對(duì)比Ruby和Python的垃圾回收
 加入技術(shù)交流群
加入技術(shù)交流群

掃碼加入
和技術(shù)大咖面對(duì)面交流
海量資料庫(kù)查詢(xún)

上面三個(gè)”M”標(biāo)記的對(duì)象為活躍對(duì)象,依然被我們的程序使用。在Ruby解釋器內(nèi)部,通常使用”free bitmap”的數(shù)據(jù)結(jié)構(gòu)來(lái)保存一個(gè)對(duì)象是否被標(biāo)記:
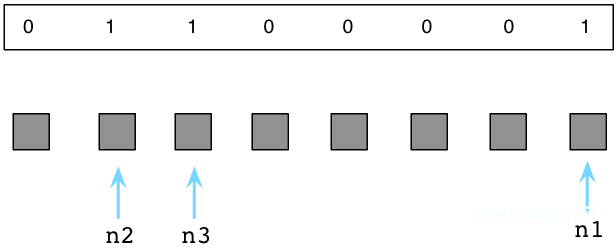
Ruby將”free bitmap”保存在一個(gè)獨(dú)立的內(nèi)存區(qū)域,以便可以更好的利用Unix的”copy-on-write”特性。更詳細(xì)的信息,請(qǐng)參考我的另一篇文章《為什么Ruby2.0的垃圾回收器讓我們?nèi)绱伺d奮》。
如果活躍對(duì)象被標(biāo)記了,那么其余的便是垃圾對(duì)象,意味著它們不再會(huì)被代碼使用。在下圖中,我使用白色的方塊表示垃圾對(duì)象:
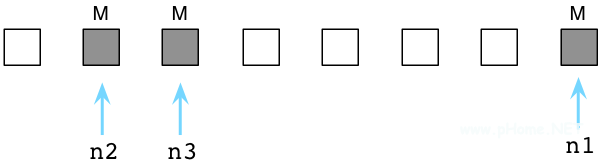
接下來(lái),Ruby將清理沒(méi)有使用的,垃圾對(duì)象,將它們鏈入空閑對(duì)象鏈表(free list):
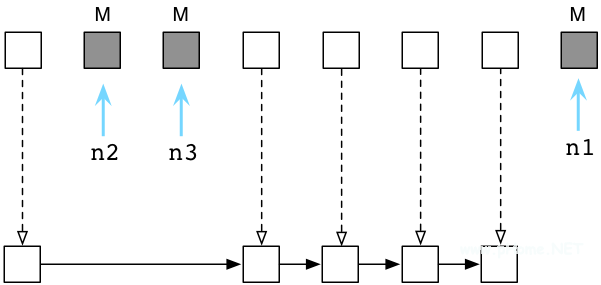
在解釋器內(nèi)部,這個(gè)過(guò)程非常迅速,Ruby并不會(huì)真正的將對(duì)象從一個(gè)地方拷貝到另一個(gè)地方。相反的,Ruby會(huì)將垃圾對(duì)象組成一個(gè)新的鏈表,并且鏈入空閑對(duì)象鏈表(free list)。
現(xiàn)在,當(dāng)我們要?jiǎng)?chuàng)建一個(gè)新的Ruby對(duì)象的時(shí)候,Ruby將為我們返回收集的垃圾對(duì)象。在Ruby中,對(duì)象是可以重生的,享受著多次的生命!
標(biāo)記回收算法 vs. 引用計(jì)數(shù)算法
咋一看,Python的垃圾回收算法對(duì)于Ruby來(lái)說(shuō)是相當(dāng)讓人感到驚訝的:既然可以生活在一個(gè)整潔干凈的房間,為什么要生活在一個(gè)臟亂的房間呢?為什么Ruby周期性的強(qiáng)制停止程序的運(yùn)行去清理垃圾,而不使用Python的算法呢?
然而,引用計(jì)數(shù)實(shí)現(xiàn)起來(lái)不會(huì)像它看起來(lái)那樣簡(jiǎn)單。這里有一些許多語(yǔ)言不愿像Python一樣使用引用計(jì)數(shù)算法的原因:
首先,實(shí)現(xiàn)起來(lái)很困難。Python必須為每一個(gè)對(duì)象留有一定的空間來(lái)保存引用計(jì)數(shù)。這會(huì)導(dǎo)致一些細(xì)微的內(nèi)存開(kāi)銷(xiāo)。但更遭的是,一個(gè)簡(jiǎn)答的操作例如改變一個(gè)變量或引用將導(dǎo)致復(fù)雜的操作,由于Python需要增加一個(gè)對(duì)象的計(jì)數(shù),減少另一個(gè)對(duì)象的計(jì)數(shù),有可能釋放一個(gè)對(duì)象。
其次,它會(huì)減慢速度。盡管Python在程序運(yùn)行過(guò)程中垃圾回收的過(guò)程非常順暢(當(dāng)你把臟盤(pán)子放到水槽后,它立馬清洗干凈),但是運(yùn)行的并不十分迅速。Python總是在更新引用計(jì)數(shù)。并且當(dāng)你停止使用一個(gè)巨大的數(shù)據(jù)結(jié)構(gòu)時(shí),例如一個(gè)包含了大量元素的序列,Python必須一次釋放許多對(duì)象。減少引用計(jì)數(shù)可能是一個(gè)復(fù)雜的,遞歸的過(guò)程。
最后,它并不總是工作的很好。在我演講的下一部分,也就是下一篇帖子中能看到,引用計(jì)數(shù)不能處理循環(huán)引用數(shù)據(jù)結(jié)構(gòu),它包含循環(huán)引用。
下一次…
下周我將發(fā)布演講的其他部分。我將討論P(yáng)ython怎樣處理循環(huán)引用數(shù)據(jù)結(jié)構(gòu),以及在即將到來(lái)的Ruby2.1中,垃圾回收器是怎樣工作的。


評(píng)論