基于語音識別的微博簽到系統

近年來,語音識別在語音導航,室內設備控制,人際對話等方面得到了廣泛的應用。
本文引用地址:http://www.104case.com/article/201611/322041.htm我們在今年第1期雜志《為設備添加社交網絡功能》中,實現了W5500EVB自己發微博功能。試想如果我們把語音識別與微博簽到結合起來,我們上班時,報上姓名,經識別后,攝像頭為我們拍張照片,傳到新浪微博,這樣既能得到我們簽到的時間,又能保證是本人簽到,可靠高效,同時朋友通過微博能了解到我們上班時的狀態,這樣是不是很有意思呢?
今天要介紹的就是上面提到的,基于語音識別的微博簽到系統,我們用攝像頭ov2640拍照,LD3320做語音識別,然后W5500EVB把我們想說的話,以及照片發送到新浪微博。
基于語音識別的微博簽到系統設計
(1)
a)
b)
c)
(2)
(3)
(4)
(5)
a)
b)
c)
d)
圖1是系統實物圖。

圖1系統實物圖
首先,我們了解一下整個程序流程,流程圖由一個主流程圖(見圖2)和四個子流程圖(圖3,圖4,圖5,圖6)組成。在STM32及ov2640初始化完成之后,將進行網絡參數配置,根據自己網絡的情況配置W5500的IP地址等網絡參數,確保W5500能連接外網。然后配置LD3320語音模塊,語音模塊處于初始狀態,將進行寫入識別列表,啟動語音識別過程,當我們對著麥克風說話的時候,LD3320檢測到有語音輸入,LD3320將進入中斷,在中斷中將把我們說的內容與寄存器里的詞條比較,如果找到1-4個候選答案,返回“找到識別結果”狀態,如果沒有找到候選答案,返回“未找到識別結果”狀態。在下一次循環中,LD3320如果是“找到識別結果”狀態,將拍攝照片及發送微博,如果是“未找到識別結果”狀態,將進入初始狀態,如果是“正在識別”或者“識別錯誤”將重新檢查LD3320的狀態。各個子流程圖描述的比較詳盡,這里不再一一贅述。對于拍攝照片子流程圖,我們需要了解jpg圖片的數據格式,圖片的前兩個字節是0xff,0xd8,最后兩個字節是0xff,0xd9,在中斷程序接收圖片數據的過程中,首先判斷數據是不是前兩個字節,如果是,保存數據,后面的數據是先保存,然后判斷是不是數據結尾,直到接收成功。
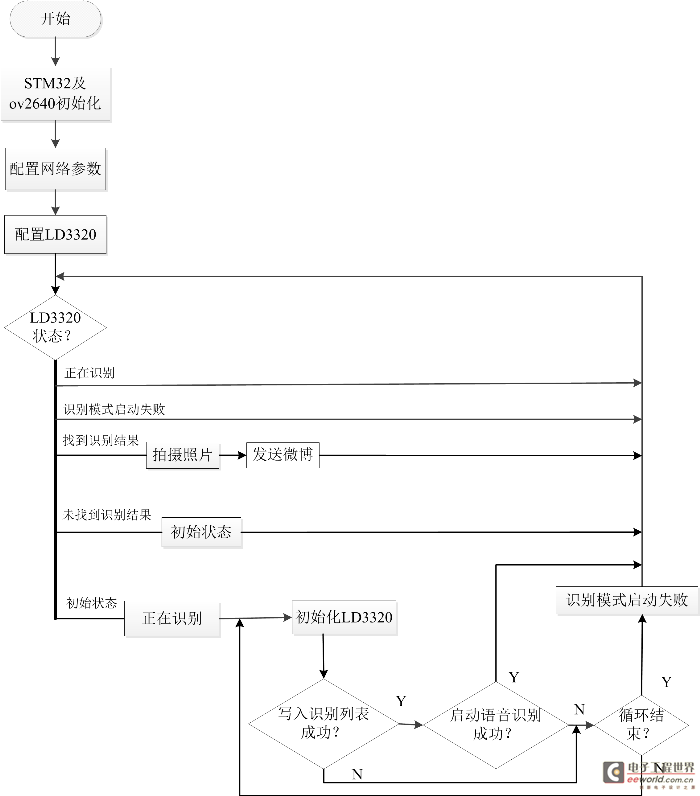
圖2系統主流程圖
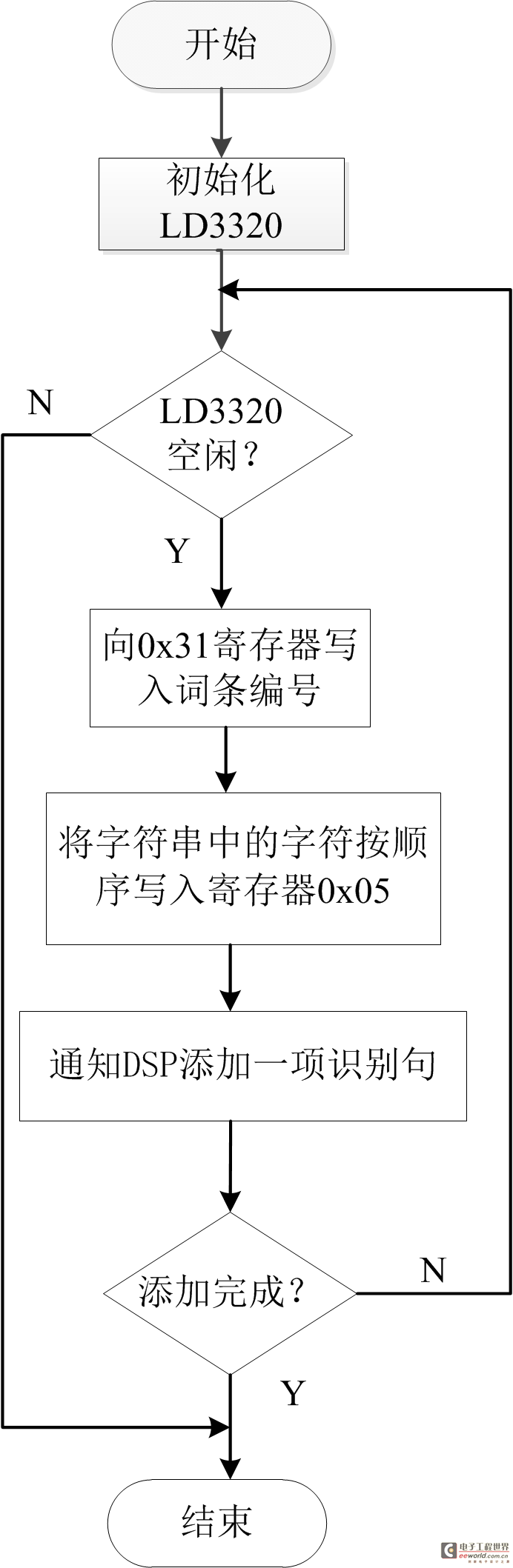
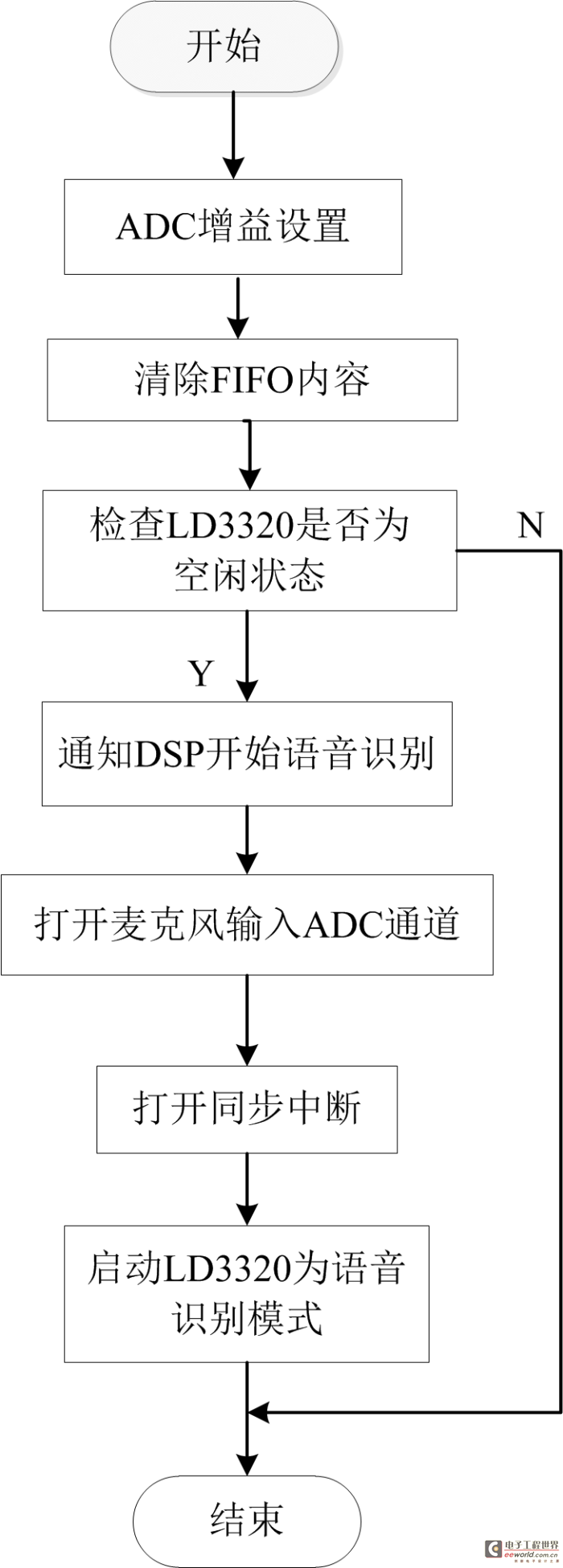
圖3寫入識別列表函數流程圖
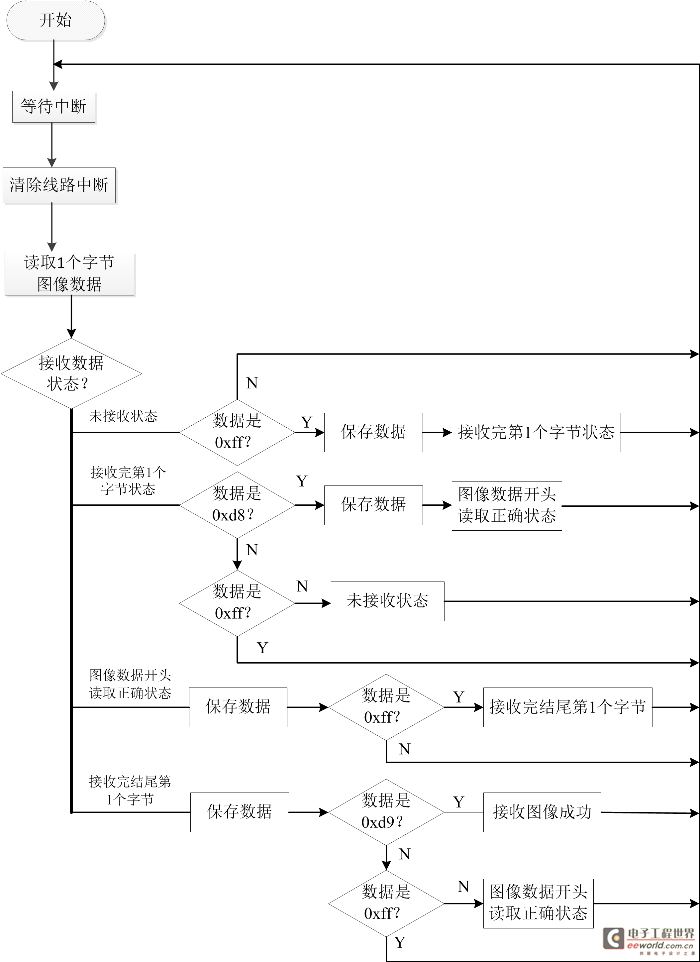
圖5拍攝照片流程圖
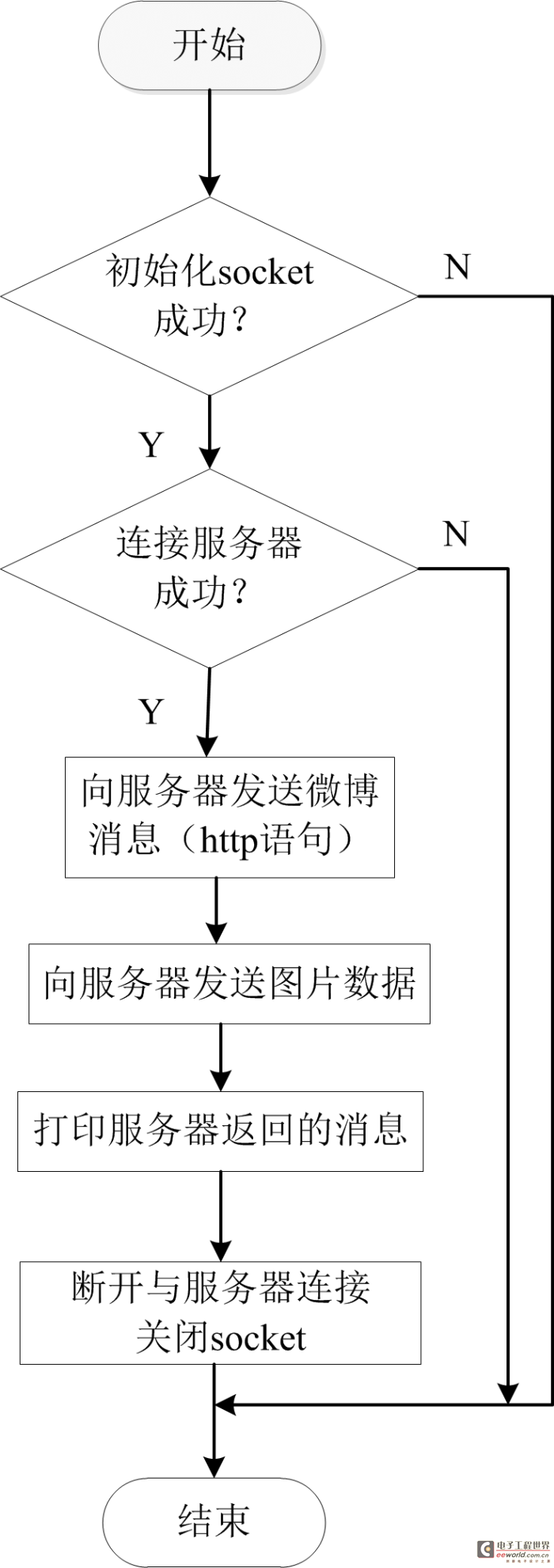
圖6發送微博流程圖
以上四個子流程圖,已清晰地給大家展示語音識別微博簽到系統的整個工作流程,那么接下來就為大家揭開詳細的制作過程。

評論