Bloom Filter 概念分析

在參考文獻中,作者提出了在無線傳感器網絡中實現帶有語義的路由,其具體方法是在每個節點存儲了一個語義檢索表,檢索表的每一點對應一個區域分類。每個節點只存在有限的幾個區域分類或稱為“路由可能”。這樣,當發生包含足夠屬性的語義信息的路由查詢輸入時,節點調用自己的規則引擎,通過計算匹配到檢索表中的某一點,并從其對應的區域信息獲取通往該區域的下一跳的信息。這與本沒計中的這種單步路徑查詢的方法有相似之處。本設計中也有這樣的一種規則引擎,即下文所要介紹的Bloom Filter。所不同的是,在本設計中,檢索表不是一個,而是多個;檢索表中的元素不再指示區域或路由的類別,而是指示輸入是否在當前路由表中;而且查詢輸人不是抽象的語義信息,而是人名、房間號或單位名稱等這樣的含有明確語義的地理空間標識。
下面可以看到,采用Bloom Filter不僅可以解決路由的分類和查詢問題,而且可以進一步降低資源有限的無線傳感器節點中的路徑信息的數據量。進而在WiME的設計中,對每一個分組使用計數型Bloom Filter實現了路由信息的動態修改。下面介紹基本的Bloom Filter和計數型Bloom Filter這兩種“規則引擎”。
BIoom Filter概念
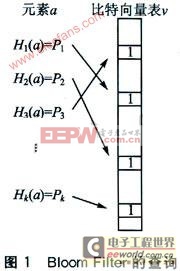
Bloom Filter的概念最早是由B.H.Bloom于1970年提山的。已知一個集合S含有n個元素,每個元素可以是人名、網址或者某個編號之類的能被計算機識別的獨有的一個或一組符號。我們定義一個含有m個元素的向量表v,v中的每個元素只使用1位表示,即每個元素只能表示為0或1。初始化v的每個元素為0。假設有k個獨立的hash函數H1,…,Hk,映射范圍為m。對S中的每個元素,將其進行hash變換后在v中對應的位置上置1。
如果要知道一個元素a是否在集合S中,可以參照圖1對其進行k個hash變換,并查詢v中對應的元素是否為1。如果k個對應元素均為1,就斷定a在集合S中。
舉例來說,如果S表示的是一個URL查找表,每個元素平均包含50個ASCII碼,則直接存儲需要400n位;而采用Bloom Filter存儲,需要m位(m和kn同數量級)。由于hash函數的計算需要花費一定的時間,限制k的個數不會很大,使得存儲空間大大縮小,所以這是一種用時間換取空間的辦法。
最優情況下Bloom Filter的正向誤檢概率
從上面可以看到,集合元素個數n、hash函數個數k和向量表長度m是Bloom Filter的3個關鍵參數。BloomFilter中存在著這樣一種情況,即雖然一個元素不屬于集合S,由于hash函數的隨機性,有可能k個hash變換在v中的對應元素均為1,從而該元素被誤認為屬于集合S。這種情況稱為“正向誤檢(false positive)”。從概率上看,正向誤檢總是不可避免的。
將n個元素插入Bloom Filter表中后,每一位元素仍然為0的概率是(如無聲明,下面均認為hash函數是均勻映射的):

計數型Bloom Filter
在生成Bloom Filter表的過程中,不可避免地會出現映射到v的同一位置的情況,這在存在增刪的情況下就會出現問題。如果一個元素從集合中刪除,則其對應的Bloom Filter表中的元素都要從1變為0。那么,其他映射到該位置的元素在查詢自身是否屬于集合時,就不會得到正確結果,這稱為“反向誤檢(false negative)”。計數型Bloom Filter可以解決這個問題,它將向量表中每個位置從1位表示改為多位表示。這樣,添加操作中每映射到某一位置1次,該位置就計數加1;刪除操作中時,該位置減1。計數位數決定了所能計數的最大值。
Bloom Filter的其他改進
除了計數型Bloom Filter,還有許多在嘗試提出改進的Bloom Filter數據結構。探討了非最優情況下m、n和k之間的相互關系;針對無線傳感器網絡中洪泛查詢的特點提出了隨空間域衰減的方式,其Bloom Filter向量表中置1的位會隨著空間域的變化以一定概率清0,則Bloom Filer解碼時就變成了統計k個hash函數對應位置上1的個數(個數越大可能性越大);參考文獻[8]提出的拆分型Bloom Filter,針對反復增刪最終導致最初設計的Bloom Filter表不可用的情況,提出將總表分割成多個子表來設計。
綜合考慮,筆者仍然認為計數型Bloom Filter是簡單、易用的,而且具有較好的性能。建議使用4位計數,但經過對計數位數的理論分析和實驗驗證,筆者最終采用了2位計數。這已經可以將進行反復增刪可能造成的反向誤檢的概率降低到1.85×10-4。反復增刪5396次,才會出現1次反向誤檢,對1000個節點這樣的規模已經是夠用的了。不過,對于這一問題的討論已經超出了本文的范圍,這里不再贅述。








評論