編程語言的發展趨勢及未來方向(6):并發

這是Anders Hejlsberg(不用介紹這是誰了吧)在比利時TechDays 2010所做的開場演講。由于最近我在博客上關于語言的討論比較多,出于應景,也打算將Anders的演講完整地聽寫出來。在上一部分中,Anders談論了“元編程”及他正在努力的“編譯器即服務”功能。在這一部分中,Anders則談論了“并發”,這也是他眼中編程語言發展的三種趨勢之一,并演示了.NET 4.0中并行庫的神奇效果。
本文引用地址:http://www.104case.com/article/201704/346685.htm如果沒有特別說明,所有的文字都直接翻譯自Anders的演講,并使用我自己的口語習慣表達出來,對于Anders的口誤及反復等情況,必要時在譯文中自然也會進行忽略。為了方便理解,我也會將視頻中關鍵部分進行截圖,而某些代碼演示則會直接作為文章內容發表。
(聽寫開始,接上篇)

好,最后我想談的內容是“并發”。

聽說過摩爾定律的請舉手……幾乎是所有人。那么多少人聽說了摩爾定律已經結束了呢?嗯,還是有很多人。我有好消息,也有壞消息。我認為摩爾定律并沒有停止。摩爾定律說的是:可以在集成電路上低成本地放置晶體管的數目,約每兩年便會增加一倍。有趣的是,這個定律從60年代持續到現在,而從一些跡象上來看,這個定律會繼續保持20到30年。
摩爾定理有個推論,便是說時鐘速度將根據相同的周期提高,也就是說每隔大約24個月,CPU的速度便會加倍──而這點已經停止了。再來統計一下,你們之中有誰的機器里有20GHz的CPU?看到了沒?一個人都沒有。但如果你從五年前開始計算的話,現在我們應該已經在使用20GHz的CPU了,但事實并非如此。這點在五年前就停止了,而且事實上最大速度還有些下降,因為發熱量實在太大了,會消耗許多能源,讓電池用的太快。

有些物理方面的基礎因素讓CPU不能運行的太快。然而,另一意義上的摩爾定理出現了。我們還是可以看到容量的增加,因為可以在同一個表盤上放置多個CPU了。目前已經有了雙核、四核,Intel的CTO在三年前說,十年后我們可以出現80核的處理器。
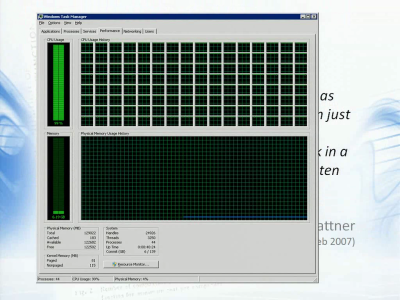
到了那個時候,你的任務管理器中就可能是這樣的。似乎有些嚇人,不過這是我們實驗室中真實存在的128核機器。你可以看到,計算能力已經完全用上了。這便是個問題,比如你在這臺強大的機器上進行一個實驗,你自然希望看到100%的使用狀況,不過傳統的實驗都是在一個核上執行的,所以我們面臨的挑戰是,我們需要換一種寫程序的方式來利用此類機器。
我的一個同事,Herb Sutter,他寫過一篇文章,談到“免費的午餐已經結束了”。沒錯,我們已經不能寫一個程序,然后對客戶說:啊,未來的硬件會讓它運行的越來越快,我們不用關心太多──不,已經不會這樣了,除非你換種不同的寫法。實話說,這是個挑戰,也是個機遇。說它是個挑戰,是因為并發十分困難,至今我們對此還沒有簡單的答案,稍后我會演示一些正有所改善的東西,但……這也是一個機遇,在這樣的機器上,你的確可以用完所有的核,這樣便能獲得性能提高,不過做法需要有所不同。
多核革命的一個有趣之處在于,它對于并發的思維方式會有所改變。傳統的并發思維是在單個CPU上執行多個邏輯任務,使用舊有的分時方式、時間片模型來執行多個任務。但是,你想一下便會發現如今的并發情況正好相反,現在是要將一個邏輯上的任務放在多個CPU上執行。這改變了我們編寫程序的方式,這意味著對于語言或是API來說,我們需要有辦法來分解任務,把它拆分成多個小任務后獨立的執行,而傳統的編程語言中并不關注這點。
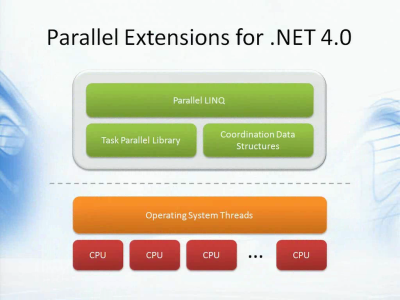
使用目前的并發API來完成工作并不容易,比如使用Thread,ThreadPool,lock,Monitor等等,你無法太好的進展。不過.NET 4.0提供了一些美妙的事物,我們稱之為.NET并行擴展。它是一種現代的并發模型,將邏輯上的任務并發與我們實際使用的的物理模型分離開來。以前我們的API都是直接處理線程,也就是(上圖)下方橙色的部分,不過有了.NET并行擴展之后,你可以使用更為邏輯化的編程風格。任務并行庫(Task Parallel Library),并行LINQ(Parallel LINQ)以及協調數據結構(Coordination Data Structures)讓你可以直接關注邏輯上的任務,而不必關心它們是如何運行的,或是使用了多少個線程和CPU等等。
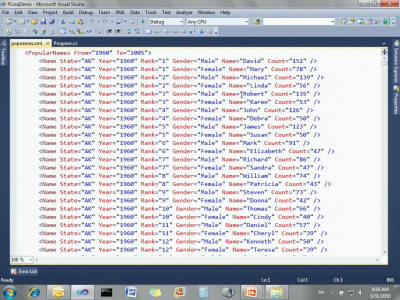
下面我來簡單演示一下它們的使用方式。我帶來了一個PLINQ演示,這里是一些代碼,讀取XML文件的內容。這有個50M大小的popname.xml文件,保存了美國社會安全數據庫里的信息,包含某個洲在某一年的人口統計信息。這個程序會讀取這個XML文件,把它轉化成一系列對象,并存放在一個List中。然后對其執行一個LINQ語句,查找所有在華盛頓名叫Robert的人,再根據年份進行排序:
Console.WriteLine("Loading XML data...");
var popNames =
(from e in XElement.Load("popnames.xml").Elements("Name")
select new
{
Name = (string)e.Attribute("Name"),
State = (string)e.Attribute("State"),
Year = (int)e.Attribute("Year"),
Count = (int)e.Attribute("Count")
})
.ToList();
Console.WriteLine(popNames.Count + " records");
Console.WriteLine();
string targetName = "Robert";
string targetState = "WA";
var querySequential =
from n in popNames
where n.Name == targetName && n.State == targetState
orderby n.Year
select n;
我們來執行一下……首先加載XML文件,然后進行查詢。利用PLINQ我們可以做到并行地查詢。我們只要拷貝一份代碼……改成queryParallel……現在我唯一要做的只是在數據源上使用AsParallel擴展方法,這樣便會引入一套新的類型和實現,此時相同的LINQ操作使用的便是并行的實現:
var queryParallel =
from n in popNames.AsParallel()
where n.Name == targetName && n.State == targetState
orderby n.Year
select n;
我們重新執行兩個查詢。
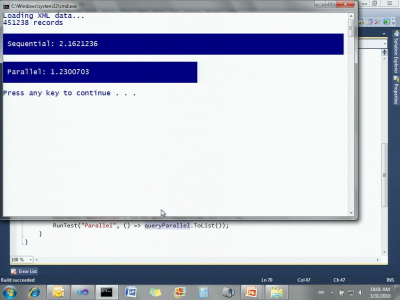
再次加載XML數據……并行實現使用了1.5秒,我們再試著運行一次,一般結果會更好一些,現在可能剛好在執行一些后臺任務。一般我們可以得到更快的結果……這次比較接近了。現在你可以觀察到,我們并不需要做太多事情,便可以在我的雙核機器上得到并發的效果。

這里我無法保證說,我們只要隨時加上AsParallel便可以得到兩倍的性能,有時可以有時不行,有些查詢能夠被并行,有的則不可以。然而,我想你一定同意一點,使用如LINQ這樣的DSL能夠方便我們編寫并行的代碼,也更有可能利用起并行效果。雖然不是每次都有效,但是嘗試的成本也很低。如果我們使用普通的for循環來編寫代碼,在某個地方使用線程池等等,便很容易在這些API里失去方向。而這里我們只要簡單地嘗試一下,便能知道是否可以提高性能了。
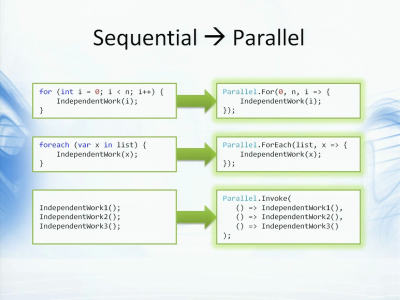
這里你已經看到我使用的LINQ查詢,而現在也有很多工作是通過循環來完成的。你可以想象主要的運算是從哪里來的,很自然會是在循環里操作數據。如果循環的每個迭代都是獨立的,便有很大的機會可以利用并發操作──我知道這里是“如果”,不過長期來看則一定會出現這樣的情況。這時候便可以使用并行擴展,或者說是.NET并行擴展里的新API,把循環轉化成并行的循環,只要簡單的改變……幾乎只要用同樣的循環體把for重構成Parallel.For就行了。如果你有foreach操作就可以使用Parallel.ForEach,或是一系列順序執行的語句也可以用上Parallel.Invoke。此時任務并行庫會接管并執行這些任務,根據你的CPU數量使用最優化的線程數量,你不需要關注更深的細節,只需要編寫邏輯就可以了。

就像我說的那樣,可能你會有獨立的任務但也可能沒有,所以很多時候我們需要編程語言來關注這方面的事情。比如“隔離性(Isolation)”。例如,編譯器如何發現這段代碼是獨立的,可以安全地并發執行,好比我創建了一個對象,在分享給其他人之前,我對它的改變是安全的。但是我一旦把它們共享出去了,那么它們便不安全了。所以如果我們的類型系統可以跟蹤到這樣的共享,如Linear Types──這在學術界也有一些研究。我們也可以在函數的純潔性(Purity)方面下功夫,如關注某個函數是否有副作用,有些時候編譯器可以做這方面的檢查,它可以禁止某些操作,以此保證我們寫出純函數。還有便是不可變性(Immutability),目前的C#或VB,我們需要額外的工作才能寫出不可變的代碼──但本不該這樣,我們應該在語言層面上更好的支持不可變性。這些都是在并發方面需要考慮的問題。
如果說有哪個語言特性超出這個范疇,我想說這里還有一個原則:你不該期望C#中出現某個特別的并發模型,而應該是一種通用的,可用于各種不同的并發場景的特性,就像隔離性、純潔性及不可變性那樣。語言擁有這樣的特性之后,就可以用于構建各種不同的API,各種并發方式都可以利用到核心的語言特性。
(未完待續)

評論