深度學習到底是啥,看完下文你就懂了

深度學習概述
本文引用地址:http://www.104case.com/article/201806/381187.htmo 受限玻爾茲曼機和深度信念網絡
o Dropout
o 處理不平衡的技巧
o SMOTE :合成少數過采樣技術
o 神經網絡中對成本敏感的學習
深度學習概述
在 2006 年之前,訓練深度監督前饋神經網絡總是失敗的,其主要原因都是導致過度擬合,即訓練錯誤減少,而驗證錯誤增加。
深度網絡通常意味著具有多于 1 個隱藏層的人工神經網絡。訓練深層隱藏層需要更多的計算能力,具有更深的深度似乎更好,因為直覺神經元可以使用下面圖層中的神經元完成的工作,從而導致數據的分布式表示。
Bengio 認為隱藏層中的神經元可被看作是其下面的層中的神經元所學到的特征檢測器( feature detector )。這個結果處于作為一個神經元子集的更好泛化( generalization )中,而這個神經元子集可從輸入空間中的特定區域的數據上進行學習。
而且,由于相同功能所需的計算單元越少,效率就越高,所以更深的架構可以更高效。分布式背后的核心思想是共享統計優勢,將不同架構的組件重用于不同的目的。
深度神經架構是由多個利用非線性操作的層組成的,例如在帶有許多隱藏層的神經網絡中。數據集中常常存在各種變化的因素,例如數據各自的性質經常可能獨立地變化。
深度學習算法可以獲取解釋數據中的統計變化,以及它們如何相互作用以生成我們觀察到的數據類型。較低層次的抽象更直接地與特定的觀察聯系在一起,另一方面,更高層次的更抽象,因為他們與感知數據的聯系更加偏遠。
深度架構學習的重點是自動發現從低級特征到更高級別概念的抽象。算法可以在不需要手動定義必要抽象的情況下啟用發現這些定義。
數據集中的訓練樣本的多樣性必須至少與測試集中的一樣多,否則算法就不能一概而論。深度學習方法旨在學習特征層次結構,將更低層次的特征組合成更高層次的抽象。
具有大量參數的深度神經網絡是非常強大的機器學習系統。但是,過度擬合在深度網絡中是一個嚴重的問題。過度擬合是指當驗證錯誤開始增加而訓練錯誤下降時。 Dropout 是解決這個問題的正則化技術之一,這將在后面討論。
今天,深度學習技術取得成功的最重要因素之一是計算能力的提高。圖形處理單元( GPU )和云計算對于將深度學習應用于許多問題至關重要。
云計算允許計算機集群和按需處理,通過并行訓練神經網絡來幫助減少計算時間。另一方面, GPU 是用于高性能數學計算的專用芯片,加速了矩陣的計算。
在 06-07 這一年,三篇論文徹底改變了深度學習的學科。他們工作中的關鍵原則是每層都可以通過無監督學習進行預先訓練,一次完成一層。最后,通過誤差反向傳播的監督訓練微調所有層,使得這種通過無監督學習進行的初始化比隨機初始化更好。
受限玻爾茲曼機和深度信念網絡
其中有一種無監督算法是受限玻爾茲曼機( RBM ),可用于預訓練深層信念網絡。 RBM 是波爾茲曼機的簡化版本,它的設計靈感來自于統計力學,它可以模擬給定數據集的基本分布的基于能量的概率,從中可以得出條件分布。
玻爾茲曼機是隨機處理可見單元和隱藏單元的雙向連接網絡。原始數據對應于 ' 可見 ' 神經元和樣本到觀察狀態,而特征檢測器對應 ' 隱藏 ' 神經元。在波爾茲曼機中,可見神經元為網絡和其運行環境提供輸入。訓練過程中,可見神經元被鉗制(設置成定義值,由訓練數據確定)。另一方面,隱藏的神經元可以自由操作。
然而,玻爾茲曼機因為其連通性而非常難以訓練。一個 RBM 限制了連通性從而使得學習變得簡單。在組成二分圖( bipartite graph )的單層中,隱藏單元沒有連接。它的優勢是隱藏單位可以獨立更新,并且與給定的可見狀態平行。
這些網絡由確定隱藏 / 可見狀態概率的能量函數控制。隱藏 / 可見單位的每個可能的連接結構( joint configurations )都有一個由權重和偏差決定的 Hopfield 能量。連接結構的能量由吉布斯采樣優化,它可通過最小化 RBM 的最低能量函數學習參數。
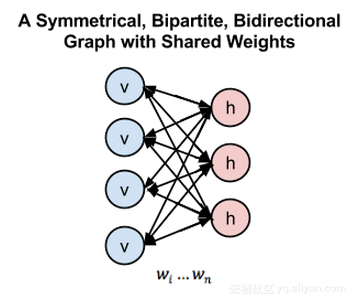
在上圖中,左層代表可見層,右層代表隱藏層
在深度信念網絡( DBN )中, RBM 由輸入數據進行訓練,輸入數據具有隱藏層中隨機神經元捕獲的輸入數據的重要特征。在第二層中,訓練特征的激活被視為輸入數據。第二個 RBM 層的學習過程可以看作是學習特征的特征 。 每次當一個新的層被添加到深度信念網絡中時,原始訓練數據的對數概率上的可變的更低的界限就會獲得提升。
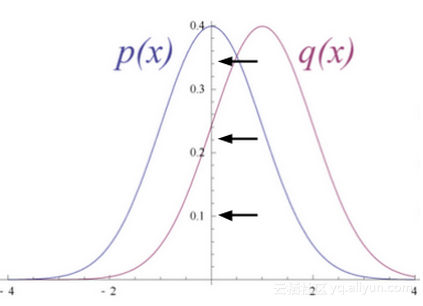
上圖顯示了 RBM 將其數據分布轉換為隱藏單元的后驗分布
隨機初始化 RBM 的權重,導致 p ( x )和 q ( x )的分布差異。學習期間,迭代調整權重以最小化 p ( x )和 q ( x )之間的誤差。 q ( x )是原始數據的近似值, p ( x )是原始數據。
調整來自神經元和另一神經元的突觸權重的規則不依賴于神經元是可見的還是隱藏的。由 RBM 層更新的參數被用作 DBN 中的初始化,通過反向傳播的監督訓練來微調所有層。
對于 KDD Cup 1999 的 IDS 數據,使用多模態( Bernoulli-Gaussian ) RBM 是不錯的選擇,因為 KDD Cup 1999 由混合數據類型組成,特別是連續和分類。在多模 RBM 中是使用兩個不同的通道輸入層,一個是用于連續特征的高斯輸入單元,另一個是使用二進制特征的伯努利輸入單元層。今天我們就不進行詳細講解。
Dropout
最近的發展是想深度網絡引入強大的正規化矩陣來減少過度擬合。在機器學習中,正則化是附加信息,通常是一種懲罰機制被引入,以懲罰導致過度擬合的模型的復雜性。
Dropout 是由 Hinton 引入的深度神經網絡的正則化技術,其包括通過在每一個訓練迭代上隨機關掉一部分神經元,而是在測試時間使用整個網絡(權重按比例縮小),從而防止特征檢測器的共適應。
Dropout 通過等同于訓練一個共享權重的指數模型減少過擬合。對于給定的訓練迭代,存在不同 dropout 配置的不同指數,所以幾乎可以肯定每次訓練出的模型都不一樣。在測試階段,使用了所有模型的平均值,作為強大的總體方法。
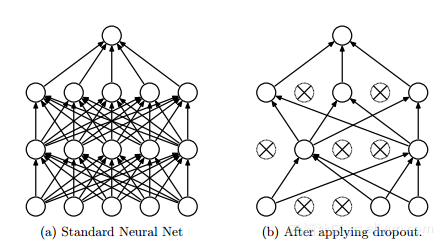
在上圖中, dropout 隨機舍棄神經網絡層之間的連接
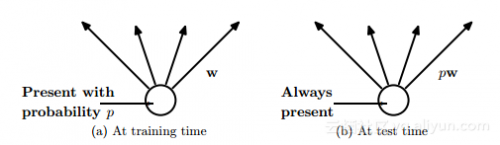
在上圖中,連接被丟棄的概率,同時在訓練時間中權重按比例縮小到 pw
在機器學習競賽中,平均很多模型通常是許多機器學習競賽獲勝者的關鍵,使用許多不同類型的模型,然后在測試時間將其結合起來進行預測。
隨機森林是一個非常強大的 bagging 算法,它是通過對許多決策樹進行平均而創建的,給它們提供了不同的訓練樣本集和替換。眾所周知,決策樹很容易適應數據并且在測試時間快速,因此通過給予不同的訓練集合來平均不同的單獨樹木是可以承受的。
然而,對深度神經網絡使用相同的方法,在計算上是非常昂貴。訓練單獨的深度神經網絡和訓練多個深度神經網絡計算成本已經很高了,然后平均似乎是不切實際的。此外,我們需要的是在測試有效的單個網絡,而不是有大量的大型神經網絡。
Dropout 是平均許多大型神經網絡的有效方法。每次訓練模型時,隱藏單元都可以省略。因此,在測試時我們應該使用權重減半的“平均網絡”模型。平均網絡等同于將 所有可能網絡預測的標簽上概率分布的幾何平均值與單個隱藏的單位層和 softmax 輸出層。
另一種看待 Dropout 的方法是,它能夠防止特征檢測器之間的共適應( co-adaption )。特征檢測器的共適應意味著如果隱藏單元知道存在哪些其他隱藏單元,則可以在訓練數據上與它們進行協調。但是,在測試數據集上,復合協調很可能無法一概而論。
Dropout 也可以以一種較低的概率在輸入層中使用,通常為 20 %的概率。這里的概念和降噪自動編碼器發展出的概念相同。在此方法中,一些輸入會被遺漏。這會對準確性造成傷害,但也能改善泛化能力,其方式類似于在訓練時將噪聲添加到數據集中。
在 2013 年出現了 Dropout 的一種變體,稱為 Drop connect 。它不再是以特定的概率權重舍棄隱藏單位,而是以一定的概率隨機舍棄。實驗結果已經表明,在 MNIST 數據集上 Drop connect 網絡比的 dropout 網絡表現的更好。
處理類別失衡的技巧
當一個類別(少數類)相比于其他類別(多數類)明顯代表性不足的時候就會產生類別失衡問題。這個難題有著現實意義,會對誤分類少數類造成極高的代價,比如檢測欺詐或入侵這樣的異常活動。這里有多種技術可以處理類別失衡難題,如下面解釋的這一種:
SMOTE :合成少數過采樣技術
解決類失衡問題的一種廣泛使用的方法是對數據集進行重采樣。抽樣方法涉及通過調整少數群體和多數群體的先驗分布來預處理和平衡訓練數據集。 SMOTE 是一種過抽樣的方法,其中通過創建“合成”示例而不是通過對替換進過行采樣來對少數類別進行過采樣。
已經有人提出說通過替換進行的少數類過采樣不能顯著改進結果,不如說它趨于過擬合少數類的分類。相反, SMOTE 算法在“特征空間”而不是“數據空間”中運行。它通過對少數類別進行過度抽樣來創建合成樣本,從而更好地推廣。
這個想法的靈感來自于通過對真實數據進行操作來創建額外的訓練數據,以便有更多數據有助于推廣預測。
在此算法中第一個最近鄰( neighbours )是為了少數類計算的。然后,就可以以下列方式計算少數類的合成特征:選擇最鄰近的一個隨機數字,然后使用這一數字與原始少數類數據點的距離。
該距離乘以 0 和 1 之間的隨機數,并將結果作為附加樣本添加到原始少數類數據的特征向量,從而創建合成的少數類樣本。
神經網絡中成本敏感的學習
成本敏感性學習似乎是解決分類問題的類不均衡問題的一種非常有效的方法。接下來我們描述特定于神經網絡的三種成本敏感的方法。
在測試未見過的示例時,將該類的先驗概率合并到神經網絡的輸出層中:
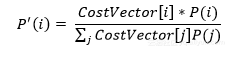
根據成本調整學習率。應將更高的學習率分配給具有高誤分類成本的樣本,從而對這些例子的權重變化產生更大的影響:
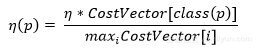
修改均方誤差函數。結果是,反向傳播進行的學習將最小化誤分類成本。新的誤差函數是:
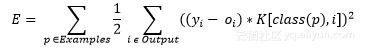
其成本因子是 K[i , j] 。
這個新的誤差函數產生一個新的增量規則,用于更新網絡的權重:

其中第一個方程表示輸出神經元的誤差函數,第二個方程表示隱層神經元的誤差函數。





評論