演示ASIC IP性能與質量需要有FPGA中立的設計流程

事實上,市面上的IP核都具有多樣化的功能和可選產品。并且,即便用戶已經查閱了有關潛在供應商和產品的目錄,但在IP質量上也仍然有很大的差別。將真正可靠且勝任的IP與有缺陷、未經過充分測試且缺乏真實性能的IP區分開來的訣竅,是參照活躍的成功用戶經驗。
本文引用地址:http://www.104case.com/article/201612/326345.htm嵌入式視覺是一個使用案例仍在開發的、且許多團隊在設計項目還未得到充分推進之前都不知道其真實需求的領域。當開始進行視覺處理時,CogniVue公司關注的不僅是有最高質量的IP可提供,而且還包括是否能夠確保滿足當前和未來對最廣泛應用的需求。這些應用包括能夠對周邊世界進行觀察并做出反應的小型智能攝像頭、能夠觀測并避免發生事故的汽車、裝在電視上能夠進行臉部和手勢識別的攝像頭,以及能夠對周圍世界進行觀察并給出增強視野的智能手機。要使這種嵌入式視覺技術的新天地成為可能,就需要有一種選擇和集成IP的新方法。
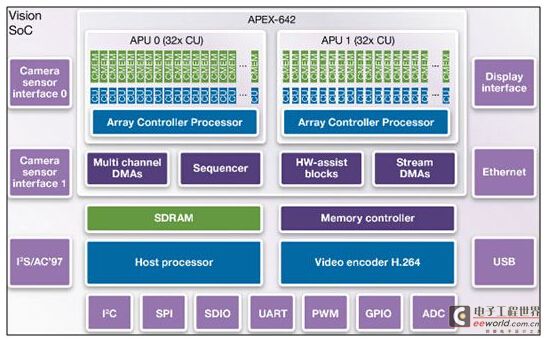
圖1:采用一個CogniVue APEX2-642內核的、支持視覺的SoC架構實例。
為了有效地實現嵌入式圖像的流水線處理和視覺處理算法,CogniVue設計了如圖1所示APEX圖像識別處理內核。圖像識別處理器(ICP)已經在量產之中,并且能夠用于包括汽車攝像頭(例如Zorg Industries公司為AudioVox公司提供的攝像頭)以及一些新型可穿戴式消費類產品(例如NeoLAB Convergence公司的Neo. 1智能簽字筆,如圖2所示)在內的許多應用。使用專為圖像處理所設計的處理器所帶來的優勢,是推動這些IP不斷地集成到這些消費類應用中的動力。例如,一個APEC這樣的內核與傳統的處理器架構相比,能夠在單位面積、單位功耗內為視覺處理提供好100倍的性能。對于NEO.1產品,它能夠在維持非常低功耗的同時,提供120fps速率的處理能力,使得這款電池供電的設備能夠在一次充電后持續工作數天。

圖2:CogniVue APEC內核為NeoLABCovergence公司的NEO.1智能簽字筆提供了強大的處理能力。
要實現這種性能,需要了解有關圖像處理需求的基本知識,并采用一種面向客戶產業領域需求的詳盡的測試和演示方法。任何內核在交付之前,都需要進行廣泛的認證,尤其是在諸如汽車等需要符合行業安全標準(如ISO 26262 "Road vehicles – Functional safety")的市場中。
評估IP
雖然這些需求要求進行測試,但對于IP公司還有附加的動力來提供驗證和評估平臺——這些平臺不僅能夠顯示出功能性和符合性,還能夠在不同的等級上執行,以能夠凸顯其對潛在客戶的真實價值。
作為這種動力的一個案例,如果為目前已知的有限且特定的應用創建能夠很好執行的視覺IP并不那么困難,這是事實。而我們是要從頭開始構建視覺有效性和靈活性的技術,重點是怎樣才能確保IP能在多種應用中都以最高的水平執行。并且我們知道多說無用,如果沒有真實世界“可觀測(eyes-on)”的演示來證明IP的質量和性能,IP的質量及應用適應性可能并不那么顯而易見。
對于那些希望對其合作伙伴或客戶實現授權的無晶圓廠IP供應商,其挑戰是演示在真實世界中運行的真實的IP應用。慶幸的是,FPGA平臺與技術世界的其它部分攜手實現了不斷的飛躍發展,為這種演示活動提供了一種工具。換言之,FPGA能夠提供必要的容量和性能來演示:如果IP在下一代定制ASIC中被選用,將會實現何種可能。盡管如此,我們似乎總是處在最前沿,推動著FPGA的容量和性能極限不斷前進,并且總是期望達到更多。
FPGA供應商正變得非常擅長軟件工具開發,但這些工具將IP的使用和個別FPGA公司緊密聯系在一起。現今基于某家FPGA供應商平臺上的演示,應該要準備好能夠遷移到日后完全不同的FPGA供應商平臺上,并能很好地工作。這能夠通過內部團隊或終端客戶推動,并且可能是因為收到包括偏好/熟悉度、傳統的基礎設施(硬軟件組件),以及有時能夠提供更快、更少成本、更佳尺寸的新平臺等各種因素的組合的推動。此外,公共的RTL代碼庫必須同時工作在最終的ASIC設計流程和FPGA “IP演示”設計流程中,如圖3所示。
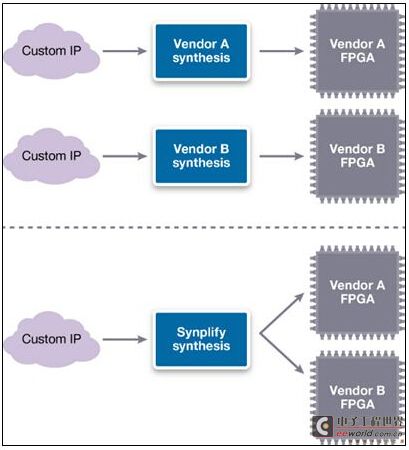
圖3:IP需要在來自多家供應商的多種ASIC和FPGA原型演示平臺上實現。
該工作模型的一個絕佳實例是,CogniVue為實現復雜的IP開發與演示,充分利用Synopsys Synplify工具以及相伴的Synopsys DesignWare IP。Synplify為我們用于交付IP的硅器件提供了卓越的映射能力和邏輯性能。對于初入行的FPGA開發人員來說,這有些違反直覺:確實,供應商應當知道如何最好地將邏輯功能映射到其產品之中。供應商工具正變得非常擅長于為基本開發人員提供他們可能需要的任何東西。在許多案例中,他們如果能夠提供最優結果,并不會讓我們感到吃驚;但實際上,在一片FPGA中實現一款RTL設計的最初階段是包括時序和面積優化的邏輯綜合。在我們的案例中,我們已經找到Synopsys來幫助解決硬件實現的基本綜合問題,它獨立于最終的技術映射(無論是FPGA還是ASIC芯片)。
結果證明
對我們來說,與他們在克服這個挑戰中所采用方法的價值相關的證明可以在一個事實中找到,即我們常規地致力于代碼庫,它們總是在推展著可以提供的FPGA器件的極限,而這在僅使用FPGA供應商的工具時并不適合。在這些案例中,在綜合之后甚至無需進行布局布線嘗試。利用Synplify,通常憑借在目標FPGA器件中減少所需的綜合后占位面積和相應的空間,使這些處在邊界線的設計得以實現。表1揭示了在一項近期設計中獲得的資源利用率數據,它將使用供應商提供的綜合和布局布線工具進行的設計,與在相同設計上使用Synplify進行綜合、并接著采用供應商工具進行布局布線所獲得的資源利用率結果進行了對比。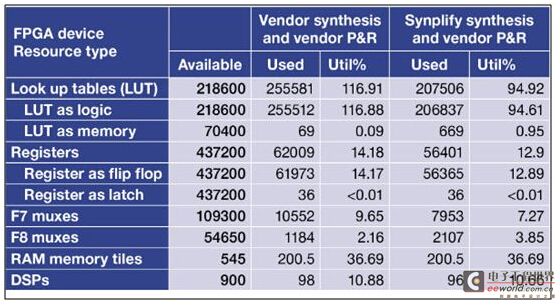
表1:僅用供應商工具與同時利用Synplify和供應商工具的結果對比。
表1中的一個關鍵指標是,基于供應商工具綜合的設計的利用率為116.91%,不適合該平臺上可提供的FPGA器件。這是我們的IP和我們需要持續將設計映射到FPGA上的一個真實案例。從系統和軟件開發的角度來看,我們能夠重新利用這些FPGA平臺是至關重要。
我們也可以為設計創建一個FPGA變體來減少功能并實現契合,但這將與理想情況相距甚遠,因為在FPGA中所驗證的RTL設計與為集成到ASIC SoC項目中而交付的RTL設計兩者之間存在差異。
許多老練的FPGA用戶可能會評論說,即便在使用Synplify綜合后,在利用率為94.92%的情況下也非常危險,因為在FPGA設計中即便是有較小改動(例如增加幾個邏輯門),也可能對總體面積和可實現的時鐘速率產生很大影響。然而,我們的經驗顯示出這個結果已經能夠很可靠地予以實現了,并且實現的時鐘速率處在我們期望值范圍的上端。這當然是提升供應商實現工具質量的一項有力證明。
然后將它們放在一起,該工作模型的結果將為自己來代言。從Synplify到供應商布局布線的流程也工作良好,它不僅提供了更好的結果,還以更少的總運行時間實現了這些結果。由于FPGA供應商的工具在綜合階段有時比Synplify實現相同階段要快,所以這個優勢并不總是立竿見影。然而我們不斷看到,在僅采用供應商工具進行綜合之后的實現階段,比用經Synplify優化的網表來完成實現所花的時間要長得多。
由于在僅有供應商工具的環境中上述案例不可能實現,因而該案例不具有代表性。相反,讓我們來看另一個常見(大得多的)的案例,CogniVue用這個案例來演示其IP的能力和可擴展性,這個CogniVue IP相當于約2.6M個NAND2 ASIC門。采用Synplify流程來構建該配置及其相關的系統組件(處理器、存儲器和互連等),花費了大約4小時20分鐘;而僅用供應商工具來實現相同的架構,據我們觀察需要大約5個小時45分鐘。在時間上長了33%,而得到的結果優化較差。
重定時序和流水線處理
Synplify綜合的時間開銷會更多的部分原因是,為提升性能,它在后臺能提供強大的QOR能力。我們通常用Synplify的兩個功能來是顯示我們的FPGA平臺獲得最佳的性能,這兩個功能是re-timing和pipelining.
Retiming是對時序元件(例如FLOPS)進行重分配,以更好地平衡邏輯電平和/或它們之間布線距離的過程。在這種方法中,它能夠通過縮短可能會降低可實現性能的長路徑、并延長會有未使用額外裕量的較短路徑,從而改善總體時序。所有這些都沒有任何RTL改變,并且從設計的主要輸入輸出來觀測,設計的行為沒有任何改變;時序原件的延遲總數維持在相同水平,并且功能操作沒有改變。
Pipelining是一個相關過程,它把復雜功能(例如乘法)分解成若干階段,以至于輸入級能夠在每個周期都接受新的輸入,同時輸出級和中間級持續處理之前的輸入。通過這種分級,時鐘速率和吞吐率能夠在不對延遲產生任何重要影響的情況下得以增加。按照Synplify應用到乘法等計算上的綜合功能,這意味著FLOPS布置在乘法操作之前和/或之后,能被識別和標記為流水線候選,因此能通過工具自動地轉移到乘法器中。這與上面描述的retiming功能實現了類似種類的時序平衡,并能夠得到更高的時鐘速率和復雜RTL功能的優化效率。
當你考慮選用這些QoR功能來自動分析和改善給定設計時,你可以看到它們能夠幫助工程師真正實現更快、更好的設計工作。同樣,高級語言如Verilog和VHDL(廢除集成電路設計的原理圖捕獲)的邏輯實現,已經基本依賴綜合工具,綜合工具的這種功能,至少根據我們的涉及到Synopsys的案例的情況,它們可以可靠的從復雜的時序元件和組合邏輯汪洋大海中尋找到最優的時序配置。這意味著,使用諸如Synplify等工具的工程師能夠以一種自然、明晰的方式捕獲他們的設計,然后依賴軟件工具進行優化,否則就會搞亂和混淆他們的代碼。
這些優化確實能夠幫助我們改善測試平臺可實現的時鐘速率,并且在這個案例中,它們獲得了進一步的幫助,Synplify極大地降低了我們的邏輯占位面積(如表1所示)。使用較少的邏輯(較少的FPGA資源)意味著相應較短的路徑,這通常能使可實現的時鐘速率變高并使時序收斂所花費的時間/努力變小。單看這幾點,這種方法由于其能夠使我們針對自己的演示平臺實現最佳的映射和性能而成為最佳之選。我們能夠針對多家供應商采用相同的綜合操作來實現,從而直接鎖定了生意。
系統環境
獨立于供應商的綜合只是等式的一部分。CogniVue IP追求的是在系統環境(或者SoC)中對最多樣化的應用提供最佳的視覺處理性能。并且這意味著,我們需要有附加的IP(例如主處理器接口、DDR RAM控制器和互連等)來構建一個有用的演示平臺。FPGA供應商在該領域也有很多IP可以提供,同時為了獲得最優實現也必須用到他們的一些組件。例如,由于存在著諸如I/O速度和內部布線的物理接口考慮因素,高速DDR RAM控制器最好是從那些供應商已經匹配到其器件的IP中進行挑選。
在我們的案例中,我們選擇使用了Synopsys的DesignWare IP——不僅是基于面積和時鐘速率的考慮,還考慮到了接口效率以及靈活性等其他至關重要的條件。在選擇IP時,將所有這些標準牢記于心非常重要。
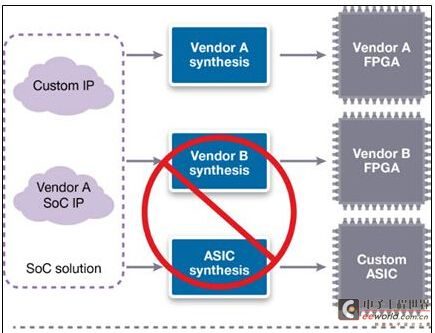
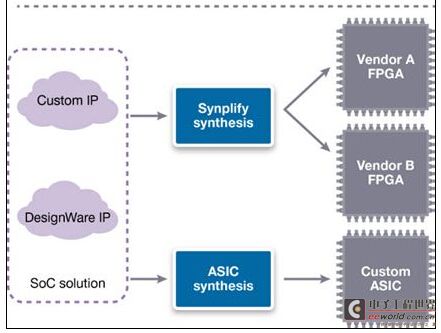
圖4:在ASIC和FPGA兩種原型演示平臺中,Synopsys AMBA DesignWare IP與CogniVue Vision IP子系統一起工作。
如圖4中的案例所示,現今最常見的一個SoC互連IP是ARM公司提供的AMBA AXI。FPGA供應商意識到此點,并通常為提供可能需要的所有AXI組件以拼接在一起成為IP陣列。但是為AMBA選擇Synopsys DesignWare IP解決方案的決定,是基于我們以一種供應商獨立、且不僅能應用到FPGA還能應用到可能最終實現的ASIC中的方式,來尋找業界領先的靈活性、效率、面積和速率。因為基于不僅限于功耗和面積的、而是更廣泛的標準來選擇IP,我們尋求的是超越我們自己的領域來演示可交互性,并為客戶加大我們能提供的指導。
總而言之,無論你的IP產品質量有多好,如果圍繞它、驅動它和支持它的邏輯未能理想地搭配,那么質量也會缺失。你能為構建一個最優的、高性能演示平臺提供什么,就意味著將凸顯其什么價值,并說服客戶不斷向你尋求更多。我們在視覺處理領域有著悠久的歷史,并且我們一路走來所學到的知識形成了產品的堅實基礎,其不僅是能在單位面積、單位功耗內提供一流的性能,而且能在本質上滿足現今和將來對靈活性和可應用性的需求。同時擁有能使用任何供應商的FPGA且面向ASIC能自動提供IP核的綜合工具和IP,以及能實現最佳的QoR和運行時間,是我們設計獲得成功的重要因素。

評論