基于HDFS的云存儲在高校信息資源整合中的應(yīng)用

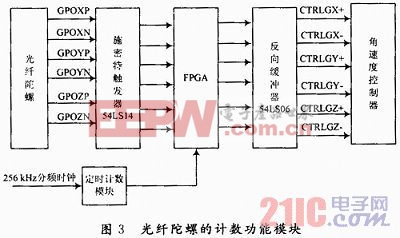
HDFS中數(shù)據(jù)的交互無外乎數(shù)據(jù)的讀和寫,重點設(shè)計的對象就是客戶端、名稱節(jié)點和數(shù)據(jù)節(jié)點。客戶端首先從名稱節(jié)點中讀取對應(yīng)的文件塊信息,再和數(shù)據(jù)節(jié)點建立連接并獲取數(shù)據(jù),圖2具體描述了數(shù)據(jù)讀取過程。本文引用地址:http://www.104case.com/article/202391.htm
HDFS的數(shù)據(jù)寫入過程比讀取過程細節(jié)上更為復(fù)雜一些,但是模型圖非常類似。除了數(shù)據(jù)的讀寫,維護數(shù)據(jù)的可用性和一致性也是系統(tǒng)最基本的要求和重要的功能。一般來說,系統(tǒng)通過數(shù)據(jù)復(fù)制、節(jié)點故障、數(shù)據(jù)校驗、垃圾回收機制來維護數(shù)據(jù)的可用性和一致性。
3 HDFS的云存儲應(yīng)用于整合高校信息資源
3.1 系統(tǒng)分析與設(shè)計
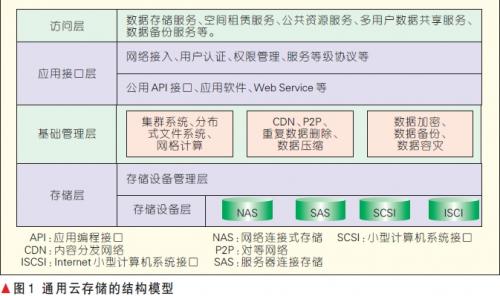
目前高校信息資源面臨著空前的海量數(shù)據(jù)管理難題,存儲數(shù)據(jù)的成本在不斷增加,而且信息的安全性也亟待提高。因此要借用云存儲這種新的工作模式來解決這個問題。根據(jù)高校的特殊情況,結(jié)合云存儲的優(yōu)點,要設(shè)計一個成功的云存儲案例,需要考慮這么幾個方面:
1)低成本海量存儲 將數(shù)據(jù)存儲在一般的個人電腦構(gòu)成的網(wǎng)絡(luò)中,并進行合理調(diào)配,構(gòu)成一個有機海量存儲設(shè)備。
2)高效率的訪問 數(shù)據(jù)盡可能的存儲在不同的數(shù)據(jù)節(jié)點中,當(dāng)客戶端對信息進行請求時,能高效的回復(fù),并做到并發(fā)。
3)安全性高 每個文件都會有多個副本分別存儲在多個數(shù)據(jù)節(jié)點上。如果某個數(shù)據(jù)節(jié)點出現(xiàn)問題,不會發(fā)生文件丟失的現(xiàn)象。
3.2 系統(tǒng)功能設(shè)計
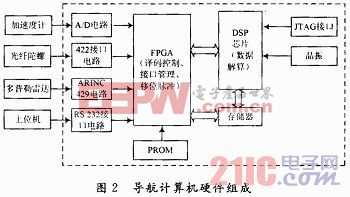
高校相對于云存儲系統(tǒng)是一個用戶,而高校內(nèi)部有多個部門,相對于云存儲系統(tǒng)的用戶高校來說是一個子用戶。云存儲系統(tǒng)能夠創(chuàng)建、管理、維護高校云存儲用戶;高校云用戶能夠創(chuàng)建、管理、維護各部門子用戶。而子用戶才是真正的終端信息存儲用戶,他們上傳、下載、刪除數(shù)據(jù)信息。由于我們的這個系統(tǒng)是基于HDFS的,而一個基本的HDFS由一個NameNode和n個DataNode組成,云存儲系統(tǒng)是由多個地方的HDFS存儲設(shè)備通過應(yīng)用軟件集合起來協(xié)同工作,完成外部訪問請求。可以將本文描述的分布式文件系統(tǒng)(DFS)抽象成一個三級模型,如圖3所示。
根據(jù)系統(tǒng)結(jié)構(gòu)圖可以清楚看到本文描述的分布式文件系統(tǒng)(DFS)的業(yè)務(wù)邏輯模型:終端網(wǎng)絡(luò)發(fā)出信息存取訪問請求,DFS通過封裝與HDFS通信協(xié)議的Client客戶端與基于HDFS的云存儲系統(tǒng)進行通信,完成對信息的訪問。HDFS存儲業(yè)務(wù)以云狀分布在網(wǎng)絡(luò)的各個部分,它具有容量大、性能高、可靠性好、協(xié)同優(yōu)良的特點,正是這些特點,完成了高校信息資源高效訪問與存儲。
4 結(jié)論
基于HDFS的云存儲是一種動態(tài)可調(diào)整、基于互聯(lián)網(wǎng)的存儲解決方案,用戶可以通過通用和易用協(xié)議和應(yīng)用程序接口通過網(wǎng)絡(luò)訪問存儲目標(biāo),這種新技術(shù)對最終用戶來說很有好處。云存儲可以讓用戶很容易增加存儲容量,而且不需要購買、安裝和管理任何存儲基礎(chǔ)設(shè)施,卻提供了一個完善的備份、容災(zāi)數(shù)據(jù)中心。云存儲的成本和易用性優(yōu)勢對高校具有很強的吸引力,發(fā)展和應(yīng)用前景廣闊。




評論