基于龍芯3B的H.264解碼器的向量化

3 ffmpeg的向量化
3.1 ffmpeg的oprofile測(cè)試
使用oprofile對(duì)ffmpeg解碼視頻“問(wèn)道武當(dāng)002.mkv”的過(guò)程進(jìn)行測(cè)試,測(cè)試結(jié)果如表2所示。表2列出了各個(gè)函數(shù)的調(diào)用過(guò)程以及運(yùn)行時(shí)間所占的比重。而針對(duì)ffmpeg解碼器進(jìn)行的向量化工作,則主要是針對(duì)oprofile測(cè)試結(jié)果中執(zhí)行時(shí)間較長(zhǎng)、運(yùn)行比重較大的幾個(gè)函數(shù)的向量化。
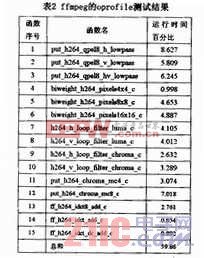
上述函數(shù)的執(zhí)行時(shí)間幾乎占據(jù)了ffmpeg解碼器執(zhí)行時(shí)間的60%,因而針對(duì)上述幾個(gè)函數(shù)進(jìn)行向量化,就完全可以達(dá)到提升ffmpeg整體解碼速度的目的。
3.2 針對(duì)龍芯3B的ffmpeg向量化
3.2.1 向量化方法
實(shí)現(xiàn)ffmpeg解碼器在龍芯3B上的向量化主要是使用龍芯3B擴(kuò)展的向量指令來(lái)改進(jìn)3.1節(jié)中oprofile測(cè)試結(jié)果中執(zhí)行時(shí)間比重較大的幾個(gè)函數(shù)。而且在向量化的同時(shí),同樣可以使用一些優(yōu)化策略,來(lái)提高向量化后的函數(shù)的性能。主要使用到的優(yōu)化方法包括:
(1)循環(huán)展開(kāi)。循環(huán)展開(kāi)是一種循環(huán)變換技術(shù),將循環(huán)體中的指令復(fù)制多份,增加循環(huán)體中的代碼量,減少循環(huán)的重復(fù)次數(shù)。需要說(shuō)明的是,循環(huán)展開(kāi)本身并不能直接提升程序的性能。
使用循環(huán)展開(kāi)的主要目的是充分挖掘指令或者數(shù)據(jù)間的并行性。其中向量擴(kuò)展指令的使用就是利用了展開(kāi)后的循環(huán)體內(nèi)數(shù)據(jù)的并行性;而在展開(kāi)后的循環(huán)內(nèi)使用指令調(diào)度和軟件流水技術(shù)則是為了充分利用指令間的并行性。
(2)指令調(diào)度。循環(huán)展開(kāi)后的循環(huán)體內(nèi)的指令數(shù)目增多,因而可以進(jìn)行指令調(diào)度,將不存在操作數(shù)相關(guān)性和不存在運(yùn)算部件相關(guān)性的指令調(diào)度到一起,這樣可以充分發(fā)揮龍芯3B的流水線性能,從而提高代碼在龍芯3B上的執(zhí)行速度。
除了使用龍芯3B的向量擴(kuò)展指令和使用上述兩種優(yōu)化方法以外,同樣還可以根據(jù)具體函數(shù)的特點(diǎn),使用其他一些優(yōu)化方法進(jìn)行優(yōu)化,比如使用邏輯運(yùn)算和移位運(yùn)算來(lái)代替乘法運(yùn)算等。針對(duì)每個(gè)函數(shù)的向量化優(yōu)化在3.2.2小節(jié)中介紹。
3.2.2 針對(duì)具體函數(shù)的向量化
3.2.1小節(jié)概述了向量化時(shí)用到的一些優(yōu)化方法,本節(jié)則針對(duì)oprofile測(cè)試中比重較大的幾個(gè)函數(shù)進(jìn)行有針對(duì)性的優(yōu)化。
對(duì)于表2中的函數(shù),我們可以根據(jù)函數(shù)名將其分類,函數(shù)命名類似的函數(shù)基本上都可以使用類似的優(yōu)化方法。
(1)簡(jiǎn)單向量化。對(duì)于1號(hào)和2號(hào)函數(shù)的優(yōu)化,本文都采用了使用移位運(yùn)算來(lái)代替乘法運(yùn)算的策略,并且針對(duì)循環(huán)內(nèi)部運(yùn)算的有界特性,使用飽和向量運(yùn)算來(lái)改進(jìn)。不過(guò)對(duì)于2號(hào)函數(shù)的訪存操作,由于存在著數(shù)據(jù)非對(duì)齊的情況,因而使用額外的向量指令對(duì)數(shù)據(jù)進(jìn)行打包和回寫。而3號(hào)函數(shù)則是1號(hào)和2號(hào)函數(shù)的混合,因而對(duì)1號(hào)和2號(hào)函數(shù)的優(yōu)化間接提升了3號(hào)函數(shù)的性能。
而對(duì)于4號(hào)、5號(hào)和6號(hào)函數(shù),本文僅對(duì)其內(nèi)層循環(huán)使用了循環(huán)展開(kāi)和指令調(diào)度策略,就能夠取得不錯(cuò)的運(yùn)算效果。
同樣,對(duì)于11和12號(hào)函數(shù)也可以比較直觀的進(jìn)行向量化,在此就不做詳述了。
(2)間接向量化。而對(duì)于比較難于向量化的7號(hào)和8號(hào)函數(shù),本文分別采用了使用掩碼和使用矩陣轉(zhuǎn)置運(yùn)算的策略來(lái)間接實(shí)現(xiàn)向量化。
其中針對(duì)函數(shù)h264 v loop filter luma的C語(yǔ)言實(shí)現(xiàn)中有很多判斷語(yǔ)句的問(wèn)題,本文使用構(gòu)建掩碼的方式來(lái)消除這些判斷語(yǔ)句。

以圖1(a)中的循環(huán)為例介紹掩碼的構(gòu)建。而圖1(b)所示為代替該循環(huán)的向量指令。具體的運(yùn)算結(jié)果如圖1(c)所示:將p向量(數(shù)組)和q向量做飽和減法(結(jié)果為負(fù)的都置為0),得到的結(jié)果向量如Vsub所示。使用Vsub與零向量進(jìn)行比較來(lái)設(shè)置掩碼:結(jié)果為真,掩碼值為0xFF;反之,結(jié)果為假,掩碼為0。最后將掩碼值與p向量進(jìn)行與操作,就可以得到該循環(huán)的運(yùn)算結(jié)果。
使用構(gòu)建掩碼的方法來(lái)消除判斷語(yǔ)句,不但減少了由判斷引起的時(shí)間開(kāi)銷,而且重要的是間接將循環(huán)進(jìn)行了向量化,提高了函數(shù)性能。而對(duì)于9號(hào)和10號(hào)函數(shù),可以使用同樣的方法來(lái)改進(jìn)。
而對(duì)于8號(hào)函數(shù),由于運(yùn)算處理的是連續(xù)的數(shù)據(jù),因而無(wú)法進(jìn)行向量化。使用矩陣轉(zhuǎn)置的方式,將數(shù)據(jù)重新打包后,就可以進(jìn)行相應(yīng)的向量運(yùn)算。

對(duì)于圖2(a)中的運(yùn)算,原始計(jì)算是P向量?jī)?nèi)部的運(yùn)算,因而無(wú)法向量化,我們用向量指令將p向量轉(zhuǎn)置為q,其中q0存放p中標(biāo)號(hào)為1的數(shù)據(jù),q1存放P中標(biāo)號(hào)為2的數(shù)據(jù),依此類推。轉(zhuǎn)置得到的q向量就可以用圖2(b)中的向量指令運(yùn)算,得到的運(yùn)算結(jié)果與原來(lái)的運(yùn)算相同。
對(duì)于13~15號(hào)函數(shù)的優(yōu)化,同樣使用到了上面的轉(zhuǎn)置方法。而4.1節(jié)的測(cè)試結(jié)果則說(shuō)明了各個(gè)函數(shù)的優(yōu)化效果。



評(píng)論