基于網絡設備的網頁過濾的設計

在網頁過濾技術中,URL 過濾是普遍采用的過濾方式,因為其設計實現非常簡單,速度快、效率高;但是互聯網是動態的,每天有數以萬計的新的網頁出現,URL 名單的更新速度往往跟不上;如果單純的采用URL 過濾,會造成過濾的遺漏
本文引用地址:http://www.104case.com/article/202467.htm內容過濾能夠實現實時的網頁內容防護,過濾比較準確,但是因為內容過濾過程比較復雜,處理量如果過大,會造成用戶上網的明顯延遲。
設計的方法是基于網絡層的網頁過濾方法,在網絡設備上實現對網頁的過濾。采用URL 過濾與內容過濾相結合的方式,取安全與性能的折中。
1 網頁過濾總體框架
一臺主機要訪問Web 服務器,首先與Web 服務器進行三次握手,建立TCP 連接;然后向Web 服務器發送請求報文,其中包含用戶訪問的URL,Web 服務器在收到請求報文后,會發送應答報文給客戶主機,因此過濾流程框架可按如下設計:
①在網絡設備中*用戶的數據包,檢測到HTTP 請求報文[3],則分析該報文中嵌入的網頁地址信息(即URL),提取出URL 信息,對其進行在黑白名單中進行匹配分析,根據匹配結果給予是否通過;②內容過濾采用“第一次放過”的策略,即第一次對未知URL 的返回報文僅做內容檢查。收集服務器返回的HTTP響應報文,提取出應用層信息,組成完整的HTML 文檔,進行內容過濾,根據判定結果進行相應的操作,整體過濾步驟如圖1 所示。
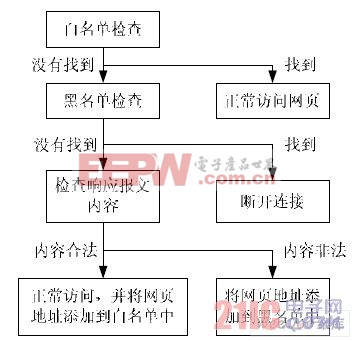
圖1 過濾模型
2 URL 過濾
2.1 相關定義
白(黑)名單:在該名單中的URL,必定是合(非)法的地址信息;未在該名單中的網址的合法性未知。
2.2 黑白名單機制的設計
URL 過濾框架的設計是基于兩個事實:
①因特網統計表明,超過80%的用戶經常訪問的是20%的網頁內容;②大多數用戶在多數時間內訪問的是合法信息的網頁。
基于上述事實一,設計白名單時,僅存放經常訪問的合法網站地址信息。這樣設計可以保證在進行URL 匹配時,能夠快速高效地判斷該網頁地址是否在高頻白名單中。對于一段時間內訪問頻率不高的網頁,采用老化機制將其從名單中移除。
基于上述事實二,設計將URL 白名單放在黑名單之前,若采用黑名單在前的方式,將會浪費大量時間去查找黑名單,而在大多數時間內,這些查找是不必要的。
2.3 URL 過濾
URL 過濾過程有:
①檢測通過網絡設備的報文,發現是HTTP 的GET 方法請求報文,提取其中攜帶的URL 信息,若與高頻名單中的條目匹配,表示該URL 為合法,給予通過,并將該條目的統計計數加1;②若在白名單中沒有匹配,則繼續和黑名單中的條目進行匹配。如果匹配成功,則斷開該TCP 鏈接,并且該匹配條目的統計計數加1;③若匹配失敗,則進行內容,根據內容過濾的結果將URL添加到相應名單中。
2.4 黑白名單老化機制
黑白名單老化機制步驟如下:
①計算名單中URL 條目訪問次數的平均值M,計算公式如公式1:
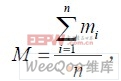
其中n 為表中的URL 條目數,mi為第i 個條目的統計計數值;②將老化閾值設為該平均值;③遍歷所有的URL 條目,檢查每個URL 條目的統計計數,若高于老化閾值,則將其保留在名單中,并且將統計計數值0,如果低于老化閾值,則將其剔除。


評論