s3c2410 CACHES, WRITE BUFFER

以下內容轉載自中計報
Cache的工作原理
Cache的工作原理是基于程序訪問的局部性。
對大量典型程序運行情況的分析結果表明,在一個較短的時間間隔內,由程序產生的地址往往集中在存儲器邏輯地址空間的很小范圍內。指令地址的分布本來就是連續的,再加上循環程序段和子程序段要重復執行多次。因此,對這些地址的訪問就自然地具有時間上集中分布的傾向。
數據分布的這種集中傾向不如指令明顯,但對數組的存儲和訪問以及工作單元的選擇都可以使存儲器地址相對集中。這種對局部范圍的存儲器地址頻繁訪問,而對此范圍以外的地址則訪問甚少的現象,就稱為程序訪問的局部性。
根據程序的局部性原理,可以在主存和CPU通用寄存器之間設置一個高速的容量相對較小的存儲器,把正在執行的指令地址附近的一部分指令或數據從主存調入這個存儲器,供CPU在一段時間內使用。這對提高程序的運行速度有很大的作用。這個介于主存和CPU之間的高速小容量存儲器稱作高速緩沖存儲器(Cache)。
系統正是依據此原理,不斷地將與當前指令集相關聯的一個不太大的后繼指令集從內存讀到Cache,然后再與CPU高速傳送,從而達到速度匹配。
CPU對存儲器進行數據請求時,通常先訪問Cache。由于局部性原理不能保證所請求的數據百分之百地在Cache中,這里便存在一個命中率。即CPU在任一時刻從Cache中可靠獲取數據的幾率。
命中率越高,正確獲取數據的可靠性就越大。一般來說,Cache的存儲容量比主存的容量小得多,但不能太小,太小會使命中率太低;也沒有必要過大,過大不僅會增加成本,而且當容量超過一定值后,命中率隨容量的增加將不會有明顯地增長。
只要Cache的空間與主存空間在一定范圍內保持適當比例的映射關系,Cache的命中率還是相當高的。
一般規定Cache與內存的空間比為4:1000,即128kB Cache可映射32MB內存;256kB Cache可映射64MB內存。在這種情況下,命中率都在90%以上。至于沒有命中的數據,CPU只好直接從內存獲取。獲取的同時,也把它拷進Cache,以備下次訪問。
Cache的基本結構
Cache通常由相聯存儲器實現。相聯存儲器的每一個存儲塊都具有額外的存儲信息,稱為標簽(Tag)。當訪問相聯存儲器時,將地址和每一個標簽同時進行比較,從而對標簽相同的存儲塊進行訪問。Cache的3種基本結構如下:
全相聯Cache
在全相聯Cache中,存儲的塊與塊之間,以及存儲順序或保存的存儲器地址之間沒有直接的關系。程序可以訪問很多的子程序、堆棧和段,而它們是位于主存儲器的不同部位上。
因此,Cache保存著很多互不相關的數據塊,Cache必須對每個塊和塊自身的地址加以存儲。當請求數據時,Cache控制器要把請求地址同所有地址加以比較,進行確認。
這種Cache結構的主要優點是,它能夠在給定的時間內去存儲主存器中的不同的塊,命中率高;缺點是每一次請求數據同Cache中的地址進行比較需要相當的時間,速度較慢。
直接映像Cache
直接映像Cache不同于全相聯Cache,地址僅需比較一次。
在直接映像Cache中,由于每個主存儲器的塊在Cache中僅存在一個位置,因而把地址的比較次數減少為一次。其做法是,為Cache中的每個塊位置分配一個索引字段,用Tag字段區分存放在Cache位置上的不同的塊。
單路直接映像把主存儲器分成若干頁,主存儲器的每一頁與Cache存儲器的大小相同,匹配的主存儲器的偏移量可以直接映像為Cache偏移量。Cache的Tag存儲器(偏移量)保存著主存儲器的頁地址(頁號)。
以上可以看出,直接映像Cache優于全相聯Cache,能進行快速查找,其缺點是當主存儲器的組之間做頻繁調用時,Cache控制器必須做多次轉換。
組相聯Cache
組相聯Cache是介于全相聯Cache和直接映像Cache之間的一種結構。這種類型的Cache使用了幾組直接映像的塊,對于某一個給定的索引號,可以允許有幾個塊位置,因而可以增加命中率和系統效率。
Cache與DRAM存取的一致性
在CPU與主存之間增加了Cache之后,便存在數據在CPU和Cache及主存之間如何存取的問題。讀寫各有2種方式。
貫穿讀出式(Look Through)
該方式將Cache隔在CPU與主存之間,CPU對主存的所有數據請求都首先送到Cache,由Cache自行在自身查找。如果命中,則切斷CPU對主存的請求,并將數據送出;不命中,則將數據請求傳給主存。
該方法的優點是降低了CPU對主存的請求次數,缺點是延遲了CPU對主存的訪問時間。
旁路讀出式(Look Aside)
在這種方式中,CPU發出數據請求時,并不是單通道地穿過Cache,而是向Cache和主存同時發出請求。由于Cache速度更快,如果命中,則Cache在將數據回送給CPU的同時,還來得及中斷CPU對主存的請求;不命中,則Cache不做任何動作,由CPU直接訪問主存。
它的優點是沒有時間延遲,缺點是每次CPU對主存的訪問都存在,這樣,就占用了一部分總線時間。
寫穿式(Write Through)
任一從CPU發出的寫信號送到Cache的同時,也寫入主存,以保證主存的數據能同步地更新。
它的優點是操作簡單,但由于主存的慢速,降低了系統的寫速度并占用了總線的時間。
回寫式(Copy Back)
為了克服貫穿式中每次數據寫入時都要訪問主存,從而導致系統寫速度降低并占用總線時間的弊病,盡量減少對主存的訪問次數,又有了回寫式。
它是這樣工作的:數據一般只寫到Cache,這樣有可能出現Cache中的數據得到更新而主存中的數據不變(數據陳舊)的情況。但此時可在Cache 中設一標志地址及數據陳舊的信息,只有當Cache中的數據被再次更改時,才將原更新的數據寫入主存相應的單元中,然后再接受再次更新的數據。這樣保證了Cache和主存中的數據不致產生沖突。
…
…..
你可以通過http://www.chinaunix.net/jh/45/180390.html閱讀完全文
s3c2410 內置了指令緩存(ICaches),數據緩存(DCaches),寫緩存(write buffer) , 物理地址標志讀寫區 (Physical Address TAG RAM),CPU將通過它們來提高內存訪問效率。
我們先討論指令緩存(ICaches)。
ICaches使用的是虛擬地址,它的大小是16KB,它被分成512行(entry),每行8個字(8 words,32Bits)。
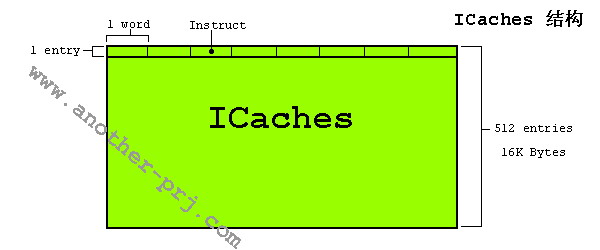
當系統上電或重起(Reset)的時候,ICaches功能是被關閉的,我們必須往lcr bit置1去開啟它,lcr bit在CP15協處理器中控制寄存器1的第12位(關閉ICaches功能則是往該位置0)。ICaches功能一般是在MMU開啟之后被使用的(為了降低MMU查表帶來的開銷),但有一點需要注意,并不是說MMU被開啟了ICaches才會被開啟,正如本段剛開始講的,ICaches的開啟與關閉是由lcr bit所決定的,無論MMU是否被開啟,只要lcr bit被置1了,ICaches就會發揮它的作用。
大家是否還記得discriptor(描述符)中有一個C bit我們稱之為Ctt,它是指明該描述符描述的內存區域內的內容(可以是指令也可以是數據)是否可以被Cache,若Ctt=1,則允許Cache,否則不允許被Cache。于是CPU讀取指令出現了下面這些情況:
1.如果CPU從Caches中讀取到所要的一條指令(cache hit)且這條指令所在的內存區域是Cacheble的(該區域
所屬描述符中Ctt=1),則CPU執行這條指令并從Caches中返回(不需要從內存中讀取)。
2.若CPU從Caches中讀取不到所要的指令(cache miss)而這條指令所在的內存區域是Cacheble的(同第1點),則CPU將從內存中
讀取這條指令,同時,一個稱為“8-word linefill”的動作將發生,這個動作是把該指令所處區域的8個word寫進
ICaches的某個entry中,這個entry必須是沒有被鎖定的(對鎖定這個操作感興趣的朋友可以找相關的資料進行了解)
3.若CPU從Caches中讀取不到所要的指令(cache miss)而這條指令所在的內存區域是UnCacheble的(該區域所屬描
述符中Ctt=0),則CPU將從內存讀取這條指令并執行后返回(不發生linefill)
通過以上的說明,我們可以了解到CPU是怎么通過ICaches執行指令的。你可能會有這個疑問,ICaches總共只有512個條目(entry),當512個條目都被填充完之后,CPU要把新讀取近來的指令放到哪個條目上呢?答案是CPU會把新讀取近來的8個word從512個條目中選擇一個對其進行寫入,那CPU是怎么選出一個條目來的呢?這就關系到ICaches的替換法則(replacemnet algorithm)了。ICaches的replacemnet algorithm有兩種,一種是Random模式另一種Round-Robin模式,我們可以通過CP15協處理器中寄存器1的RR bit對其進行指定(0 = Random replacement 1 = Round robin replacement),如果有需要你還可以進行指令鎖定(INSTRUCTION CACHE LOCKDOWN)。
關于替換法則和指令鎖定我就不做詳細的講解,感興趣的朋友可以找相關的資料進行了解。
接下來我們談數據緩存(DCaches)和寫緩存(write buffer)
DCaches使用的是虛擬地址,它的大小是16KB,它被分成512行(entry),每行8個字(8 words,32Bits)。每行有兩個修改標志位(dirty bits),第一個標志位標識前4個字,第二個標志位標識后4個字,同時每行中還有一個TAG 地址(標簽地址)和一個valid bit。
與ICaches一樣,系統上電或重起(Reset)的時候,DCaches功能是被關閉的,我們必須往Ccr bit置1去開啟它,Ccr bit在CP15協處理器中控制寄存器1的第2位(關閉DCaches功能則是往該位置0)。與ICaches不同,DCaches功能是必須在MMU開啟之后才能被使用的。
我們現在討論的都是DCaches,你可能會問那Write Buffer呢?他和DCaches區別是什么呢? 其實DCaches和Write Buffer兩者間的操作有著非常緊密的聯系,很抱歉,到目前為止我無法說出他們之間有什么根本上的區別(-_-!!!),但我能告訴你什么時候使用的是DCaches,什么時候使用的是Write Buffer.系統可以通過Ccr bit對Dcaches的功能進行開啟與關閉的設定,但是在s3c2410中卻沒有確定的某個bit可以來開啟或關閉Write Buffer…你可能有點懵…我們還是來看一張表吧,這張表說明了DCaches,Write Buffer和CCr,Ctt (descriptor中的C bit),Btt(descriptor中的B bit)之間的關系,其中“Ctt and Ccr”一項里面的值是Ctt與Ccr進行邏輯與之后的值(Ctt&&Ccr).
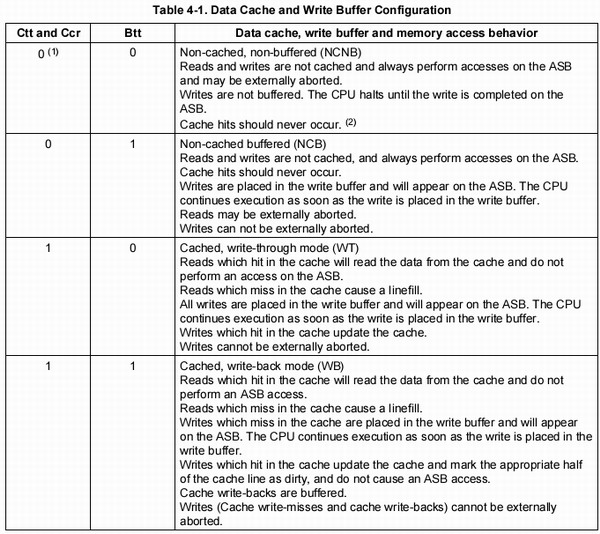
從上面的表格中我們可以清楚的知道系統什么時候使用的是DCaches,什么時候使用的是Write Buffer,我們也可以看到DCaches的寫回方式是怎么決定的(write-back or write-througth)。
在這里我要對Ctt and Ccr=0進行說明,能夠使Ctt and Ccr=0的共有三種情況,分別是
Ctt =0, Ccr=0
Ctt =1, Ccr=0
Ctt =0, Ccr=1
我們分別對其進行說明。
情況1(Ctt =0, Ccr=0):這種情況下CPU的DCaches功能是關閉的(Ccr=0),所以CPU存取數據的時候不會從DCaches里進行數據地查詢,CPU直接去內存存取數據。
情況2(Ctt =1, Ccr=0):與情況1相同。
情況3(Ctt =0, Ccr=1):這種情況下DCaches功能是開啟的,CPU讀取數據的時候會先從DCaches里進行數據地查詢,若DCaches中沒有合適的數據,則CPU會去內存進行讀取,但此時由于Ctt =0(Ctt 是descriptor中的C bit,該bit決定該descriptor所描述的內存區域是否可以被Cache),所以CPU不會把讀取到的數據Cache到DCaches(不發生linefill).
到此為止我們用兩句話總結一下DCaches與Write Buffer的開啟和使用:
1.DCaches與Write Buffer的開啟由Ccr決定。
2.DCaches與Write Buffer的使用規則由Ctt和Btt決定。
DCaches與ICaches有一個最大的不同,ICaches存放的是指令,DCaches存放的是數據。程序在運行期間指令的內容是不會改變的,所以ICaches中指令所對應的內存空間中的內容不需要更新。但是數據是隨著程序的運行而改變的,所以DCaches中數據必須被及時的更新到內存(這也是為什么ICaches沒有寫回操作而DCaches提供了寫回操作的原因)。提到寫回操作,就不得不提到PA TAG 地址(物理標簽地址)這個固件,它也是整個Caches模塊的重要組成部分。
簡單說PA TAG 地址(物理標簽地址)的功能是指明了寫回操作必須把DCaches中待寫回內容寫到物理內存的哪個位置。不知道你還記不記得,DCaches中每個entry中都有一個PA TAG 地址(物理標簽地址),當一個linefill發生時,被Cache的內容被寫進了DCaches,同時被Cache的物理地址則被寫入了PA TAG 地址(物理標簽地址)。除了TAG 地址(標簽地址),還有兩個稱為dirty bit(修改標志位)的位出現在DCaches的每一個entry中,它們指明了當前entry中的數據是否已經發生了改變(發生改變簡稱為變“臟”,所以叫dirty bit,老外取名稱可真有意思 -_-!!!)。如果某個entry中的dirty bit置位了,說明該entry已經變臟,于是一個寫回操作將被執行,寫回操作的目的地址則是由PA TAG 地址(物理標簽地址)索引到的物理地址。
關于Caches,Write Buffer更詳細的內容請大家閱讀s3c2410的操作手冊:]

評論