是通過PC機(jī)與DSP組合實現(xiàn),要想使系統(tǒng)在DSP上單獨完成,還必須實現(xiàn)自舉。該系統(tǒng)采用ROM方式自舉。在自舉實現(xiàn)過程中,程序的燒寫可以通過CCS自帶的FLASHBorn工具實現(xiàn)。在燒寫過程中應(yīng)正確的分配FLAH ROM的空間。FLASHROM空間總體分為程序存儲區(qū)和數(shù)據(jù)存儲區(qū),經(jīng)計算,程序代碼段大小為0x162C0,故在FLASH ROM中劃分127 KB的空間供程序代碼使用,空間中未使用的部分供程序擴(kuò)展使用。數(shù)據(jù)存儲區(qū)劃分的大小為64 KB的空間,每個說話者模型參數(shù)占用空間為4.2 KB左右,最多可存放15個說話人GMM模型參數(shù)。該系統(tǒng)訓(xùn)練者數(shù)目為10個,占用空間為42 KB左右。剩余的空間可用來擴(kuò)展訓(xùn)練人數(shù),也可用于后期系統(tǒng)的改進(jìn)。如可以利用語音提示來顯示說話人身份,而提示語音的數(shù)據(jù)可以存放于此區(qū)域。具體的存儲的安排如表1所示。

2 系統(tǒng)的算法與軟件設(shè)計
說話人識別系統(tǒng)的實現(xiàn)方案如圖3所示。
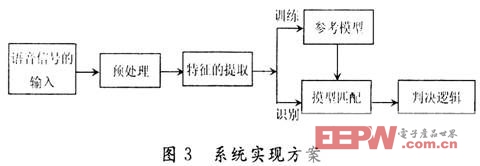
輸入的模擬語音先通過預(yù)處理,包括預(yù)濾波、采樣、量化、加窗、端點檢測、預(yù)加重等。語音經(jīng)過預(yù)處理后進(jìn)行特征提取。在訓(xùn)練階段,對提取的特征進(jìn)行相應(yīng)的處理后就可以獲得參考模型。識別階段,語音通過同樣的通道獲得特征參數(shù),生成測試摸型,之后將測試摸型與參考摸型進(jìn)行匹配,從而根據(jù)判決邏輯獲得判決結(jié)果。
linux操作系統(tǒng)文章專題:linux操作系統(tǒng)詳解(linux不再難懂)






評論