自制漢字取模軟件,學嵌入式的要看

學嵌入式開發這么長時間來一直都在使用別人的取模軟件,很希望有自己的取模軟件。
今天晚上讀了一下漢字編碼和點陣的文章做程序如下。希望對無協嵌入式開發有幫助
在計算機中英文一般使用 ASCII 碼來表示,而漢字編碼使用的是擴展 ASCII 碼,用兩個ASCII碼來表示一個漢字。一個ASCII碼占用一個字節,所有在存儲時英文是占用一個字節,而漢字占用兩個字節。
擴展 ASCII 碼:也就是 ASCII 碼的最高位是1的 ASCII 碼,一個漢字由兩個擴展 ASCII 碼組成,第一個擴展 ASCII 碼用來存放區碼,第二個擴展 ASCII 碼用來存放位碼。
區位碼:在 GB2312-80 標準中,將所有的漢字分為94個區,每個區有94個位可以存放94個漢字,形成了人們常說的區位碼,這樣總共就有 94*94=8836 個漢字。
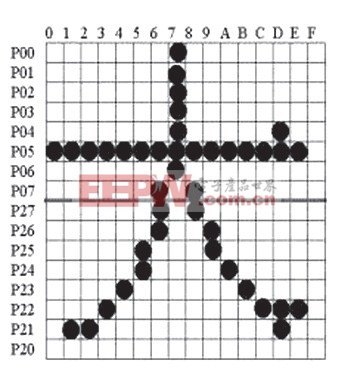
點陣字庫:漢字點陣數據就是按照這個區位的順序來存放的,也就是最先存放的是第一個區的漢字陣數據,在每一個區中有是按照位的順序來存放的。
漢字機內碼、國標碼和區位碼三者之間的關系為:區位碼(十進制)的兩個字節分別轉換為十六進制后加20H得到對應的國標碼;機內碼是漢字交換碼(國標碼)兩個字節的最高位分別加1,即漢字交換碼(國標碼)的兩個字節分別加80H得到對應的機內碼;區位碼(十進制)的兩個字節分別轉換為十六進制后加A0H得到對應的機內碼
國標碼 由兩個擴展ascii碼組成
漢字區位碼的存放實在擴展 ASCII 基礎上存放的,并且將區碼和位碼都加上了32,然后存放在兩個擴展 ASCII 碼中。具體的說就是:
漢字的
第一個擴展ASCII碼 = 128+32 + 漢字區碼
第二個擴展ASCII嗎 = 128+32 + 漢字位碼
程序要用的字庫HZK16

程序如下
#include "stdio.h"
#includeiostream>
using namespace std;
void getCode(unsigned char str[],unsigned char data[]);
void main()
{
unsigned char str[] = {"王挺帥"};
unsigned char data[32];
for(int m = 0;m 1;m++){
getCode(str+m*2,data);




評論