一種廣域網(wǎng)環(huán)境下的分布式冗余刪除存儲系統(tǒng)

由于數(shù)字信息的爆炸式增長,現(xiàn)今的大規(guī)模網(wǎng)絡(luò)應(yīng)用中所存儲的數(shù)據(jù)規(guī)模,可以到達(dá)上百太字節(jié)甚至拍字節(jié)的數(shù)量級。而傳統(tǒng)的存儲系統(tǒng),由于缺乏足夠的可擴(kuò)展性,無法適應(yīng)日益增長的需求。以Amazon S3[1]為代表的廣域網(wǎng)環(huán)境下的分布式存儲系統(tǒng)憑借其規(guī)模的可擴(kuò)展性、數(shù)據(jù)的可靠性、服務(wù)的可用性、系統(tǒng)的可管理性以及低廉的使用成本等巨大優(yōu)勢,已經(jīng)在構(gòu)建網(wǎng)絡(luò)應(yīng)用時被廣泛認(rèn)可。
廣域網(wǎng)環(huán)境下的分布式存儲系統(tǒng)將分布在廣域網(wǎng)上的資源整合在一起,為網(wǎng)絡(luò)應(yīng)用提供存儲服務(wù)平臺。來自不同網(wǎng)絡(luò)應(yīng)用和用戶的數(shù)據(jù)存儲其中,這些海量的數(shù)據(jù)中存在著大量的冗余。這些冗余數(shù)據(jù)不僅在存儲時占據(jù)了存儲系統(tǒng)大量的存儲空間,并且在被傳輸?shù)酱鎯ο到y(tǒng)的過程當(dāng)中,浪費(fèi)了大量的網(wǎng)絡(luò)用戶、網(wǎng)絡(luò)應(yīng)用和存儲系統(tǒng)的網(wǎng)絡(luò)帶寬資源,使存儲系統(tǒng)的資源利用率和整體性能受到嚴(yán)重影響。
本文提出一種在廣域網(wǎng)環(huán)境下的采用冗余數(shù)據(jù)刪除技術(shù)的分布式存儲系統(tǒng)原型——AegeanStore。在AegeanStore中采用客戶端相關(guān)的冗余數(shù)據(jù)刪除技術(shù)。該技術(shù)通過客戶端和服務(wù)器端的合作,不僅可提高存儲設(shè)備的利用率,而且可減輕客戶端和服務(wù)器之間的網(wǎng)絡(luò)負(fù)載壓力,從而進(jìn)一步提高存儲系統(tǒng)的可擴(kuò)展性和整體性能并且進(jìn)一步降低其成本。
1 冗余數(shù)據(jù)刪除技術(shù)
冗余數(shù)據(jù)刪除技術(shù)是將數(shù)據(jù)集中的冗余數(shù)據(jù)發(fā)現(xiàn)并去除的應(yīng)用技術(shù),可以分為兩大類:相同數(shù)據(jù)刪除和相似數(shù)據(jù)刪除[2]。
1.1 相同數(shù)據(jù)刪除技術(shù)
相同數(shù)據(jù)刪除技術(shù)首先將數(shù)據(jù)劃分為數(shù)據(jù)塊,然后使用具有抗碰撞特性[3]的哈希函數(shù)計算每一個數(shù)據(jù)塊的哈希值作為該數(shù)據(jù)塊的數(shù)字指紋,再通過比較數(shù)據(jù)塊的數(shù)字指紋來發(fā)現(xiàn)相同的數(shù)據(jù)塊。目前,最常用的相同數(shù)據(jù)刪除技術(shù)是基于內(nèi)容的劃塊(CDC)算法[4],其流程如圖1所示。
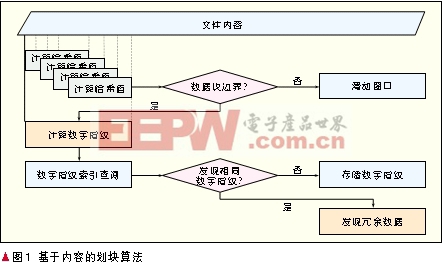
CDC算法存在3個參數(shù),一是目標(biāo)可變數(shù)據(jù)塊的預(yù)期大小S,二是滑動窗口的大小W,三是一個小于S的自然數(shù)M。當(dāng)使用CDC算法處理一個文件時,從文件頭開始以每次一字節(jié)的步長向后滑動窗口,使用哈希函數(shù)計算滑動窗口內(nèi)部的哈希值H;將H mod S與M進(jìn)行比較,如果不同,則滑動窗口;如果相同,則發(fā)現(xiàn)數(shù)據(jù)塊邊界,然后用具有抗碰撞特性的哈希函數(shù)計算該數(shù)據(jù)塊的數(shù)字指紋;最后,將獲得的數(shù)字指紋到索引中查找,如果存在則發(fā)現(xiàn)冗余數(shù)據(jù)塊,否則說明該數(shù)據(jù)塊是新的,需要存儲到系統(tǒng)當(dāng)中。
1.2 相似數(shù)據(jù)刪除技術(shù)
相似數(shù)據(jù)刪除技術(shù)分為兩個階段,相似數(shù)據(jù)檢測和相似數(shù)據(jù)編碼:
(1)相似數(shù)據(jù)檢測,首先要定義數(shù)據(jù)的特征值,該特征值的特點是保證具有相同或相似的特征值的數(shù)據(jù)具有相同或相似的內(nèi)容。在提取數(shù)據(jù)的特征值之后,通過特征值的比較獲得相似的數(shù)據(jù)。常用的相似數(shù)據(jù)檢測技術(shù)包括基于Shingle的檢測技術(shù)[5]。
(2)相似數(shù)據(jù)編碼是在使用相似數(shù)據(jù)檢測,獲得具有相似性的數(shù)據(jù)集之后,在該數(shù)據(jù)集上采用的編碼技術(shù),用于減小該數(shù)據(jù)集所占用的存儲空間。常用的相似數(shù)據(jù)編碼技術(shù)包括基于Diff的相似編碼技術(shù)[6]等。
2 AegeanStore的體系結(jié)構(gòu)
AegeanStore體系結(jié)構(gòu)如圖2所示。AegeanStore由客戶端、應(yīng)用服務(wù)、文件系統(tǒng)服務(wù)、索引服務(wù)和數(shù)據(jù)塊服務(wù)5個部分組成。
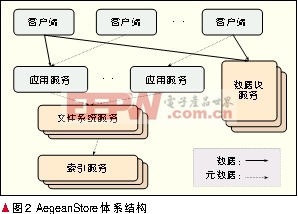
當(dāng)客戶端需要將文件數(shù)據(jù)存儲到應(yīng)用服務(wù)時,首先調(diào)用本地冗余數(shù)據(jù)刪除工具,運(yùn)行數(shù)據(jù)塊劃分算法,將要上傳的文件分成數(shù)據(jù)塊,并計算每個數(shù)據(jù)塊的數(shù)字指紋,然后將這些數(shù)字指紋發(fā)送給應(yīng)用服務(wù);應(yīng)用服務(wù)接收到文件上傳請求后,記錄應(yīng)用相關(guān)信息,再將請求轉(zhuǎn)發(fā)給文件服務(wù);文件服務(wù)記錄文件的元信息(包括文件屬性,例如文件的大小、修改時間等,以及文件的冗余數(shù)據(jù)刪除信息,如文件所有組成數(shù)據(jù)塊的數(shù)字指紋等),再將請求轉(zhuǎn)發(fā)給索引服務(wù);索引服務(wù)進(jìn)行塊的數(shù)字指紋查詢工作,將結(jié)果返回給文件服務(wù);文件服務(wù)將結(jié)果通過應(yīng)用服務(wù)返回給客戶端;客戶端按照返回結(jié)果,只將未出現(xiàn)在數(shù)據(jù)塊服務(wù)中的數(shù)據(jù)塊上傳;最后,當(dāng)所有新數(shù)據(jù)塊都存儲到數(shù)據(jù)塊服務(wù)中之后,文件服務(wù)將新數(shù)據(jù)塊的信息更新到索引服務(wù)當(dāng)中。下面將分別介紹5個部分的設(shè)計與實現(xiàn)。
2.1 客戶端
客戶端是為某個應(yīng)用服務(wù)開發(fā),運(yùn)行在使用該應(yīng)用服務(wù)的用戶的網(wǎng)絡(luò)終端上的程序。程序通過響應(yīng)用戶輸入并且同該應(yīng)用服務(wù)進(jìn)行消息交換,使用戶能夠使用該應(yīng)用服務(wù)提供的服務(wù)。AegeanStore的客戶端除了完成傳統(tǒng)網(wǎng)絡(luò)應(yīng)用的客戶端的響應(yīng)用戶輸入、網(wǎng)絡(luò)消息交換、身份驗證、數(shù)據(jù)傳輸?shù)热蝿?wù)之外,還要在冗余數(shù)據(jù)刪除技術(shù)中,完成重要的任務(wù):因為AegeanStore使用冗余數(shù)據(jù)刪除技術(shù)的目標(biāo)是減少冗余數(shù)據(jù)在網(wǎng)絡(luò)傳輸時造成的浪費(fèi),所以冗余數(shù)據(jù)刪除中的可變數(shù)據(jù)塊劃分和計算每個數(shù)據(jù)塊的數(shù)字指紋等工作必須在客戶端完成。在獲得需要上傳文件的所有數(shù)據(jù)塊的數(shù)字指紋后,通過應(yīng)用服務(wù)提供的網(wǎng)絡(luò)接口,查詢這些文件塊是否已經(jīng)在AegeanStore中存在,然后將新的數(shù)據(jù)塊上傳到數(shù)據(jù)塊服務(wù)部分,完成數(shù)據(jù)上傳過程;同時,客戶端需要管理已經(jīng)存儲在本地的數(shù)據(jù)塊的數(shù)字指紋,用于下載時減少冗余數(shù)據(jù)傳輸。
2.2 應(yīng)用服務(wù)
應(yīng)用服務(wù)是以AegeanStore提供的存儲服務(wù)、開發(fā)框架和功能組件為基礎(chǔ),構(gòu)建而成的網(wǎng)絡(luò)應(yīng)用服務(wù)。AegeanStore作為網(wǎng)絡(luò)應(yīng)用開發(fā)的基礎(chǔ)平臺,為了方便應(yīng)用服務(wù)的開發(fā),提供了應(yīng)用服務(wù)的開發(fā)框架,使得應(yīng)用服務(wù)的開發(fā)可以忽略網(wǎng)絡(luò)應(yīng)用中網(wǎng)絡(luò)端口監(jiān)聽、工作進(jìn)程派生、負(fù)載均衡和調(diào)度等問題,專心解決應(yīng)用服務(wù)的事務(wù)邏輯,使應(yīng)用服務(wù)的開發(fā)工作更加方便快捷。應(yīng)用服務(wù)開發(fā)者只需要將自己開發(fā)的消息處理模塊和消息序列化/反序列化模塊注冊到應(yīng)用服務(wù)框架當(dāng)中,即可被框架自動調(diào)用,進(jìn)而提供網(wǎng)絡(luò)應(yīng)用服務(wù)。除此之外,AegeanStore還為應(yīng)用服務(wù)的開發(fā)者提供用戶管理、網(wǎng)絡(luò)消息交換等常用的功能組件,從而提高在AegeanStore上開發(fā)應(yīng)用服務(wù)效率,降低應(yīng)用服務(wù)的開發(fā)和運(yùn)營成本。
2.3 文件系統(tǒng)服務(wù)
文件系統(tǒng)服務(wù)為AegeanStore提供文件系統(tǒng)視圖和文件管理接口。目前常用的提供公共存儲服務(wù)的分布式存儲系統(tǒng)當(dāng)中,普遍使用的應(yīng)用程序接口是Key/Value式的。雖然這種接口在開發(fā)應(yīng)用服務(wù)時使用比較方便,但是與用戶習(xí)慣的基于目錄結(jié)構(gòu)的文件系統(tǒng)式接口差異較大,導(dǎo)致大多數(shù)構(gòu)建在Key/Value接口上的應(yīng)用服務(wù)都要開發(fā)功能相似的文件系統(tǒng)視圖。這些重復(fù)開發(fā)增加了應(yīng)用服務(wù)開發(fā)的難度和成本,更重要的是,因為缺少存儲系統(tǒng)內(nèi)部信息的輔助,無法利用數(shù)據(jù)的局部性和網(wǎng)絡(luò)的就近訪問等優(yōu)化技術(shù),在Key/Value接口上構(gòu)建的文件系統(tǒng)效率往往較低,對應(yīng)用服務(wù)以及存儲系統(tǒng)的網(wǎng)絡(luò)和存儲資源造成了嚴(yán)重的浪費(fèi)。所以,AegeanStore為應(yīng)用服務(wù)開發(fā)提供的接口是文件系統(tǒng)式的,以提高應(yīng)用服務(wù)的開發(fā)效率,避免重復(fù)開發(fā),并通過使用分布式B樹、網(wǎng)絡(luò)就近訪問、代理訪問等優(yōu)化技術(shù),提高存儲系統(tǒng)的吞吐量。
2.4 索引服務(wù)
索引服務(wù)中存儲了AegeanStore中所有數(shù)據(jù)塊的數(shù)字指紋的索引,并提供網(wǎng)絡(luò)查詢索引接口,用來判斷數(shù)字指紋所對應(yīng)的數(shù)據(jù)塊是否已經(jīng)存在于AegeanStore當(dāng)中。以SHA-1哈希函數(shù)計算出來的數(shù)據(jù)指紋為例,每個塊的數(shù)字指紋大小為20 B,假設(shè)可變塊劃分算法所分的數(shù)據(jù)塊的平均大小為4 kB,則索引服務(wù)中存儲的數(shù)字指紋索引的數(shù)據(jù)規(guī)模為實際存儲數(shù)據(jù)規(guī)模的0.5%。由于AegeanStore存儲系統(tǒng)具有良好的可擴(kuò)展性,其數(shù)據(jù)規(guī)模可以達(dá)到數(shù)百太字節(jié)甚至拍字節(jié)級,所以索引服務(wù)應(yīng)該支持太字節(jié)級別的索引存儲。
2.5 數(shù)據(jù)塊服務(wù)
AegeanStore的數(shù)據(jù)塊服務(wù)提供分布式的基于內(nèi)容定位的存儲系統(tǒng)[7],其提供的接口是Key/Value形式的。數(shù)據(jù)塊服務(wù)由接口、一跳分布式哈希表(DHT)[8]和數(shù)據(jù)塊存儲節(jié)點3部分組成:當(dāng)用戶存儲數(shù)據(jù)塊時,以該數(shù)據(jù)塊的數(shù)字指紋作為Key進(jìn)行存儲;首先到一跳分布式哈希表中,查找該數(shù)字指紋,因為數(shù)字指紋由數(shù)據(jù)塊的內(nèi)容決定,所以,如果該數(shù)字指紋已經(jīng)存在于分布式哈希表當(dāng)中,說明該數(shù)據(jù)塊已經(jīng)存在于數(shù)據(jù)塊服務(wù)當(dāng)中,無需再次存儲;如果不存在,將數(shù)據(jù)塊存入數(shù)據(jù)塊存儲節(jié)點,將數(shù)字指紋和所存儲的位置信息存入一跳分布式哈希表作為索引。當(dāng)用戶讀取數(shù)據(jù)時,給出數(shù)據(jù)塊的數(shù)字指紋。塊存儲服務(wù)從分布式哈希表中查找是否存在這個數(shù)字指紋,如果存在則根據(jù)在其中獲得的數(shù)據(jù)塊位置從存儲節(jié)點讀取相應(yīng)數(shù)據(jù)塊并返回給用戶,否則返回空。
3 冗余刪除技術(shù)的優(yōu)化
將冗余數(shù)據(jù)刪除技術(shù)應(yīng)用于分布式存儲系統(tǒng)將遇到兩個問題。
(1)由于CDC算法開銷過大,無法滿足廣域網(wǎng)環(huán)境中的分布式存儲系統(tǒng)的客戶端的異構(gòu)性帶來的計算性能瓶頸。
(2)由于分布式存儲系統(tǒng)的高可擴(kuò)展性,造成索引服務(wù)中數(shù)字指紋索引過大,從而帶來的數(shù)字指紋索引查詢的性能瓶頸。
3.1 CDC算法的優(yōu)化
CDC算法中,無論在計算滑動窗口內(nèi)的哈希值,還是獲得數(shù)據(jù)塊劃分之后計算數(shù)據(jù)塊的數(shù)字指紋都是計算密集型工作。在手機(jī)或上網(wǎng)本等運(yùn)算能力較差的設(shè)備上,由于存在著性能瓶頸,制約了客戶端相關(guān)的冗余數(shù)據(jù)刪除技術(shù)的有效應(yīng)用。
首先,在AegeanStore的客戶端中,為了優(yōu)化CDC算法的運(yùn)行效率,在計算滑動窗口的哈希值時,采用了Rabin’s Fingerprinting[9]哈希函數(shù)進(jìn)行計算。因Rabin’s Fingerprinting哈希函數(shù)具有可迭代計算的特性,滑動窗口時,只需要通過將滑動前哈希值、滑入字節(jié)值和滑出字節(jié)值進(jìn)行復(fù)雜度為O(1)的計算,即可獲得滑動后的窗口內(nèi)部字節(jié)數(shù)組的哈希值。因為每個字節(jié)的數(shù)值最多有256種可能,可以通過預(yù)先的計算,將滑入和滑出字節(jié)相關(guān)的計算制成表格,之后,只需要通過查表和簡單的位移操作和加減操作即可獲得滑動后的哈希值,大大提高了CDC算法的運(yùn)算效率。
其次,AegeanStore引入了雙閾值雙除數(shù)算法(TTTD)[10],對CDC算法進(jìn)一步優(yōu)化。TTTD算法規(guī)定了數(shù)據(jù)塊大小的最小值Smin。每一個可變數(shù)據(jù)塊從開始到Smin的區(qū)間內(nèi)的數(shù)據(jù)不需要進(jìn)行哈希值計算。TTTD算法是為了對付可變數(shù)據(jù)塊劃分結(jié)果中數(shù)據(jù)塊大小差異太大而造成的冗余刪除率較差的問題,經(jīng)試驗證明,Smin:S約等于0.85時,可以獲得最好的冗余刪除率。所以使用TTTD算法可以大大降低冗余數(shù)據(jù)刪除的計算開銷,提高AegeanStore客戶端的運(yùn)行效率。
3.2 索引服務(wù)的優(yōu)化
AegeanStore的索引服務(wù)通過采用3種優(yōu)化方法,改進(jìn)索引服務(wù)的數(shù)字指紋查詢效率,以提高冗余數(shù)據(jù)刪除技術(shù)在分布式存儲系統(tǒng)中的性能。
(1)基于文件的批量數(shù)字指紋查詢
AegeanStore提出了基于文件的批量數(shù)字指紋查詢協(xié)議,將相同文件的數(shù)據(jù)指紋列表,連同該文件的路徑、大小等元數(shù)據(jù)信息,組織到同一個文件上傳請求當(dāng)中。經(jīng)過這樣的優(yōu)化,既減少了AegeanStore客戶端的網(wǎng)絡(luò)請求數(shù),增大了每個請求的數(shù)據(jù)量,提高網(wǎng)絡(luò)資源的利用率;并且,讓索引服務(wù)一次可以處理很多個數(shù)字指紋的索引查詢,增加了索引服務(wù)的吞吐量;更重要的是,使同一個文件的數(shù)據(jù)塊的數(shù)字指紋之間所存在的局部性得以保持,為索引服務(wù)進(jìn)行預(yù)取和緩存等進(jìn)一步優(yōu)化創(chuàng)造了條件。
(2)基于Bloom filter的快速新數(shù)據(jù)塊過濾
Bloom filter[11]是一種高效的利用有限的內(nèi)存空間,以一定錯誤肯定率為代價,用于快速的判斷某一個元素是否在一個集合中的概率性數(shù)據(jù)結(jié)構(gòu)。在AegeanStore的索引服務(wù)當(dāng)中,使用一臺性能較好、內(nèi)存空間較大的服務(wù)器來運(yùn)行快速新數(shù)據(jù)過濾模塊。一個存于內(nèi)存中的Bloom filter作為該模塊的核心數(shù)據(jù)結(jié)構(gòu)。當(dāng)接收到由請求節(jié)點轉(zhuǎn)發(fā)來的基于文件的批量數(shù)字指紋查詢請求之后,將其中每一個數(shù)字指紋送到Bloom filter中進(jìn)行判斷其是否存在于AegeanStore當(dāng)中。如果判定結(jié)果為可能存在,則將其忽略;如果為一定不存在,則將這個數(shù)字指紋標(biāo)記為新數(shù)據(jù)塊;將標(biāo)記后的數(shù)字指紋列表,返回給請求節(jié)點;最后,當(dāng)數(shù)據(jù)塊被成功上傳到數(shù)據(jù)塊服務(wù)之后,將其對應(yīng)的數(shù)字指紋加入到Bloom filter當(dāng)中。
(3)基于文件局部性的緩存和預(yù)取
文件局部性是指出現(xiàn)在相同文件中的數(shù)據(jù)塊,再次出現(xiàn)在相同文件中的概率會比較高。文件局部性通過使用基于文件的批量索引請求被保存到索引服務(wù)當(dāng)中,與某數(shù)字指紋具有文件局部性的其他數(shù)字指紋的列表稱之為局部性列表。緩存和預(yù)取節(jié)點中的緩存的數(shù)據(jù)結(jié)構(gòu)提供Key/Value式的接口,同樣以數(shù)字指紋作為Key,以其局部性列表作為Value。當(dāng)索引查找的數(shù)字指紋列表被分配到某個緩存和預(yù)取節(jié)點后,處理流程如下:對于每一個沒有被標(biāo)記為新的數(shù)字指紋,首先到緩存中查找該數(shù)字指紋,如果命中,說明該數(shù)據(jù)塊已經(jīng)存在于AegeanStore當(dāng)中,將文件的數(shù)字指紋列表和緩存中局部性列表合并,并在結(jié)果中標(biāo)記該塊為存在;若未命中,則到DHT中進(jìn)行查找,如果命中,將DHT中存儲的局部性列表加入緩存當(dāng)中,完成預(yù)取工作,之后的處理和緩存命中時相同;如果未命中,即該數(shù)據(jù)塊不存在于AegeanStore當(dāng)中,在快速過濾模塊當(dāng)中出現(xiàn)了錯誤的情況。
4 結(jié)束語
本文提出了廣域網(wǎng)環(huán)境下的分布式存儲系統(tǒng)原型AegeanStore。AegeanStore在提供互聯(lián)網(wǎng)上的存儲服務(wù)的同時,還為網(wǎng)絡(luò)應(yīng)用的開發(fā)提供了框架和通用的功能模塊,以提高網(wǎng)絡(luò)應(yīng)用開發(fā)和運(yùn)營的效率,并降低其成本。分布式存儲系統(tǒng)中普遍存在的冗余數(shù)據(jù),不僅浪費(fèi)了存儲系統(tǒng)的資源,而且造成了存儲系統(tǒng)的性能損失。AegeanStore通過采用客戶端相關(guān)的冗余數(shù)據(jù)刪除技術(shù),可提高對存儲資源以及網(wǎng)絡(luò)資源的利用率,降低運(yùn)營成本,提高可擴(kuò)展性以及整體性能。


評論