嵌入式智能查詢算法中利用圖形對數據進行可視化處理

數據在許多研究領域都可采用圖形來表示,圖形和圖形理論為人工智能決策提供了有效的可視化工具、體系化準則和相關技術。本文以交通線路自動調整系統為例,說明在嵌入式智能查詢算法中如何利用圖形對數據進行可視化處理的方法來避免“盲目”操作,從而提高算法的決策效率。
圖形由節點和邊線組成,節點通常畫作圓形,而邊線則是節點之間的連線。在軟件中,節點通常采用將邊線作為指針或數組下標的數據結構加以實現。對圖形進行遍歷查詢的算法有多種,常用的算法包括深度優先查詢和寬度優先查詢算法。深度優先和寬度優先都屬于“盲目”查詢算法,深度優先算法沿著一組邊線從根節點一直查詢到最遠端的葉節點,再查詢下一個葉節點;寬度優先算法則首先查詢一個邊線距離以內的所有節點,再查詢兩個邊線距離以內的節點,以此類推。
上述算法之所以具有盲目性,是因為算法在查詢適當解決方案的過程中并未指示任何有效信息,而只是盲目地遵循遍歷算法,甚至有可能在找到解決方案之前需要遍歷每一個節點,因而效率比較低。本文介紹的基于數據可視化處理的嵌入式智能查詢算法以車輛行駛線路自動調整系統為例來說明解決上述問題的思路。
車輛導航
在設計一個遍歷整個公路段的網絡系統中,假定存在一個自動垃圾收集站系統、運動攝像機或自動交通線路調整系統。圖1顯示了舊金山的部分城市交通圖。首先,需要創建代表上述數據的網絡圖,以確定將哪些單元作為節點。如果其他標志不甚明顯,那么道路交叉口就可選擇為節點。隨著這些節點的插入,就完成了網絡圖的一部分,不過目前得到的只是城市交通圖的無目標靜態表示。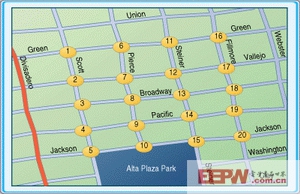
下一步是添加系統進行智能決策所需的額外信息。如果系統的目標是幫助車輛選擇最佳的路徑而從一個交叉口駛向另一交叉口,很自然地就會想到為那些連接交叉口的公路段分配權值。在最簡單的情形中,所有的道路都不是單行道,并且具有相同的速度限制和車道數目。即便這些條件不能完全反映真實的道路狀況,一旦構建好網絡圖和權值模型,就能很容易擴展到這些真實環境中去。
對交通圖中的邊線賦以權值有助于系統找到最佳的路徑。在某種程度上,這些權值可以任意分配,這里假定權值表征平均車流密度。基于特定時段或局域條件的動態權值也是可行的,并不影響以下分析。
圖1中,邊線的權值表示了每小時穿過道路的平均車流量,這些統計數據并不基于任何實際的數據,但在分析中相當有效。如果車輛必須從Scott和Jackson交叉口(節點5)行駛到Fillmore和Vallejo交叉口(節點17),采用最小車流量判據,得到的查詢算法應能得到總權值最小的路徑。
我們很容易就能在網絡圖中畫出結果,但仍然希望能借助計算機解決問題。表征圖形的兩種最常用方法是鄰接矩陣(adjacencymatrix)和鄰接表(adjacencylist)。鄰接矩陣是靜態的多維陣列,矩陣中的元素表示一個節點到另一節點的權值。圖2顯示了示例網絡中包含節點1至節點6之間邊線權值的部分鄰接矩陣。節點1和節點6之間的邊線權值位于最右角(對應點位于左下角)。圖2中36個節點的公路網絡的整個鄰接矩陣可包含36個元素。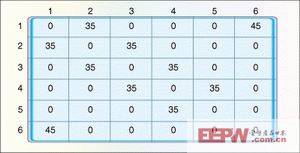
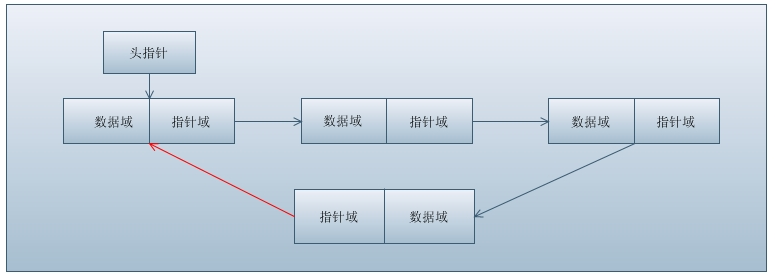
鄰接表通常采用鏈表實現,圖3顯示了網絡中節點1至節點6的鄰接表。圖中并未標出邊線權值,但可以很方便地存儲在數據結構中。
對鄰接矩陣和鄰接表進行選擇時,可以考慮如下因素:
1。如果網絡圖密集或較小,則用鄰接矩陣表示。鄰接矩陣的優勢在于可以直接取得權值,而無須進行指針管理和鏈表遍歷。
2。如果網絡圖稀疏或很大,那么鄰接表可以減少內存浪費。
3。如果需要實時地添加和刪除節點或邊線,則采用鄰接表。當然,這時也需要系統具有動態內存管理能力。
直觀推斷
如果根據每個節點出口的最小權值進行“盲目”查詢,那么很有可能會走錯路,甚至永遠無法到達目的地。更為智能的查詢應能根據直觀推斷進行構建,并且直觀推斷應能在大多數時間內成為查詢的常規指南。我們通常將其稱為經驗規則。生活中最簡單的經驗是:“因為現在是4月且天空多云,所以需要帶上雨傘。”雖然4月份和天空多云并不意味著會下雨,但這樣的條件下下雨的可能性遠遠高于正常天氣。
直觀推斷也是實現高速有效查詢的一個重要策略。如果尚未打定主意,最初可以選定一個不怎么適當、甚至大錯特錯的值。對于公路遍歷問題而言,一種可能的直觀推斷是:“當一個節點存在兩個(或更多)等權值的邊線時,執行寬度優先查詢,然后繼續查詢總權值最小的路徑。”例如節點15就出現了這樣的情形,該節點的出口存在兩個權值為15的邊線。利用寬度優先查詢,對下一節點及其出口邊線的權值進行檢測。下一級節點為14和20,這兩個節點出口邊線的權值分別為15和45。根據最小邊線判據,選擇節點14繼續查詢,這完全合乎情理;因此節點20將被拋棄。
某些直觀推斷看起來非常明顯,但即便是這些直觀推斷也有助于探尋待解決問題的實質。對于公路遍歷問題,最基本的直觀推斷就是:“選擇具有最小邊線權值的路徑。”這簡單易行,但背離了查詢的基線準則。
遵循最小邊線權值的方法稱為“貪婪算法”(greedyalgorithm),該算法以即刻滿意度為基礎。貪婪算法并不考慮以后的情況,而選擇當前最為廉價的路徑進行查詢。這并不能保證得到有效的解決方案,甚至有時會得到不怎么優化的路徑。當詢及為何選擇最終被證明是錯誤的路徑時,貪婪算法或許會回答:“在當時,這看起來是個不錯的選擇。”
一些對人類而言相當明顯的直觀推斷對于機器則并非如此。例如直觀推斷“當節點存在兩個(或更多)等權值邊線時,將執行寬度優先查詢,然后繼續查詢總權值最小的路徑”,這本身并沒有問題,但還是存在一個問題。如果最小成本的路徑偏離了目標節點怎么辦?這樣選擇得到的或許是一條更為昂貴的路徑。由此可見,還必須了解從當前節點至目標節點的方向。以這種形式開發直觀推斷是展現待解決問題所需核心知識的良好途徑。
解決公路網絡導向問題的一個有效途徑是動態計算當前節點和目標節點之間的距離和方位。這要求得到每個節點的經緯度數據,并對前進中的每一個節點進行浮點操作,因而極有可能是最不優化的解決方案。更好的策略是根據經緯度對之間的差異得到一套準則,這有助于提取最少準則所需的信息。
第一步必須明確方向和經緯度之間的關系,圖4顯示了根據經緯度差異得到的方向。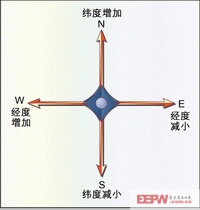
當向北方移動時,緯度將增加;向西方移動時,經度增加;以此類推。從這些簡單的關系中可以看出,每個節點上完全可以去除許多不必要的操作。將以上知識與交通圖相結合,可以得到Scott和Jackson交叉口的起始緯度和經度分別為N3747。514和W12226。356,而目標Fillmore和Vallejo交叉口則分別為緯度N3747。725和經度W12226。002。根據圖4中的羅盤儀準則,現在目標交叉口位于起始交叉口的東北方向。
根據以上方向關系,可以得到如下六條準則:
準則1:如果緯度(目標)>緯度(現在狀態),那么目標為北方;
準則2:如果緯度(目標)緯度(現在狀態),那么目標為南方;
準則3:如果緯度(目標)=緯度(現在狀態),那么目標為空;
準則4:如果經度(目標)>經度(現在狀態),那么目標為西方;
準則5:如果經度(目標)經度(現在狀態),那么目標為東方;
準則6:如果經度(目標)=經度(現在狀態),那么目標為空;
可以將上述基本準則相結合以得到更為復雜的方向,如東北和西南。這只需要將基本準則通過與操作結合起來,這樣有效的組合如下:
規則1^規則4->目標為西南
規則1^規則5->目標為東北
規則1^規則6->目標為北
規則2^規則4->目標為西南
規則2^規則5->目標為東南
規則2^規則6->目標為南
規則3^規則4->目標為西
規則3^規則5->目標為東
規則3^規則6->目標為空
將基本準則和復雜準則結合起來就能得到成功的查詢方法。如果目標在當前節點的西北方向,那么向北方和東方移動是合法的。這里我認為應該是:“如果目標在當前節點的東北方向,向北方和東方移動是合法的”,而向南方和西方移動則不合法。
當查詢到節點12,選擇的邏輯路徑則是從節點12至節點11并且權值為15的邊線。此時方向為北方,這看來是合法的,且邊線權值達到最小。其實這完全是錯誤的,因為查詢偏離了目標節點。現在我們利用規則對查詢進行限定,節點12與節點17平行,因此準則3成立。此時經度減少,因此規則5成立。如果規則3和規則5都成立,那么目標是正東方。規則基礎很好地完成任務:避免了“盲目”查詢或對“盲目”查詢進行導向。結果如圖5所示。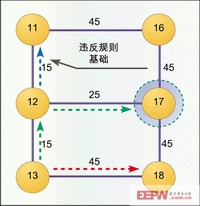
本文小結
如上所述,圖形表示法和盲目查詢算法本身并不足以解決大多數問題。但將這些技術同直觀推斷以及特定問題的規則集相結合,就像上面所做的那樣,就能得到有效的人工智能。類似的技術可應用于諸多應用領域。盡管本文的示例集中于靜態數據,但當邊線及邊線權值改變并且不能對規則進行硬編碼時,這里給出的技術仍然有效。
顯然,嵌入式系統通常受制于某些特殊限制。嵌入式編程中一般不允許遞歸算法,盡管這是圖形查詢算法中的一種常用技術。關鍵應用中的嵌入式系統也不支持動態內存分配,但如果沒有動態內存分配的話,將很難在鏈表數據表示法中添加和刪除節點。出于以上考慮,可以得到如下嵌入式智能的應用技巧:
1。考慮將部分處理移交至功能更為強大的系統,也許嵌入式系統只需要解決部分需要快速解決的問題。
2。避免遞歸,任何遞歸函數都應當用迭代函數進行重寫。
3。盡可能減小動態內存分配。如果鏈表的長度相對保持恒定,就可用數組進行代替,使數組的大小等于鏈表的最大長度,一旦超過該最大長度就返回操作失敗。
4。將智能視為低能動物而非超級計算機,即將其想像為處理意外情況或干擾的低等動物形式。
5。最重要的是,有效地綜合“盲目”算法、“貪婪”算法和智能查詢算法。當然,也沒有任何規定限制只能采用一種方法解決需要利用智能的問題。


評論