SDN可編程交換芯片架構核心:RMT,一個可編程的網絡DSA

編者按
本文引用地址:http://www.104case.com/article/202407/461544.htmNick McKeown 在 ONF Connect 2019演講中定義了SDN發展的三個階段:
l第一階段(2010–2020年):通過Openflow將控制面和數據面分離,用戶可以通過集中的控制端去控制每個交換機的行為;
l第二階段(2015–2025年):通過P4編程語言以及可編程FPGA或ASIC實現數據面可編程,這樣,在包處理流水線加入一個新協議的支持,開發周期從數年降低到數周;
l第三階段(2020–2030年):展望未來,網卡、交換機以及協議棧均可編程,整個網絡成為一個可編程平臺。
(備注:引用部分為《軟硬件融合——超大規模云計算架構創新之路》圖書內容的節選。)
Nick為我們描繪了SDN網絡發展的一個非常美好的未來,而這美好未來的核心是可編程網絡DSA。Barefoot公司(Nick是Barefoot創始人之一,Intel于2019年收購了Barefoot)的核心競爭力在于圍繞著P4網絡編程語言構建的一整套芯片及軟件生態,其構建的全球唯一商用的可編程交換芯片的核心架構是PISA(Protocol Independent Switch Architecture,協議無關的交換架構),而PISA的原型來自于RMT(可重構匹配表)。
本文是RMT的經典論文,希望通過此篇論文,管中窺豹,能夠學習到PISA架構的核心精髓。
參考文獻
Forwarding Metamorphosis: Fast Programmable Match-Action Processing in Hardware for SDN, Pat Bosshart, Glen Gibb, Hun-Seok Kim, etc., SIGCOMM’13
(原標題)轉發變形:硬件實現的快速可編程SDN數據面匹配-動作處理
摘要
在SDN (Software Defined Networking)中,控制平面和轉發平面在物理上是分離的。控制軟件使用開放接口(如OpenFlow)對轉發平面(如交換機和路由器)進行編程。本文旨在克服當前交換芯片和OpenFlow協議的兩個限制:
當前硬件交換機非常嚴格,只允許在一組固定的字段上進行“匹配-動作”處理,
OpenFlow規范僅定義了有限的包處理動作集。
我們提出了RMT(可重構匹配表)模型,這是一種新的基于RISC的交換芯片流水線結構,我們確定了基本的最小動作原語集,以指定在硬件中如何處理報頭。RMT允許在不修改硬件的情況下在字段中更改轉發平面。與在OpenFlow中一樣,程序員可以指定多個任意寬度和深度的匹配表,只受總體資源限制,每個表可配置為在任意字段上進行匹配。然而,RMT允許程序員比OpenFlow更全面地修改所有報頭字段。本文描述了一個實現RMT模型的64端口10Gb /s開關芯片的設計。我們的具體設計表明,與社區內部的擔憂相反,靈活的OpenFlow硬件交換機實現幾乎不需要額外的成本或電力。
1 介紹
改進就是改變;要做到完美就要經常改變。——丘吉爾
好的抽象——比如虛擬內存和分時——在計算機系統中是至關重要的,因為它們允許系統處理變化,并允許在更高的層次上簡化編程。網絡的發展得益于關鍵的抽象:TCP提供端點之間連接隊列的抽象,IP提供從端點到網絡邊緣的簡單數據報抽象。然而,網絡中的路由和轉發仍然是一個令人困惑的集合,路由協議(如BGP、ICMP、MPLS)和轉發行為(如路由器、網橋、防火墻),控制和轉發平面仍然交織在封閉的、垂直集成的盒子中。
軟件定義網絡(SDN)在抽象網絡功能方面邁出了關鍵一步,它通過一個開放的接口(如OpenFlow[27])將控制平面和轉發平面的角色分離開來。控制平面被抬起并離開交換機,將其置于外部軟件中。這種對轉發平面的編程控制允許網絡所有者向其網絡添加新功能,同時復制現有協議的行為。OpenFlow作為一種基于“Match-Action”方法的控制平面和轉發平面之間的接口,已經非常出名了。粗略地說,數據包字節的子集與表相匹配;匹配的表項指定了對報文應用的相應動作。
我們可以想象在通用CPU上的軟件中執行Match-Action。但是對于我們感興趣的速度——今天大約1Tb/s——我們需要專用硬件的并行性。10年來,交換芯片的交換速度一直比CPU快兩個數量級,比網絡處理器快一個數量級,而且這種趨勢不太可能改變。因此,我們需要考慮如何在硬件中實現Match-Action來利用流水線和并行性,同時又受到片上表內存的限制。
在可編程性和速度之間有一個自然的權衡。如今,要支持新特性,經常需要更換硬件。如果Match-Action硬件允許在現場進行足夠的重新配置,以便在運行時支持新類型的包處理,那么它將改變我們對網絡編程的看法。這里真正的問題是,能否在不犧牲速度的情況下,以合理的成本完成這項工作。
單匹配表:最簡單的方法是在我們稱為SMT(單匹配表)模型中抽象匹配語義。在SMT中,控制器告訴交換機將任何一組報頭字段與單個匹配表中的條目進行匹配。SMT假設解析器定位并提取正確的報頭字段以與表匹配。例如,一個以太網包可能有一個可選的MPLS標記,這意味著IP報頭可以位于兩個不同的位置。當所有字段都完全指定時,匹配是二進制精確匹配,當某些位被關閉時,匹配是三元匹配(通配符項)。表面上,SMT抽象對程序員(還有什么比單一匹配更簡單的呢?)和實現者(SMT可以使用寬的三元內容可尋址內存(TCAM)來實現)都有好處。請注意,轉發數據平面抽象具有最嚴格的硬件實現約束,因為轉發通常需要以大約1Tb/s的速度運行。
然而,進一步觀察會發現,由于一個經典問題,SMT模型的使用成本很高。表需要存儲每個頭文件的組合;如果報頭行為是正交的(條目將有許多通配符位),那么這是浪費。如果一個報頭匹配影響到另一個報頭,則會更加浪費,例如,如果第一個報頭的匹配決定了第二個報頭匹配一組不相連的值(例如,在虛擬路由器[11]中),則需要表保存兩者的笛卡爾積。
多匹配表:MMT(多匹配表)是SMT模型的自然細化。MMT在一個重要方面超越了SMT:它允許多個較小的匹配表通過包字段的子集進行匹配。所述匹配表被布置成一系列的階段;階段j的處理可以依賴于階段i (i < j) 的處理,i階段修改報頭或其他信息然后傳遞給j階段;MMT很容易實現,在每個階段使用一組更窄的表;事實上,它與現有的交換芯片的實現方式非常接近,可以很容易地映射到現有的流水線上[3,14,23,28]。谷歌報告使用商業交換機芯片[13]將他們的整個私有廣域網轉換為這種方法。
OpenFlow規范轉變為MMT模型[31],但沒有規定表的寬度、深度,甚至表的數量,讓實現者可以自由選擇他們希望的多個表。雖然許多字段已經標準化(如IP和以太網字段),但OpenFlow允許通過用戶定義的字段設施引入新的匹配字段。
現有的交換芯片實現了少量(4-8)的表,其寬度、深度和執行順序在芯片制造時設置。但這嚴重限制了靈活性。用于核心路由器的芯片可能需要一個非常大的32位IP最長匹配表和一個小的128位ACL匹配表;用于L2橋的芯片可能希望有一個48位目的MAC地址匹配表和第二個48位源MAC地址學習表;企業路由器可能希望有一個較小的32位IP前綴表和一個更大的ACL表以及一些MAC地址匹配表。為每個用例制造單獨的芯片是低效的,因此商業交換機芯片往往被設計為支持所有通用配置的超集,并以預先確定的流水線順序安排一組固定大小的表。這給網絡所有者帶來了一個問題,他們希望調整表大小以優化他們的網絡,或者實現超出現有標準定義的新轉發行為。在實踐中,MMT通常轉換為固定的多個匹配表。
第二個更微妙的問題是,交換芯片只提供了與常見處理行為相對應的有限的操作集,例如轉發、刪除、減少TTL、推送VLAN或MPLS報頭以及GRE封裝。到目前為止,OpenFlow只指定了其中的一個子集。這個操作集不容易擴展,也不是很抽象。更抽象的操作集將允許修改任何字段,更新與包關聯的任何狀態機,并將包轉發到任意一組輸出端口。
可重構匹配表:因此,在本文中,我們探索了MMT模型的一個改進,我們稱之為RMT(可重構匹配表)。與MMT一樣,理想的RMT將允許一組流水線階段,每個階段都具有任意深度和寬度的匹配表。RMT超越了MMT,它允許以以下四種方式重新配置數據平面。
首先,可以修改字段定義并添加新字段;
其次,可以指定匹配表的數量、拓撲結構、寬度和深度,只受匹配位數的總體資源限制;
第三,可以定義新的操作,比如寫入新的擁塞字段;
第四,可以將任意修改的數據包放置在指定的隊列中,以便在端口的任意子集輸出,并為每個隊列指定排隊規則。
這種配置應該由一個SDN控制器來管理,但在本文中我們沒有定義控制協議。
考慮到最近幾年提出的新協議,如PBB[16]、VxLAN[22]、NVGRE[19]、STT[21]和OTV[20],可以看出RMT的好處。每個協議都定義了新的報頭字段。如果沒有像RMT這樣的體系結構,就需要新的硬件來匹配和處理這些協議。
注意,RMT與當前的OpenFlow規范完全兼容(甚至部分實現)。單個芯片顯然可以允許接口重新配置數據平面。事實上,一些現有的芯片,至少在一定程度上是受多個細分市場需求的驅動,已經有了一些可重構性,可以通過芯片的特別接口來表達。
許多研究人員已經認識到需要類似于RMT的東西,并提倡它。例如,IETF ForCES工作組開發了一個靈活的數據平面[17];類似地,ONF中的轉發抽象工作組也致力于可重構性[30]。然而,人們對RMT模型能否以非常高的速度實現持懷疑態度,這是可以理解的。如果沒有芯片提供RMT的存在證明,將控制器和數據平面之間的重構接口標準化似乎是徒勞的。
從直覺上看,以太比特速度任意重構似乎是一項不可能完成的任務。但在這些速度下,什么樣的受限形式的可重構性是可行的?受限制的可重構性是否涵蓋了我們前面提到的需求的足夠大的一部分?人們能否通過使用包含這些想法的硅來證明其可行性?與固定桌面的MMT芯片相比,這種RMT芯片有多貴?這些是我們在本文中要解決的問題。
通用Payload處理不是我們的目標。SDN/OpenFlow(以及我們的設計)的目標是確定在硬件中處理報頭的最小原語集。可以把它看作是像RISC那樣的最小指令集,它被設計成在大量流水線操作的硬件中運行得非常快。我們非常靈活的設計是在成本上具有競爭力的固定設計。在美國,靈活性幾乎不需要任何成本。
論文貢獻:我們的論文對以下爭論做出了具體貢獻:哪些轉發抽象在高速下是實用的,以及轉發平面在多大程度上可以由控制平面重新配置。具體來說,我們對上述問題的處理如下:
1)一個RMT的體系結構(第2章):我們描述了一個RMT交換體系結構,它允許定義任意的報頭和報頭序列,通過任意數量的表任意匹配字段,任意寫入包報頭字段(但不包括包體),以及每個包的狀態更新。為了實現該體系結構,引入了一些限制條件。我們概述了如何通過解析圖來表示所需的配置,以定義標題,以及表流圖來表示匹配表拓撲。
2)用例(第3章):我們提供的用例顯示了如何配置RMT模型來使用以太網和IP頭實現轉發,并支持RCP[8]。
3)芯片設計和成本(第4-5章):我們展示了我們所提倡的可重構性的具體形式是切實可行的,并描述了一個640Gb/s (64 x 10Gb/s)交換芯片的實現。我們的架構和實施研究包括邏輯和電路設計的重要細節,布圖規劃和布局,使用的技術經過設計團隊開發復雜數字集成電路的長期歷史證明。采用了工業標準的28nm工藝。這項工作是必要的,以證明可行性的目標,如時間和芯片面積(成本)。我們還沒有生產出一個完整的設計或實際的硅。根據我們的調查,我們表明重配置的成本預計是適中的:比固定(不可重配置)版本的成本高出不到20%。
我們并不聲稱我們是第一個提倡可重新配置匹配的人,或者我們所提議的重新配置功能是“正確的”。我們確實認為,重要的是通過對RMT模型進行具體定義,并通過展示芯片來證明它是可行的,就像我們在本文中試圖做的那樣。雖然芯片設計通常不是SIGCOMM的領域,但我們的芯片設計表明,RMT模型的一種相當普遍的形式是可行的,而且價格低廉。我們展示了RMT模型不僅是一種考慮網絡編程的好方法,而且還可以使用匹配表和動作處理器的可配置流水線在硬件中直接表達。
2 RMT架構
我們說RMT是“允許一組流水線階段……每個字段都有一個任意深度和寬度的匹配表”。一個邏輯推論是,RMT交換機由一個解析器組成,用于在字段上進行匹配,然后是任意數量的匹配階段。審慎性建議我們在輸出中加入某種排隊來處理擁塞。
讓我們再深入一點。解析器必須允許修改或添加字段定義,這意味著解析器是可重構的。解析器輸出是一個包報頭向量,它是一組報頭字段,如IP dest、Ethernet dest等。此外,包報頭向量包括“元數據”字段,如包到達的輸入端口和其他路由器狀態變量(例如,路由器隊列的當前大小)。向量流過一系列的邏輯匹配階段,每個階段抽象出圖1a中包處理(如以太網或IP處理)的邏輯單元。
每個邏輯匹配階段都允許配置匹配表的大小:例如,對于IP轉發,可能需要一個包含256K 32位前綴的匹配表,對于以太網,可能需要一個包含64K 48位地址的匹配表。輸入選擇器選擇要匹配的字段。包修改使用寬指令(圖1c中的VLIW-超長指令字)來完成,該指令可以同時對包報頭向量中的所有字段進行操作。
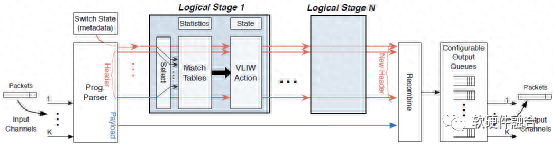
(a) RMT模型作為邏輯匹配動作階段的序列
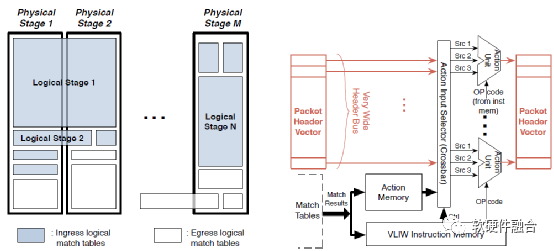
(b) 靈活的匹配表配置 (c) VLIW動作架構
圖1:RMT模型架構
更準確地說,包報頭向量中的每個字段F都有一個操作單元(圖1c),它最多可以接受三個輸入參數,包括頭向量中的字段和匹配的操作數據結果,并重寫F。允許每個邏輯階段重寫每個字段似乎有點過分,但它在移動頭文件時很有用;我們稍后將說明,與匹配表相比,動作單位成本較小。一個邏輯的MPLS階段可能彈出一個MPLS報頭,將后續的MPLS報頭向前移動,而一個邏輯的IP階段可能只是減少TTL。指令還允許修改有限狀態(例如計數器),這可能會影響后續包的處理。
控制流是通過提供下一個要執行的表的索引的每個表匹配的附加輸出來實現的。例如,階段1中特定以太類型上的匹配可以指導后面的處理階段在IP(路由)上進行前綴匹配,而不同的以太類型可以在以太網DA(橋接)上指定精確匹配。數據包的命運是通過更新一組目標端口和隊列來控制的;它可以用來丟棄數據包、實現多播或應用指定的QoS(如令牌桶)。
在流水線的末端需要一個重組塊來將包報頭向量修改推回數據包(圖1a)。最后,包被放置在指定輸出端口的指定隊列中,并應用一個可配置的隊列規則。
總之,圖1a的理想RMT允許通過修改解析器來添加新字段,通過修改匹配內存來匹配新字段,通過修改階段指令來執行新動作,通過修改每個隊列的隊列規則來創建新的隊列。理想的RMT可以模擬現有的設備,如網橋、路由器或防火墻;可以實現現有的協議,如MPLS、ECN,以及文獻中提出的協議,如使用非標準擁塞字段的RCP[8]。最重要的是,它允許將來在不修改硬件的情況下修改數據平面。
2.1 在640Gbps下的實現架構
我們提倡如圖1b所示的實現體系結構,它由大量的物理流水線階段組成,根據每個邏輯階段的資源需求,可以將少量的邏輯RMT階段映射到這些物理流水線階段。這個實現架構的動機是:
分解狀態:路由器轉發通常有幾個階段(如轉發、ACL),每個階段使用一個單獨的表;將這些組合到一個表中會產生狀態的叉積。階段是通過依賴順序處理的,因此物理流水線是自然的。
靈活的資源分配最小化資源浪費:物理流水線階段有一些資源(如CPU、內存)。邏輯階段所需的資源可能有很大差異。例如,防火墻可能需要所有ACL,核心路由器可能只需要前綴匹配,邊緣路由器可能各種資源都需要一些。通過靈活地將物理階段分配到邏輯階段,可以重新配置流水線,將其從防火墻轉變為現場的核心路由器。物理階段N的數量應該足夠大,以便使用很少資源的邏輯階段最多浪費1/N的資源。當然,增加N將增加開銷(布線、功率):在我們的芯片設計中,我們選擇N = 32作為減少資源浪費和硬件開銷之間的折衷。
布局優化:如圖1b所示,通過將邏輯階段分配給多個連續的物理階段,可以為邏輯階段分配更多內存。另一種設計是通過交叉開關[4]將每個邏輯階段分配給一組解耦的存儲器。雖然這種設計更加靈活(任何內存組都可以分配到任何階段),但在最壞的情況下,處理階段和內存之間的線延遲至少會以sqrt(M)的速度增長,而在需要大量內存的路由器芯片中,M可以很大。雖然這些延遲可以通過流水線來改善,但這種設計的終極挑戰是布線:除非減少當前的匹配和動作寬度(1280位),否則在每個階段和每個內存之間運行如此多的布線可能是不可能的。
總而言之,圖1b的優勢在于它使用了帶有短線的平鋪架構,其資源可以以最小的浪費重新配置。我們承認有兩個缺點。首先,物理階段的數量越多,對能量的需求就越高。第二,這個實現體系結構合并了處理和內存分配。需要更多處理的邏輯階段必須分配給兩個物理階段,但是即使它可能不需要內存,它也會得到兩倍的內存。實際上,這兩個問題都不重要。我們的芯片設計顯示,階段處理器的功耗最多是總功耗的10%。其次,在網絡中,大多數用例是由內存使用而不是處理決定的。
2.2 可實現性限制
物理流水線階段架構需要限制以允許tb級速度實現:
1、匹配限制:設計必須包含固定數量的物理匹配階段和固定的資源集。我們的芯片設計在入口和出口提供了32個物理匹配階段。在出口的匹配動作處理允許更有效地處理組播數據包,通過延遲每個端口的修改,直到緩沖之后。
2、包報頭限制:包含用于匹配和操作的字段的包報頭向量必須受到限制。我們的芯片設計限制是4Kb (512B),這允許處理相當復雜的頭。
3、內存限制:每個物理匹配階段都包含相同大小的表內存。通過將每個邏輯匹配階段映射到多個物理匹配階段或其分數,可以近似得到任意寬度和深度的匹配表(見圖1b)。例如,如果每個物理匹配階段只允許1000個前綴條目,那么2000個IP邏輯匹配表將分兩個階段實現(圖1b左上角的矩形)。同樣,一個小型Ethertype匹配表可能會占用匹配階段內存的一小部分。
SRAM中基于哈希的二進制匹配比TCAM的三元匹配便宜6倍。兩者都是有用的,因此我們在每個階段提供固定數量的SRAM和TCAM。每個物理階段包含106個1K 112b SRAM塊,用于80b寬哈希表(開銷位稍后解釋)和存儲操作和統計數據,以及16個2K 40b TCAM塊。塊可以并行地用于更寬的匹配,例如,使用四個塊的160b ACL查找。32級的總內存為370 Mb SRAM和40 Mb TCAM。
4、動作限制:為了可實現,每個階段的指令數量和復雜性必須受到限制。在我們的設計中,每個階段可以在每個字段執行一條指令。指令僅限于簡單的算術、邏輯和位操作(見4.3)。這些操作允許實現RCP[8]這樣的協議,但不允許在包體上進行包加密或正則表達式處理。
指令不能實現狀態機的功能;它們只能修改包報頭向量中的字段、更新有狀態表中的計數器或將包直接發送到端口/隊列。隊列系統提供了四個層次和每個端口2K隊列,允許赤字輪循、分層公平隊列、令牌桶和優先級的各種組合。但是,它不能模擬WFQ所需的排序。
在我們的芯片中,每個階段包含超過200個動作單元:一個用于包報頭向量中的每個字段。芯片中包含超過7000個動作單元,但與內存相比,這些單元占用的面積很小(<< span="">10%)。動作單元處理器是簡單的,特別的架構,以避免昂貴的執行指令,并需要少于100門每位。
這樣的RMT體系結構應該如何配置?需要兩段信息:表示允許的報頭序列的解析圖,以及表示匹配表集和它們之間的控制流的表流圖(參見圖2和4.4)。理想情況下,編譯器執行從這些圖到適當的交換配置的映射。我們還沒有設計出這樣的編譯器。
3 示例用例
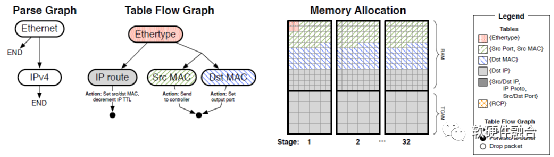
(a) L2/L3交換
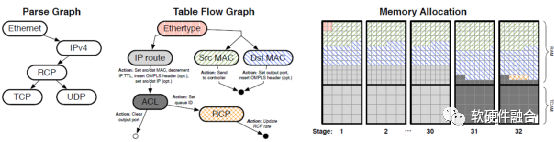
(b) RCP和ACL支持
圖2 交換配置示例
為了對如何使用RMT芯片有更深層次的理解,我們將看兩個用例。
例1:L2/L3開關。
首先,我們需要配置解析器、匹配表和操作表。對于我們的第一個示例,圖2a顯示了L2/L3交換機的解析圖、表流圖和內存分配。解析圖和表流圖告訴解析器在寬報頭總線上提取和放置四個字段(Ethertype、IP DA、L2 SA、L2 DA)。表流圖告訴我們應該從寬頭總線讀取哪些字段并在表中匹配。內存分配告訴我們如何將這四個邏輯表映射到物理內存階段。在我們的示例中,Ethertype表自然屬于階段1,其余三個表分布在所有物理階段,以最大限度地擴大它們的大小。大多數哈希表RAM是在L2 SA和DA之間分割的,每個有120萬個條目。我們致力于32個階段的TCAM條目,以容納100萬個IP DA前綴。最后,我們需要存儲VLIW動作原語,以便在匹配后執行(例如,出口端口,減少TTL,重寫L2 SA/DA)。這需要30%的階段RAM內存,剩下的留給L2 SA/DA。如果啟用,包和字節計數器也將消耗RAM, L2表大小減半。
一旦配置完成,控制平面就可以開始填充每個表,例如通過添加IP DA轉發表項。
例2:支持RCP和ACL。
我們的第二個用例為簡單的防火墻添加了速率控制協議(RCP)支持[8]和ACL。RCP通過交換顯式地指示流量的公平共享率,從而減少了流量完成時間,從而避免了使用TCP慢啟動的需求。公平共享速率被每個開關標記到RCP報頭中。圖2b顯示了新的解析圖、表流圖和內存分配。
為了支持RCP,數據包的當前速率和估計的RTT字段被解析器提取并放置在頭部向量中。第32階段的出口RCP表更新出包的RCP速率——小的動作選擇包當前速率和鏈路公平共享速率中較小的那個。(公平份額比率由控制平面定期計算。)
有狀態表(第4.4節)積累計算公平份額率所需的數據。狀態表在第32階段實例化,并為每個目標端口累積字節和RTT和。
我們還從TCAM的最后兩個階段創建了20K ACL條目(120b寬),將L3表的前綴減少到960K,以及保存相關操作(例如,drop、log)的RAM條目。
在實踐中,用戶不應該關注底層配置細節,而應該依賴編譯器從解析圖和表流圖生成開關配置。
4 芯片設計

圖3 交換芯片架構
到目前為止,我們使用了方便網絡用戶的RMT轉發平面的邏輯抽象和實現RMT的物理體系結構。
現在我們描述實現設計細節。我們選擇1 GHz交換芯片工作頻率,因為在64個10 Gb/s端口的總吞吐量960MPPS,一個流水線可以處理所有輸入端口數據,服務所有端口,而在較低的頻率,我們需要使用多個這樣的流水線,需要附加一些區域開銷。交換IC的框圖如圖3所示。注意,這與圖1a的RMT體系結構圖非常相似。
輸入信號由64個10Gb SerDes IO模塊接收。40G通道由4個10G端口組在一起組成。經過執行低級信令和CRC生成/檢查等MAC功能的模塊后,輸入數據由解析器處理。我們使用16個入口解析器塊,而不是圖1a中所示的單個邏輯解析器,因為我們的可編程解析器設計可以處理40Gb的帶寬,四個10G通道或一個40G通道。
解析器接受單個字段位于可變位置的包,并輸出一個固定的4kb包報頭向量,其中每個解析字段被分配一個固定的位置。位置是靜態的,但可以配置。字段的多個副本(例如,多個MPLS標簽或內部和外部IP字段)被分配到包報頭向量中唯一的位置。
輸入解析器的結果被多路復用到單個流中,以提供由32個順序匹配階段組成的匹配流水線。一個大的共享緩沖區提供存儲來容納由于輸出端口過度訂閱而導致的排隊延遲;根據需要將存儲分配給通道。分離者將數據包報頭向量中的數據重新組合到每個數據包中,然后存儲在公共數據緩沖區中。
隊列系統與公共數據緩沖區相關聯。數據緩沖區存儲數據包數據,而指向該數據的指針保存在每個端口的2K隊列中。每個通道依次使用可配置的隊列策略從公共數據緩沖區請求數據。接下來是出口解析器、出口匹配流水線(由32個匹配階段組成)和分離器,在分離器之后,包數據被定向到適當的輸出端口并由64個SerDes輸出通道驅動出芯片。
雖然單獨的32步出口處理流水線似乎有點小題大做,但我們表明出口和進口流水線共享相同的匹配表,因此成本最低。此外,出口處理允許組播數據包通過端口被定制(比如它的擁塞位或MAC目的地),而無需在緩沖區中存儲幾個不同的數據包副本。現在我們描述設計中的每個主要組件。
4.1 可配置的Parser
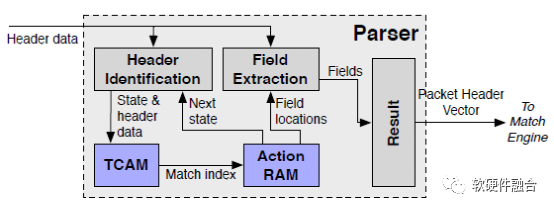
圖4 可配置的Parser模型
解析器接受輸入的包數據并生成4K位包報頭向量作為輸出。解析由用戶提供的解析圖(如圖2)指導,通過脫機算法轉換為256條目40b TCAM中的條目,該條目匹配入包數據的32b和解析器狀態的8b。注意,這個解析器TCAM與每個階段中使用的匹配TCAM是完全分離的。例如,當以太類型的16位到達時,CAM匹配32位中的16位(通配符匹配其余部分),更新指示下一個報頭類型(例如VLAN或IP)的狀態,以指導進一步解析。
更一般地說,TCAM匹配的結果會觸發一個操作,該操作更新解析器狀態,將傳入數據移動指定字節數,并將一個或多個字段的輸出從輸入包中的位置定向到包報頭向量中的固定位置。重復這個循環來解析每個包,如圖4所示。通過將關鍵更新數據(如輸入移位計數和下一個解析器狀態)從RAM中提取到TCAM輸出優先級邏輯中,循環得到了優化。解析器的單循環循環以32Gb/s的速度匹配字段,這意味著更高的吞吐量,因為不是所有字段都需要解析器匹配。一個單獨的解析器實例很容易支持一個40Gb/s的包流。
4.2 可配置的Match內存
每個匹配階段包含兩個640b寬匹配單元,一個TCAM用于三元匹配,一個基于SRAM的哈希表用于精確匹配。SRAM哈希單元的位寬由8個80b子單元聚合而成,而三元表則由16個40b TCAM子單元組成。這些子單元可以單獨運行,也可以分組以獲得更寬的寬度,或者組合在一起以形成更深的表。輸入交叉開關為每個子單元提供匹配數據,子單元從4Kb包報頭向量中選擇字段。如前所述(圖1b),相鄰匹配階段的表格可以組合成更大的表格。在限制下,所有32個階段都可以創建一個表。
此外,圖3中的入口和出口匹配流水線實際上是同一個物理塊,在入口和出口線程之間以細粒度共享,如圖1b所示。為此,首先在輸入和輸出向量之間共享包報頭向量;向量中的每個字段都被配置為由入口線程或出口線程擁有。其次,每個字段對應的功能單元以相同的方式分配入或出。最后,每個內存塊分配給入口或出口。不會出現爭用問題,因為每個字段和內存塊都是由出口或入口獨占的。
每個匹配階段有106個包含1K項x 112b的RAM塊。分配給匹配、操作和統計內存的RAM塊的分片是可配置的。精確匹配表被實現為布谷鳥哈希表[10,26,32],(至少)有四種1K條目的方式,每一種方式都需要一個RAM塊。讀取是確定地在一個周期內執行的,所有的方式都是并行訪問的。每個比賽階段也有16個TCAM塊,每塊為2K項x 40b,可以組合成更寬或更深的表。
與每個匹配表RAM條目相關聯的是一個指向動作內存和動作大小的指針,一個指向指令內存的指針,以及下一個表地址。動作內存包含參數(例如,在輸出封裝中使用的下一跳信息),指令指定要執行的函數(例如,添加頭)。動作內存和匹配內存一樣,由8個更窄的單元組成,每個單元包含1K個112位字,每個單元產生96b數據(以及字段有效位和內存ECC位-錯誤糾正碼)。操作內存從106個RAM塊中分配,而操作指令保存在一個單獨的專用內存中。
與OpenFlow一樣,我們的芯片為每個流表條目存儲包和字節統計計數器。這些計數器的完整64b版本包含在片外DRAM中,芯片上使用1K RAM塊并應用LR(T)算法[33]提供可接受的DRAM更新速率的有限分辨率的計數器。一個字的統計內存可配置地容納兩個或三個流條目的計數器,允許在統計內存成本和DRAM更新速率之間進行權衡。每個計數器增量都需要一個讀寫內存操作,但在1GHz的流水線中,每個包只有一個操作可用,因此通過增加一個內存塊,就合成了第二個內存端口。
4.3 可配置的動作引擎
為每個包報頭字段提供一個單獨的處理單元(參見圖1c),以便所有字段都可以被同時修改。包報頭向量中分別有64、96和64個字(8、16和32b),每個單詞對應一個有效位。較小的字的單位可以組合起來執行一個較大的字段指令,例如,兩個8b的單位可以合并成一個單獨的16b字段來操作它們的數據。每個VLIW包含每個字段字的單個指令字段。
OpenFlow指定了簡單的操作,如將字段設置為值,以及復雜的操作,如PBB封裝和從內到外或從外到內的TTL副本,其中外部和內部字段可能是眾多選擇之一。復雜的修改可以是低速的子例程,但必須在我們的1GHz時鐘速率下使用精心選擇的指令集將其簡化為單周期操作。

表1:部分動作指令集
表1是我們的操作指令的子集。
Deposit-bype允許從源字的任意位置存儲任意字段到背景字的任意位置。
Rot-mask-merge獨立地旋轉兩個源,然后根據一個字節掩碼合并它們,這在執行Pv6到IPv4地址轉換[18]時很有用。
bitmask-set用于選擇性的元數據更新;它需要三個源:兩個源要合并和一個位掩碼。
Move,和其他操作符一樣,只會在源有效的情況下將源移動到目的地,也就是說,如果該字段存在于包中。
另一個通用的可選條件化是目標有效。cond-move和cond-mux指令對于從內到外和從外到內的字段拷貝是有用的,其中內部和外部字段是依賴于包的。例如,一個到MPLS標簽的從內到外的TTL拷貝可以從內部MPLS標簽獲取TTL(如果它存在的話),或者從IP頭獲取TTL。移位、旋轉和字段長度值通常來自指令。一個源操作數從包報頭向量中選擇字段,而第二個源操作數從包報頭向量或動作字中選擇字段。
一個復雜的操作,如PBB、GRE或VXLAN封裝,可以被編譯成一個單獨的VLIW指令,然后被認為是一個原語。靈活的數據平面處理也可以用網絡處理器、FPGA或軟件實現操作,但是需要更高的成本功能才能達到640Gb/s。
4.4 其他特性
通過依賴分析減少延遲:通過要求物理匹配階段I只在階段I-1完全完成處理P后才處理包頭向量P,可以很容易地確保正確性。但在許多情況下,這是過度殺傷,并可能嚴重增加延遲。減少延遲的關鍵是在連續的階段確定匹配表之間的三種依賴關系:匹配依賴關系、動作依賴關系和繼承依賴關系[2],每一種都在下面描述。

圖5 匹配階段依賴
當一個匹配階段修改數據包報頭字段,并且隨后的階段對該字段進行匹配時,就會產生匹配依賴。在這種情況下不可能有執行重疊(圖5a)。當匹配階段修改數據包報頭字段,而后續階段使用該字段作為動作的輸入時,動作依賴就會發生,例如,如果一個階段設置了一個TTL字段,而下一個階段減少了TTL。部分執行重疊是可能的(圖5b)。當匹配階段的執行是基于前一階段的執行結果時,就會產生后續依賴關系;前一階段的執行可能會導致后續階段被跳過。如果后續階段是推測運行的,并且在后續結果提交之前解決了預測,則后續階段可以與其前身階段并發運行(圖5c)。沒有依賴關系的表也可以同時運行。連續階段之間的流水線延遲是在圖5的三個選項之間靜態配置的,分別針對入口和出口線程。
組播和ECMP:組播處理在入口和出口之間進行分割。輸入處理寫入輸出端口位向量字段,以指定輸出,并可選地寫入用于以后匹配的標記和路由到每個端口的副本數量。每個多播包的一個副本存儲在數據緩沖區中,多個指針放置在隊列中。當數據包被注入出口流水線時,就會創建副本,在出口流水線中,表可以匹配標簽、輸出端口和數據包拷貝計數,以允許每個端口的修改。ECMP和uECMP處理類似。
計量器和狀態表:計量器對匹配表項的流量速率進行測量和分類,可用于修改或丟棄報文。計量只是有狀態表的一個例子,其中一個操作修改了后續包可見的狀態,并可用于修改它們。可以任意增加和重置的有狀態計數器。例如,它們可以用來實現GRE序列號(在每個封裝包中遞增)和OAM[15,25]。
一致性和原子更新:為了允許一致性更新[34],版本信息包含在表項中,版本ID通過流水線與每個包一起流動,根據版本兼容性對表進行匹配。
5 評估
相對于傳統的可編程開關芯片,我們通過增加設計面積和功耗來描述可配置性的成本。我們的比較在第5.5節中對總芯片面積和功耗進行了比較。為了達到這個目的,我們依次考慮解析器、匹配階段和動作處理,從而考慮成本的組成。
5.1 可編程解析器成本
可編程性是有代價的。傳統解析器針對一個解析圖進行優化,而可編程解析器必須處理任何受支持的解析圖。通過比較常規設計和可編程設計的綜合結果來評估成本。圖6顯示了實現幾個解析圖和一個可編程解析器的傳統解析器的總門數。我們假設通過組合運行在1GHz的40 Gb/s解析器的16個實例,解析器的總吞吐量為640 Gb/s。所有設計的結果模塊在解析時都包含4Kb的包報頭向量。該可編程解析器使用256 x 40位TCAM和256 x 128位動作RAM。

圖6 提供640Gb/s聚合吞吐量的Parser總門數
解析器門計數由填充解析器報頭向量的邏輯決定。傳統設計需要290 - 300萬個門,這取決于解析圖,而可編程設計需要560萬個門,其中160萬個由增加的TCAM和動作RAM模塊貢獻。從這些結果來看,解析器可編程性的成本約為2(5.6/3.0 = 1.87 ≈ 2)。
盡管將解析器門數增加了一倍,但解析器只占芯片總體面積不到1%,因此使解析器可編程的成本不是問題。
5.2 內存成本
讀者可能會擔心內存的成本。
首先,內存技術本身(哈希表,TCAM)相對于標準SRAM內存的成本,以及將內存分割成可以重新配置的更小塊的成本;
其次,每個匹配表條目需要額外的數據來指定操作和保持統計數據;
第三,當一個48位的以太網目的地址被放置在112位寬的內存中時,有內部碎片的成本。
我們輪流處理每個開銷,并特別指出可編程性的(小的)額外成本。在接下來的內容中,我們將匹配表(例如48位以太網DA)中的條目稱為流條目。
5.2.1 內存技術成本
精確匹配:我們使用布谷鳥哈希進行精確匹配,因為它的填充算法占用率很高,對于4路哈希表,通常超過95%。布谷鳥哈希表通過遞歸地將沖突項逐出到其他位置來解決填充沖突。此外,雖然我們的內存系統是由1K × 112位RAM塊構成的,但與使用更大、更高效的內存單元相比,可能會有一個面積代價。然而,使用1K RAM塊只會帶來大約14%的面積損失,可以說是該技術實現的最密集的SRAM模塊。
通配符匹配:我們在芯片上使用了大量的TCAM,直接支持前綴匹配、ACL等通配符匹配。TCAM傳統上被認為是不可行的,因為電力和地區的考慮。然而,TCAM的工作功率已經被新的TCAM電路設計技術[1]減少了大約4/5。因此,在最壞的情況下,在所有通道上的最小包大小的最大包速率下,TCAM功率是對總芯片功率的少數幾個主要貢獻者之一;在更典型的長包和短包混合物中,TCAM功率降低到總功率的一個非常小的比例。
其次,相當于一個等效的比特數SRAM,TCAM通常需要6-7倍的面積,三元和二元流項都有與它們相關的其他位,包括動作內存、統計計數器、指令、動作數據和下一個表指針。例如,使用32位IP前綴、48位統計計數器和16位動作內存(假設用于指定下一跳),TCAM部分僅為內存比特數的1/3,因此TCAM的面積代價降至3左右。
雖然3倍是重要的,考慮到32b (IPv4)或128b (IPv6)最長前綴匹配和ACL是所有現有路由器的主要使用案例,為TCAM投入大量資源以允許1M IPv4前綴或300K ACL似乎是有用的。雖然我們可以使用具有特殊用途的LPM算法的SRAM,而不是像[6]那樣,實現32位或128位LPM的TCAM的單周期延遲是非常困難甚至不可能的。然而,決定三元表和二進制表容量的比率(我們的芯片提出1:2的比率)是一個重要的實現決策,具有重大的成本影響,目前還沒有什么現實世界的反饋。
5.2.2 動作規格的代價
除了流條目外,每個匹配表RAM條目還有一個指向動作內存(13b)的指針,一個動作大小(5b)的指針,一個指向指令內存(32條指令的5b)的指針,以及一個下一個表地址(9b)。對于最窄的流入口來說,這些額外的位大約占35%的開銷。也有版本和錯誤校正位,但這些是常見的任何匹配表設計,所以我們忽略他們。
除了流條目中的開銷位外,還需要其他內存來存儲操作和統計信息。這些增加了總開銷(匹配字段所需的總位數與匹配字段位的比率),但有時這兩種額外成本都可以降低。我們將展示如何在某些情況下減少流入口開銷位。此外,應用程序需要不同數量的操作內存,有時不需要統計數據,因此可以減少或消除這些內存成本。
給定匹配、操作和統計數據之間的內存塊的可變配置,我們使用一些配置示例來了解與不可配置的固定分配相比,記帳開銷是如何變化的。

圖7 匹配階段單元內存映射示例
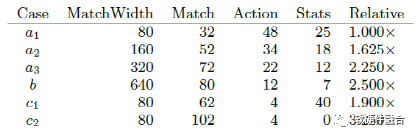
表2 內存單元分配和相對精確匹配容量
在第一個配置中,如圖7a和表2所示,在一個階段中使用32個內存塊來匹配內存,實現32K 80b寬的精確匹配流條目。另一個16K 80b三元項在TCAM模塊中。所有流條目都具有相同大小的操作條目,操作需要48個內存。統計信息消耗24個內存塊組,以及用于多移植統計信息內存的備用存儲塊組。為每個匹配內存分配大約相等的操作內存份額,可以將其視為具有最小流表容量的基本情況。
除去用例a中用于三元操作和統計的24個塊組,用于二元操作的銀行中有40%是匹配表,這表明開銷為2.5倍。再加上匹配表中35%的位開銷,總的二進制開銷是3.375,即總比特數與匹配數據比特數的比率。換句話說,只有三分之一的RAM位可以用于流入口。
表2中的用例a2和a3將匹配寬度分別更改為160和320位,減少了動作和統計需求,增加了匹配容量。
配置表2的b進一步增加二元和三元流表匹配寬度640位,如圖7所示(水平的內存寬度顯示),比基本情況,減少8倍流條目的數量,以及所需的動作和統計能力。雖然這種廣泛的匹配可能很少見(比如整個標題匹配),但我們看到,與上面的基本情況相比,有8個更寬的流條目,80個塊組可以用于精確匹配,內存容量的75%,比基本情況高2.5個表容量。
表2的c1配置,如圖7c所示,利用了單個操作數量有限的用例。例如,一個數據中心地址虛擬化應用程序需要大量的流條目,但是匹配條目可能指向TOR交換機的1000個可能的目的地中的一個。因此4K的動作內存就足夠了。這將允許62個內存塊用于匹配,40個內存塊用于統計,幾乎是基本情況下精確匹配條目數量的兩倍。如果不需要統計信息,則可以使用102個內存塊進行匹配,如表項c2所示,占總內存容量的96%。
簡而言之,如果動作或統計數據減少或消除,流入密度將大大增加。如果芯片的用戶認為這些復雜的操作和統計數據是必要的,那么將這種開銷歸咎于芯片可配置選項是不公平的。唯一可以直接歸因于可編程性的基本記事簿成本是指令指針(5b)和下一個表地址(9b),大約占15%。
在固定行為的表格中,成本可以進一步降低。一個固定函數表使用相同的指令和下一個表指針為所有的條目,例如,L2 dest MAC表;可以為這些屬性配置靜態值,允許14位指令和下一表指針被回收以匹配。更一般地,流條目中的可配置寬度字段可以選擇性地為操作、指令或下一表地址提供LSB,從而允許減少不同指令或操作的數量,或為下一表尋址一個小數組,同時回收盡可能多的指令、下一個表、和動作地址位盡可能考慮到功能的復雜性。
接下來,表可以提供一個動作值作為一個直接常量,而不是小常量的動作內存指針,從而保存指針和動作內存位。
一個簡單的機制可以實現這些優化:匹配表字段邊界可以靈活配置,允許每個字段具有任意大小的表配置范圍,受總位寬限制。帶有固定或幾乎固定函數的表可以有效地實現,與固定的表相比幾乎沒有任何損失。
5.2.3 交叉開關成本
每個階段中的交叉開關從報頭向量中選擇匹配表輸入。從4Kb輸入向量中選擇1280個輸出位(TCAM和哈希表各為640b)。每個輸出位由一個224輸入多路復用器驅動,該多路復用器由與-或-反 AOI22門 的二叉樹組成,每多路復用器輸入成本為0.65μm2。總橫木面積為1280 x 224 x 0.65μm2 x 32階段 ≈ 6 mm2。動作單元數據輸入多路復用開關的面積計算也是類似的。
5.3 碎片的成本
最后一個開銷是內部分裂或打包的成本。顯然,放置在112b寬內存中的48位以太網目的地址浪費了超過一半的內存。相比之下,固定功能的以太網橋包含定制的48位寬RAM。因此,這一成本完全歸因于可編程性和我們選擇的112b寬RAM。人們可以通過選擇48b作為基本RAM寬度來減少以太網的這種開銷,但是為通用用途(和未來協議)設計的芯片如何預測未來的匹配標識符寬度呢?
幸運的是,通過另一種架構技巧,甚至可以減少這種開銷,這種技巧允許將流條目集打包在一起,而不損害匹配功能。例如,標準的TCP 五元組是104位寬。其中三個條目可以被打包到四個寬度為448b的內存單元中,而不是分別要求每個條目消耗兩個內存單元。或者,使用相當于簡單成功/失敗的低輸入開銷,由于ECC比特在更寬的數據上的攤銷,其中4個可以被打包成4個字。從根本上說,這是可行的,因為本質上,較長的匹配是由較小的8位匹配樹構建的;靈活性只是稍微使這個邏輯復雜化了一些。
這兩種技術的結合,將可變數據打包到一個數據字(以降低操作規范成本),和將可變流輸入打包到多個數據字(以降低碎片成本)確保了在廣泛配置下的高效內存利用。總而言之,雖然傳統的交換機對特定的表配置有高效的實現,但這種架構可以達到這種效率,不僅對那些特定的表配置,而且對許多其他配置也是如此。
5.4 動作可編程性的成本
除了指令RAM和動作存儲器的成本,大約有7000個處理器數據路徑,寬度從8位到32位不等。幸運的是,因為它們使用簡單的RISC指令集,它們的總面積只占用芯片的7%。
5.5 面積及功耗成本
這個交換機設計有很大的匹配表容量,所以匹配和動作存儲器很大程度上貢獻了芯片面積估計,如表3所示。第一項包括IO、數據緩沖區、CPU等,在傳統交換機中占據了類似的區域。可以看出,VLIW動作引擎和解析器/分離器對區域的貢獻相對較小。

表3 評估芯片面積
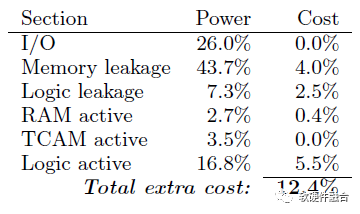
表4 評估芯片功耗
我們之前提出過,與最優的RAM設計相比,匹配階段單元RAM遭受了14%的面積懲罰。考慮到對匹配階段SRAM(不是TCAM)面積的懲罰,以及與傳統交換機(15%)相比額外比特數的一些許可,剩余內存區域約為芯片總數的8%。如果解析器和動作引擎中的多余邏輯又增加了6.2%,那么就會產生14.2%的區域成本,這證明了之前宣稱的低于15%的成本差異是正確的。
評估的交換機最壞操作條件(溫度、芯片處理)下的功耗詳情見表4,100%流量混合大包(1.5KB)小包各一半的數據包,以及所有匹配和動作表填滿容量的情況下,評估的交換功率詳見表4。輸入/輸出功率相當于一個常規開關。內存泄漏功率與內存比特數成正比,所以如果這個可編程交換機可以實現與傳統交換機相同的比特數,功率將是相當的。剩下的部分,總數為30%,比傳統的交換機少,因為減少了功能的匹配動作流水線。我們估計,可編程芯片比傳統的交換機多消耗12.4%的功率,但執行更實質性的包操作。
與傳統交換機的整體競爭評估表明,該交換機可以用相同的存儲位數執行相同的功能。這反過來又推動了芯片成本和功率方面的優勢。考慮到交換機的更全面的功能,可編程解決方案所承擔的額外功耗和面積成本非常小。
6 相關工作
靈活的處理可以通過許多機制實現。在處理器上運行軟件是一種常見的選擇。我們的設計性能比CPU高出兩個數量級[7],比GPU和NPU高出一個數量級[5,9,12,29]。
現代FPGA,如Xilinx Virtex-7[35],可以以接近1Tb/s的速度轉發流量。不幸的是,FPGA提供更低的總內存容量,模擬TCAM很差,消耗更多的電力,而且非常昂貴。目前最大的Virtex-7設備是Virtex-7 690T,總內存為62Mb,約占我們芯片容量的10%。來自兩個匹配階段的TCAM將消耗用于實現用戶邏輯的大部分查找表(LUT)。產品清單價格超過10,000美元,這比我們芯片的預期價格高出一個數量級。這些因素一起排除了FPGA作為解決方案的可能性。
與NPU相關的是PLUG[6],它提供了許多通用的處理核心,與內存和路由資源配對。將處理過程分解成數據流圖,數據流圖分布在整個芯片上。PLUG主要關注于實現查找,而不是解析或包編輯。
英特爾FM6000 64端口10Gb/s交換芯片[24]包含一個可編程解析器,由32個階段構建,每個階段都有一個TCAM。它還包括一個兩級匹配行動引擎,每個級包含12塊1K 36b TCAM。這只占總表容量的一小部分,其他表在固定的流水線中。
最新的OpenFlow[31]規范提供了一個MMT抽象,并部分實現了一個RMT模型。但是它的動作能力仍然是有限的,并且它也不確定是否會有一個功能完整的動作標準。
7 總結
理想情況下,交換機或路由器應該使用多年。應對不斷變化的世界需要可編程性,允許軟件升級在該領域添加新功能和新協議。網絡處理器(NPU)被引入來支持這一愿景,但無論是NPU還是GPU都無法接近使用ASIC實現固定功能交換機的速度;我們也沒有見過對基于NPU的路由器(如思科的CRS-1)進行重新編程以添加新協議的案例研究。同樣地,FPGA最近才達到ASIC轉發速度,但仍然非常昂貴。
我們的芯片設計再現了這種古老的可編程性愿景,在RMT模型中表達,在真實芯片的約束條件下實現。可以添加新的字段,可以重新配置查找表,可以添加新的頭處理,所有這些都是通過軟件重新配置。雖然我們的芯片不能做正則表達式,或操縱包體,但用這種芯片構建的盒子可能會從周二的以太網芯片變成周三的防火墻,周四變成一個全新的設備,所有這些都是通過正確的軟件升級。今天的挑戰是在接近1萬億比特的容量下做到這一點。我們提出的芯片設計有驚人的規格:它包含7000個處理器數據通道,370 Mb的SRAM和40 Mb的TCAM,跨越32個處理階段。
就創意而言,我們將RMT模型作為一種強大的方式,將程序員所需的轉發行為映射到一個由靈活的解析器構建的流水線上,一個具有任意寬度和深度的存儲器的邏輯匹配階段的可配置安排,以及靈活的包編輯。這些抽象要求以太比特的速度高效地實現新的算法。我們使用的內存塊可以在階段內或跨階段組合,這是實現可重構匹配表的關鍵;我們對TCAM的大規模使用,大大提高了匹配的靈活性;最后,我們使用完全并行的VLIW指令是包編輯的關鍵。我們的設計表明,這種大大提高靈活性的額外成本不到15%的面積和功耗的芯片。最終,我們已經解決的實現挑戰對SIGCOMM用戶來說可能不是很明顯,那就是生產一個可以在芯片上有效連接的架構。
雖然OpenFlow規范暗示RMT和一些研究人員[17]已經積極地追求這個夢想,但RMT模型仍然是理論的,沒有存在的證據證明芯片設計工作在太比特的速度。本文提出了一個具體的RMT方案,并證明了其可行性。
顯然,我們有可能進一步采取行動,取消我們因為而施加的一些限制。但是現在這個討論可以開始了。
(正文完)

評論