基于DM642DSP的視頻編碼優化方法

需要通過EDMA搬移的數據有待編碼的宏塊,前后幀對應的參考宏塊,和編碼后的重構宏塊(B幀不需要),這些宏塊都包括亮度塊和色度塊。EDMA在搬大量數據時才能將它的性能發揮到極致,如果每編完一個宏塊就進行一次乒乓緩存交換,那么在頻繁的配置EDMA通道參數上就耗費了過多的CPU周期。有限的片內存儲空間,制約著不能一次搬太多的宏塊,一般一次搬7--9個宏塊為宜。由于EDMA的同步信息是由CPU發出的,我們自然想到QDMA,但QDMA適用于單個的,獨立的快速搬移數據,對于這種周期性的,重復性的搬移并沒有優勢。
為了提高EDMA的效率,可以采用EDMA鏈,最多開辟12個EDMA通道,讓其首尾相連,這樣只需觸發一次CPU,可將待編碼的亮度塊色度塊,參考幀的亮度塊和色度塊……一次搬完,如圖2所示。在配置EDMA通道時,我們注意到頻繁更換的只是EDMA的源地址和目的地址,而其它參量是不變的。由于EDMA控制器是基于RAM結構的,每個通道是通過參數表來配置的,每一個通道的參數都可以在0x01A0000h~0x01A07ffh的2KB的配置表中找到自己固定的位置,所以在更新某一通道的源地址和目的地址時,直接往配置表寫上新地址就行了,而不必調用CSL庫中的相應的cache函數來修改源地址和目的地址。

圖2 EDMA鏈示意圖
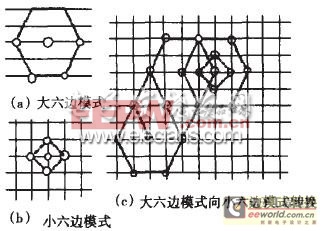
圖3 六邊形搜索算法
快速運動算法的優化
包括MPEG2,MPEG4和H.261、H.263、H264在內的標準都是采取基于塊的運動估計模型。當然不同的標準塊的大小也不一樣,在H.264標準中,支持七種塊大小(16x16、16x8、8x16、8x8、8x4、4x8、4x4)。眾所周知:運動估計對減少時間域的冗余起了很大的作用,從而能大大提高編碼效率,但同時它的計算量特別大,占用了大概整個編碼系統的70%~80%的資源。一個好的編碼算法就是要在計算量和編碼效率兩者之間取得一個很好的平衡。
全搜索(FS)能夠保證在全局范圍內搜到一個最佳的位置,但是其計算量是驚人的。對于在嵌入式系統中應用是不現實的。一般在實際應用中都是把幾種算法結合起來,在本系統中采取的是:六邊形搜索法,如圖3所示,先以預測點為中心進行大模式搜索,如果最優點不在六邊形中心,則將六邊形的中心移至改點,重復大模式搜索,直到最優點在六邊形中點,然后在這點切換到小模式搜索,此搜索法相對于經典的三步法,四步法搜索的點更少。
由于是在DSP平臺上,對監控系統實時性要求比較高,提出幾種基于DSP平臺的優化方法:為了提高L1D的cache的命中率,根據cache不命中流水的原理,一次將參考幀全部灌入L1D內,然后在做運動估計時將七個宏塊一齊做,然后再做七個宏塊的運動補償,DCT,量化,反DCT,反量化,編碼,寫碼流。而不是像一般的步驟,對每一個宏塊先做運動估計,然后運動補償,然后DCT,映射到L1D一次,如果每個宏塊單獨做,在做第一個宏塊運動估計時參考幀會由L2映射到L1D,做第二次運動估計時,因為之前程序做過DCT,量化等運算,映射到L1D里的參考幀數據已經被沖走,還得從L2中重新載入。同樣的對于程序段一級緩存L1P來說,DCT、量化、反DCT、反量化、編碼、寫碼流等函數都只需映射一次到L1P,而不必被反復地映射,沖掉,再次映射。
在JVT的提案中有很多運動矢量預測算法,如利用運動矢量在時間域有很強的相關性這一特性,我們能夠得到比較精確的起始搜索位置。但他不太適合DSP平臺,因為這樣我們就要保留整個一幀的運動矢量,以CIF圖像格式為例,需要12kB的空間,保存在資源緊張的片內顯然是不合適的。保存在片外存儲空間,調用的時候,先從片外先映射到L2cache,再從L2映射到L1D,其間流水不命中等待的cycle數,還不如從開始不太精確的初始位置多搜幾個點。
整數DCT的優化詳解
DCT,量化,反DCT,反量化在整個編碼程序中占用了大概20%~25%的時間,所以有必要對他們的優化花一番功夫,本文舉整數DCT為例說明如何對程序進行匯編級的優化。H.264采用的整數DCT,不僅滿足一般DCT的特性,將圖像的能量集中到左上角位置,直流系數和低頻系數中,還有它特有的幾個優點:
-它是整數變換,所有的運算都是整數算法,變換矩陣系數十分簡單,核心變換部分可以僅僅用加法



評論