Linux 網(wǎng)絡(luò)文件系統(tǒng)的數(shù)據(jù)備份及恢復(fù)機(jī)制實(shí)現(xiàn)

為了保證引入多版本特性后文件系統(tǒng)仍具有較好的性能,以及保證較高的空間利用率,我們開發(fā)了一種高效的惰性版本生成算法。主要思想是:生成版本時(shí)不進(jìn)行文件的復(fù)制,僅復(fù)制目錄結(jié)構(gòu),在新版本生成后到下一版本生成前,如果有文件需要修改,則第一次修改時(shí)對(duì)該文件進(jìn)行復(fù)制,從而保證該文件狀態(tài)與對(duì)應(yīng)的版本保持一致。
在一般情況下,目錄結(jié)構(gòu)的數(shù)據(jù)量遠(yuǎn)遠(yuǎn)小于文件的數(shù)據(jù)量,因而這種方法可以大大降低版本生成時(shí)需要復(fù)制的數(shù)據(jù)量,因而具有較高的性能。同時(shí),這種把單個(gè)文件版本生成的實(shí)際操作推后到非做不可的時(shí)候,并且任意文件在兩次版本之間最多生成一次版本,因此這種惰性策略可以使需要實(shí)際生成版本的文件數(shù)量達(dá)到最少,同時(shí)還可以把多個(gè)文件版本生成操作分散到具體的文件操作中,從而避免了集中的一次性版本生成方法可能造成的服務(wù)暫時(shí)停頓的問題。
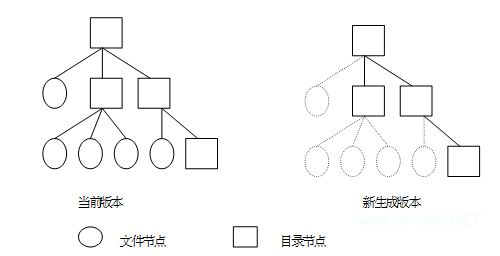
版本生成后的結(jié)構(gòu)如圖 2 所示。
圖 2 多版本生成示意圖
具體算法包括兩個(gè)部分,即版本生成算法和文件第一次修改處理算法,版本生成算法主要完成版本生成工作,主要過程如下:
找到需要形成版本的最高層目錄作為原目錄;
利用文件系統(tǒng)提供的函數(shù),生成新的目錄節(jié)點(diǎn),稱為新目錄;
把原目錄中的結(jié)構(gòu)復(fù)制到新目錄;
在原目錄中找到所有的子目錄,重復(fù) 2、3 步;
把新的子目錄對(duì)應(yīng)的 inode 號(hào)替換上一層目錄中的老 inode 號(hào);
重復(fù)上述過程,及到目錄樹中的所有目錄得到復(fù)制為止。
在上述策略中,新版本并沒有復(fù)制所有的文件,只是在復(fù)制的目錄結(jié)構(gòu)中記錄下了該文件的 inode 號(hào)(即復(fù)制了目錄的結(jié)構(gòu),而不是把文件都進(jìn)行復(fù)制,從而節(jié)省了存儲(chǔ)和計(jì)算資源),因此,當(dāng)有 NFS 請(qǐng)求需要對(duì)文件進(jìn)行版本生成后的第一次修改時(shí),需要復(fù)制該文件,生成新的版本。該實(shí)現(xiàn)過程參見如下流程圖:
圖 3 寫時(shí)復(fù)制算法示意圖
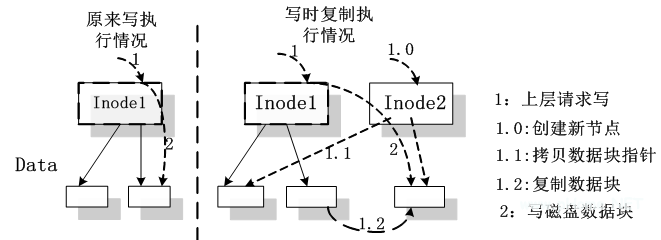
這種文件復(fù)制策略其實(shí)是一種惰性算法,也即我們常說的寫時(shí)復(fù)制的方法,這個(gè)方法在 Linux 操作系統(tǒng)的子進(jìn)程對(duì)父進(jìn)程資源的繼承中有所體現(xiàn)。這個(gè)策略一方面可以最大限度減少復(fù)制文件的數(shù)量,另一方面則可以避免瞬間過大的文件復(fù)制工作量,影響文件服務(wù)的性能。該算法的過程如下:當(dāng)文件操作為寫操作時(shí),判斷該文件是否版本生成后的第一次寫操作;若是則利用文件系統(tǒng)提供的底層函數(shù)生成一個(gè)新的文件,復(fù)制源文件的數(shù)據(jù)到新生成的文件,同時(shí)把該文件當(dāng)前版本的 inode 節(jié)點(diǎn)中的版本號(hào)置為當(dāng)前版本號(hào),這樣新文件就成為該文件的最新版本。
雖然我們采用的算法可以有較好的性能,存儲(chǔ)開銷也是最優(yōu),但是,每次版本生成肯定會(huì)造成服務(wù)性能的下降和空間的占用,而這些代價(jià)在一個(gè)比較安全可靠的環(huán)境中是可以適當(dāng)降低的,即當(dāng)系統(tǒng)比較安全的時(shí)候,可以選擇讓系統(tǒng)以更低的頻率進(jìn)行版本生成,相反,當(dāng)系統(tǒng)安全狀況比較糟糕的時(shí)候,可以通過提高版本生成頻率適當(dāng)降低服務(wù)性能來獲得更高的數(shù)據(jù)安全性能,當(dāng)系統(tǒng)處于緊急狀態(tài)時(shí),甚至可以要求立即進(jìn)行版本生成。
基于這些考慮,我們采用了自適應(yīng)的備份策略,災(zāi)情評(píng)估系統(tǒng)可以動(dòng)態(tài)評(píng)估系統(tǒng)的災(zāi)情程度,然后可以立即修改版本生成策略,以適應(yīng)當(dāng)時(shí)的安全要求。
NFS 數(shù)據(jù)恢復(fù)技術(shù)
企業(yè)應(yīng)用 NFS 的一個(gè)重要目標(biāo)就是要保證系統(tǒng)的高可用性,即使在出現(xiàn)嚴(yán)重災(zāi)難、故障、攻擊等情況下能具有較好的生存能力。因此,當(dāng)一個(gè)系統(tǒng)出現(xiàn)故障時(shí),如何快速地恢復(fù)系統(tǒng),迅速投入到服務(wù)備份中去是相當(dāng)重要的,所以,對(duì)于文件系統(tǒng)數(shù)據(jù)的恢復(fù)而言,也需要專門的考慮和設(shè)計(jì)。
本方案被配置成多個(gè)站點(diǎn)互為備份的情況,即平時(shí)只有一個(gè)主站點(diǎn)在服務(wù),其他站點(diǎn)處于同步備份狀態(tài),當(dāng)某個(gè)站點(diǎn)出現(xiàn)故障或?yàn)?zāi)難時(shí),或者是被非法入侵者攻破時(shí),系統(tǒng)可以立即分配新的主站點(diǎn)把被破壞的站點(diǎn)替換下來,進(jìn)入恢復(fù)狀態(tài),其他正常的站點(diǎn)仍可提供正常的服務(wù)。
當(dāng)然,也存在所有站點(diǎn)均出現(xiàn)故障的情況,但是由于我們采用了多種措施,如動(dòng)態(tài)隨機(jī)遷移、災(zāi)情評(píng)估與響應(yīng)策略等,再配合傳統(tǒng)的防火墻、IDS 等安全系統(tǒng),可以極大限度地減少這種幾率。因此,我們的數(shù)據(jù)恢復(fù)問題主要考慮上述這種情形,即個(gè)別服務(wù)器出現(xiàn)故障退出服務(wù)而其他系統(tǒng)依然正常的情況。
首先,我們來分析一下系統(tǒng)退出后數(shù)據(jù)的情形,主要涉及到退出的服務(wù)器和正常的主服務(wù)器與備份服務(wù)器,如圖 4 所示:
圖 4 一個(gè)系統(tǒng)退出后數(shù)據(jù)狀態(tài)示意圖
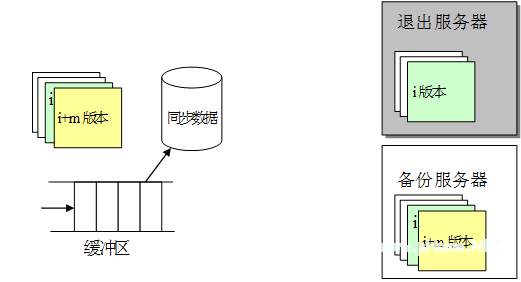
在上圖中,退出服務(wù)器最后生成的版本號(hào)為 i,系統(tǒng)退出后,一方面主文件服務(wù)器會(huì)察覺到同步數(shù)據(jù)無法從退出服務(wù)器返回結(jié)果,這樣的話它就會(huì)重發(fā)同步請(qǐng)求,經(jīng)過 3 次重發(fā)后,如果依然沒有返回信息,則認(rèn)為該服務(wù)器退出服務(wù),因此會(huì)把同步數(shù)據(jù)備份到磁盤文件中,并記錄下該服務(wù)器在同步數(shù)據(jù)文件中的起始位置,這當(dāng)由多個(gè)文件服務(wù)器退出時(shí)可以分別識(shí)別出來。由于退出系統(tǒng)無法繼續(xù)保持同步,因此其狀態(tài)會(huì)與工作的文件服務(wù)器不一致,具體表現(xiàn)在以下幾個(gè)方面:
當(dāng)退出時(shí)間很短時(shí),數(shù)據(jù)不一致僅存在于緩沖區(qū)中,這時(shí)如果退出服務(wù)器能立即重新投入使用,則不需要進(jìn)行額外的數(shù)據(jù)恢復(fù),數(shù)據(jù)同步可以通過主服務(wù)器同步請(qǐng)求的重試來達(dá)到。
當(dāng)主服務(wù)器確認(rèn)退出服務(wù)器退出后,會(huì)把未同步的數(shù)據(jù)寫入特定的同步數(shù)據(jù)文件中,這時(shí)的不一致性包括了緩沖區(qū)中的數(shù)據(jù)和同步數(shù)據(jù)文件中的數(shù)據(jù),這時(shí)的數(shù)據(jù)恢復(fù)需要做兩方面的工作:
把同步數(shù)據(jù)文件中的正確數(shù)據(jù)一次性發(fā)送給退出服務(wù)器,退出服務(wù)器把它寫入本地的同步數(shù)據(jù)文件;
建立本地的緩沖區(qū),建立起同步機(jī)制,接收同步數(shù)據(jù),同時(shí)啟動(dòng)數(shù)據(jù)同步進(jìn)程,先同步數(shù)據(jù)文件中的數(shù)據(jù),當(dāng)緩沖區(qū)數(shù)據(jù)因沒有處理而達(dá)到一定程度時(shí),會(huì)自動(dòng)把部分?jǐn)?shù)據(jù)追加到同步數(shù)據(jù)文件的后面,這時(shí),退出服務(wù)器已經(jīng)恢復(fù)了正常工作,實(shí)際上也不需要過多的數(shù)據(jù)恢復(fù)工作。








評(píng)論