一步一步學用Tensorflow構建卷積神經網絡

0. 簡介
本文引用地址:http://www.104case.com/article/201711/371373.htm在過去,我寫的主要都是“傳統類”的機器學習文章,如樸素貝葉斯分類、邏輯回歸和Perceptron算法。在過去的一年中,我一直在研究深度學習技術,因此,我想和大家分享一下如何使用Tensorflow從頭開始構建和訓練卷積神經網絡。這樣,我們以后就可以將這個知識作為一個構建塊來創造有趣的深度學習應用程序了。
為此,你需要安裝Tensorflow(請參閱安裝說明),你還應該對Python編程和卷積神經網絡背后的理論有一個基本的了解。安裝完Tensorflow之后,你可以在不依賴GPU的情況下運行一個較小的神經網絡,但對于更深層次的神經網絡,就需要用到GPU的計算能力了。
在互聯網上有很多解釋卷積神經網絡工作原理方面的網站和課程,其中有一些還是很不錯的,圖文并茂、易于理解[點擊此處獲取更多信息]。我在這里就不再解釋相同的東西,所以在開始閱讀下文之前,請提前了解卷積神經網絡的工作原理。例如:
什么是卷積層,卷積層的過濾器是什么?
什么是激活層(ReLu層(應用最廣泛的)、S型激活或tanh)?
什么是池層(最大池/平均池),什么是dropout?
隨機梯度下降的工作原理是什么?
本文內容如下:
Tensorflow基礎
1.1 常數和變量
1.2 Tensorflow中的圖和會話
1.3 占位符和feed_dicts
Tensorflow中的神經網絡
2.1 介紹
2.2 數據加載
2.3 創建一個簡單的一層神經網絡
2.4 Tensorflow的多個方面
2.5 創建LeNet5卷積神經網絡
2.6 影響層輸出大小的參數
2.7 調整LeNet5架構
2.8 學習速率和優化器的影響
Tensorflow中的深度神經網絡
3.1 AlexNet
3.2 VGG Net-16
3.3 AlexNet性能
結語
1. Tensorflow 基礎
在這里,我將向以前從未使用過Tensorflow的人做一個簡單的介紹。如果你想要立即開始構建神經網絡,或者已經熟悉Tensorflow,可以直接跳到第2節。如果你想了解更多有關Tensorflow的信息,你還可以查看這個代碼庫,或者閱讀斯坦福大學CS20SI課程的講義1和講義2。
1.1 常量與變量
Tensorflow中最基本的單元是常量、變量和占位符。
tf.constant()和tf.Variable()之間的區別很清楚;一個常量有著恒定不變的值,一旦設置了它,它的值不能被改變。而變量的值可以在設置完成后改變,但變量的數據類型和形狀無法改變。
#We can create constants and variables of different types.
#However, the different types do not mix well together.
a = tf.constant(2, tf.int16)
b = tf.constant(4, tf.float32)
c = tf.constant(8, tf.float32)
d = tf.Variable(2, tf.int16)
e = tf.Variable(4, tf.float32)
f = tf.Variable(8, tf.float32)
#we can perform computations on variable of the same type: e + f
#but the following can not be done: d + e
#everything in Tensorflow is a tensor, these can have different dimensions:
#0D, 1D, 2D, 3D, 4D, or nD-tensors
g = tf.constant(np.zeros(shape=(2,2), dtype=np.float32)) #does work
h = tf.zeros([11], tf.int16)
i = tf.ones([2,2], tf.float32)
j = tf.zeros([1000,4,3], tf.float64)
k = tf.Variable(tf.zeros([2,2], tf.float32))
l = tf.Variable(tf.zeros([5,6,5], tf.float32))
除了tf.zeros()和tf.ones()能夠創建一個初始值為0或1的張量(見這里)之外,還有一個tf.random_normal()函數,它能夠創建一個包含多個隨機值的張量,這些隨機值是從正態分布中隨機抽取的(默認的分布均值為0.0,標準差為1.0)。
另外還有一個tf.truncated_normal()函數,它創建了一個包含從截斷的正態分布中隨機抽取的值的張量,其中下上限是標準偏差的兩倍。
有了這些知識,我們就可以創建用于神經網絡的權重矩陣和偏差向量了。
weights = tf.Variable(tf.truncated_normal([256 * 256, 10]))
biases = tf.Variable(tf.zeros([10]))
print(weights.get_shape().as_list())
print(biases.get_shape().as_list())
>>>[65536, 10]
>>>[10]
1.2 Tensorflow 中的圖與會話
在Tensorflow中,所有不同的變量以及對這些變量的操作都保存在圖(Graph)中。在構建了一個包含針對模型的所有計算步驟的圖之后,就可以在會話(Session)中運行這個圖了。會話可以跨CPU和GPU分配所有的計算。
graph = tf.Graph()
with graph.as_default():
a = tf.Variable(8, tf.float32)
b = tf.Variable(tf.zeros([2,2], tf.float32))
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
print(f)
print(session.run(f))
print(session.run(k))
>>>
>>> 8
>>> [[ 0. 0.]
>>> [ 0. 0.]]
1.3 占位符 與 feed_dicts
我們已經看到了用于創建常量和變量的各種形式。Tensorflow中也有占位符,它不需要初始值,僅用于分配必要的內存空間。 在一個會話中,這些占位符可以通過feed_dict填入(外部)數據。
以下是占位符的使用示例。
list_of_points1_ = [[1,2], [3,4], [5,6], [7,8]]
list_of_points2_ = [[15,16], [13,14], [11,12], [9,10]]
list_of_points1 = np.array([np.array(elem).reshape(1,2) for elem in list_of_points1_])
list_of_points2 = np.array([np.array(elem).reshape(1,2) for elem in list_of_points2_])
graph = tf.Graph()
with graph.as_default():
#we should use a tf.placeholder() to create a variable whose value you will fill in later (during session.run()).
#this can be done by 'feeding' the data into the placeholder.
#below we see an example of a method which uses two placeholder arrays of size [2,1] to calculate the eucledian distance
point1 = tf.placeholder(tf.float32, shape=(1, 2))
point2 = tf.placeholder(tf.float32, shape=(1, 2))
def calculate_eucledian_distance(point1, point2):
difference = tf.subtract(point1, point2)
power2 = tf.pow(difference, tf.constant(2.0, shape=(1,2)))
add = tf.reduce_sum(power2)
eucledian_distance = tf.sqrt(add)
return eucledian_distance
dist = calculate_eucledian_distance(point1, point2)
with tf.Session(graph=graph) as session:
tf.global_variables_initializer().run()
for ii in range(len(list_of_points1)):
point1_ = list_of_points1[ii]
point2_ = list_of_points2[ii]
feed_dict = {point1 : point1_, point2 : point2_}
distance = session.run([dist], feed_dict=feed_dict)
print("the distance between {} and {} -> {}".format(point1_, point2_, distance))
>>> the distance between [[1 2]] and [[15 16]] -> [19.79899]
>>> the distance between [[3 4]] and [[13 14]] -> [14.142136]
>>> the distance between [[5 6]] and [[11 12]] -> [8.485281]
>>> the distance between [[7 8]] and [[ 9 10]] -> [2.8284271]
2. Tensorflow 中的神經網絡
2.1 簡介
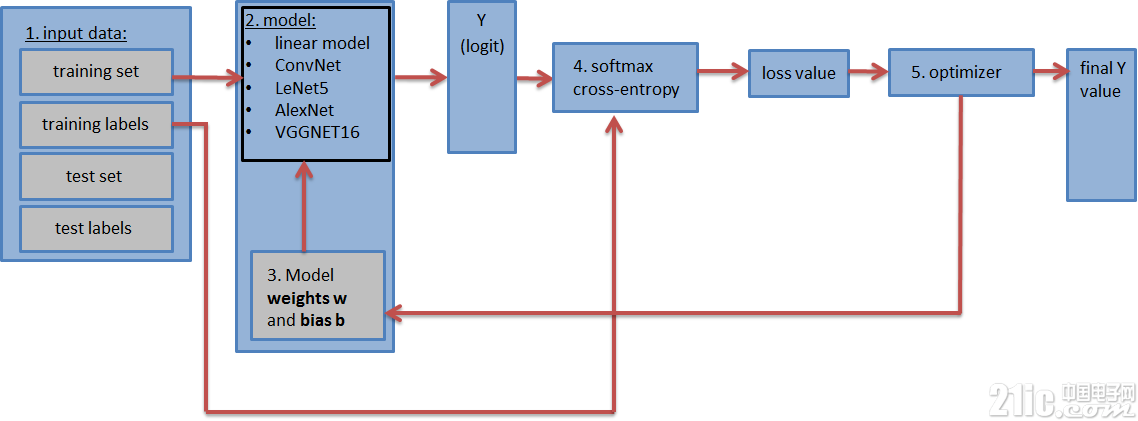
包含神經網絡的圖(如上圖所示)應包含以下步驟:
1. 輸入數據集:訓練數據集和標簽、測試數據集和標簽(以及驗證數據集和標簽)。 測試和驗證數據集可以放在tf.constant()中。而訓練數據集被放在tf.placeholder()中,這樣它可以在訓練期間分批輸入(隨機梯度下降)。
2. 神經網絡**模型**及其所有的層。這可以是一個簡單的完全連接的神經網絡,僅由一層組成,或者由5、9、16層組成的更復雜的神經網絡。
3. 權重矩陣和**偏差矢量**以適當的形狀進行定義和初始化。(每層一個權重矩陣和偏差矢量)
4. 損失值:模型可以輸出分對數矢量(估計的訓練標簽),并通過將分對數與實際標簽進行比較,計算出損失值(具有交叉熵函數的softmax)。損失值表示估計訓練標簽與實際訓練標簽的接近程度,并用于更新權重值。
5. 優化器:它用于將計算得到的損失值來更新反向傳播算法中的權重和偏差。
2.2 數據加載
下面我們來加載用于訓練和測試神經網絡的數據集。為此,我們要下載MNIST和CIFAR-10數據集。 MNIST數據集包含了6萬個手寫數字圖像,其中每個圖像大小為28 x 28 x 1(灰度)。 CIFAR-10數據集也包含了6萬個圖像(3個通道),大小為32 x 32 x 3,包含10個不同的物體(飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船、卡車)。 由于兩個數據集中都有10個不同的對象,所以這兩個數據集都包含10個標簽。

首先,我們來定義一些方便載入數據和格式化數據的方法。
def randomize(dataset, labels):
permutation = np.random.permutation(labels.shape[0])
shuffled_dataset = dataset[permutation, :, :]
shuffled_labels = labels[permutation]
return shuffled_dataset, shuffled_labels
def one_hot_encode(np_array):
return (np.arange(10) == np_array[:,None]).astype(np.float32)
def reformat_data(dataset, labels, image_width, image_height, image_depth):
np_dataset_ = np.array([np.array(image_data).reshape(image_width, image_height, image_depth) for image_data in dataset])
np_labels_ = one_hot_encode(np.array(labels, dtype=np.float32))
np_dataset, np_labels = randomize(np_dataset_, np_labels_)
return np_dataset, np_labels
def flatten_tf_array(array):
shape = array.get_shape().as_list()
return tf.reshape(array, [shape[0], shape[1] shape[2] shape[3]])
def accuracy(predictions, labels):
return (100.0 * np.sum(np.argmax(predictions, 1) == np.argmax(labels, 1)) / predictions.shape[0])
這些方法可用于對標簽進行獨熱碼編碼、將數據加載到隨機數組中、扁平化矩陣(因為完全連接的網絡需要一個扁平矩陣作為輸入):
在我們定義了這些必要的函數之后,我們就可以這樣加載MNIST和CIFAR-10數據集了:
mnist_folder = './data/mnist/'
mnist_image_width = 28
mnist_image_height = 28
mnist_image_depth = 1
mnist_num_labels = 10
mndata = MNIST(mnist_folder)
mnist_train_dataset_, mnist_train_labels_ = mndata.load_training()
mnist_test_dataset_, mnist_test_labels_ = mndata.load_testing()
mnist_train_dataset, mnist_train_labels = reformat_data(mnist_train_dataset_, mnist_train_labels_, mnist_image_size, mnist_image_size, mnist_image_depth)
mnist_test_dataset, mnist_test_labels = reformat_data(mnist_test_dataset_, mnist_test_labels_, mnist_image_size, mnist_image_size, mnist_image_depth)
print("There are {} images, each of size {}".format(len(mnist_train_dataset), len(mnist_train_dataset[0])))
print("Meaning each image has the size of 28281 = {}".format(mnist_image_sizemnist_image_size1))
print("The training set contains the following {} labels: {}".format(len(np.unique(mnist_train_labels_)), np.unique(mnist_train_labels_)))
print('Training set shape', mnist_train_dataset.shape, mnist_train_labels.shape)
print('Test set shape', mnist_test_dataset.shape, mnist_test_labels.shape)
train_dataset_mnist, train_labels_mnist = mnist_train_dataset, mnist_train_labels
test_dataset_mnist, test_labels_mnist = mnist_test_dataset, mnist_test_labels
######################################################################################
cifar10_folder = './data/cifar10/'
train_datasets = ['data_batch_1', 'data_batch_2', 'data_batch_3', 'data_batch_4', 'data_batch_5', ]
test_dataset = ['test_batch']
c10_image_height = 32
c10_image_width = 32
c10_image_depth = 3
c10_num_labels = 10
with open(cifar10_folder + test_dataset[0], 'rb') as f0:
c10_test_dict = pickle.load(f0, encoding='bytes')
c10_test_dataset, c10_test_labels = c10_test_dict[b'data'], c10_test_dict[b'labels']
test_dataset_cifar10, test_labels_cifar10 = reformat_data(c10_test_dataset, c10_test_labels, c10_image_size, c10_image_size, c10_image_depth)
c10_train_dataset, c10_train_labels = [], []
for train_dataset in train_datasets:
with open(cifar10_folder + train_dataset, 'rb') as f0:
c10_train_dict = pickle.load(f0, encoding='bytes')
c10_train_dataset_, c10_train_labels_ = c10_train_dict[b'data'], c10_train_dict[b'labels']
c10_train_dataset.append(c10_train_dataset_)
c10_train_labels += c10_train_labels_
c10_train_dataset = np.concatenate(c10_train_dataset, axis=0)
train_dataset_cifar10, train_labels_cifar10 = reformat_data(c10_train_dataset, c10_train_labels, c10_image_size, c10_image_size, c10_image_depth)
del c10_train_dataset
del c10_train_labels
print("The training set contains the following labels: {}".format(np.unique(c10_train_dict[b'labels'])))
print('Training set shape', train_dataset_cifar10.shape, train_labels_cifar10.shape)
print('Test set shape', test_dataset_cifar10.shape, test_labels_cifar10.shape)
你可以從Yann LeCun的網站下載MNIST數據集。下載并解壓縮之后,可以使用python-mnist 工具來加載數據。 CIFAR-10數據集可以從這里下載。






評論