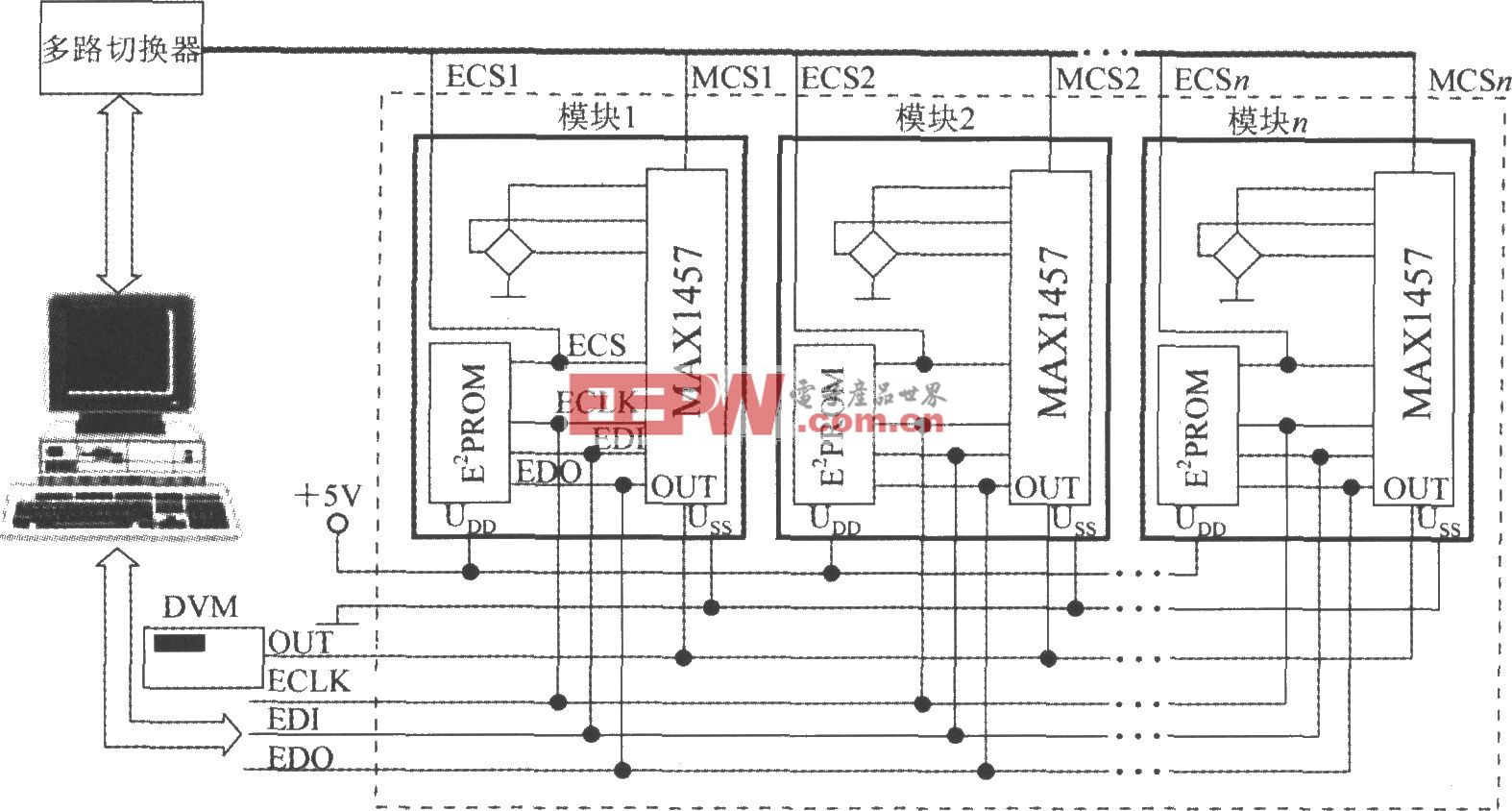
話說STM32F4系列的總線矩陣與訪問調度

本文引用地址:http://www.104case.com/article/201609/296596.htm

可能不少人見過STM32F4系列的內部系統架構框圖。大致如下圖,該圖很重要,不可視而不見。
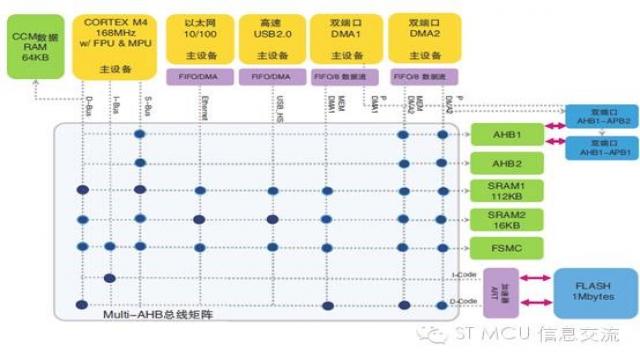
圖中縱橫交錯的就是多層AHB總線矩陣,負責把上方黃色主設備跟右邊綠色從設備互聯起來。所謂AHB主設備是指CPU或DMA[通用DMA或專用DMA],由它們啟動總線訪問,即讀寫操作。那些響應主設備讀寫訪問的設備就是AHB從設備,比如存儲器、各類外設等。
因為總線矩陣的存在,使得多個主設備可以并行訪問不同的從設備,增強了數據傳輸能力,提升了訪問效率,同時也改善了功耗性能。
不過,雖然總線矩陣使得多個主設備可以并行訪問不同的從設備,但在每個預定的時間內,只有一個主設備擁有總線控制權。如果有多個主設備同時出現總線請求時就得進行仲裁。所以總線矩陣里還有個AHB總線仲裁器,它保證每個時刻只有一個主設備通過總線矩陣對從設備進行訪問。(注1)
為了確保每個主設備訪問從設備的延遲盡量短,在總線矩陣里實行循環調度優先級方案:
• 循環調度仲裁策略使總線帶寬合理分配。
• 限定最大延時。
• 循環調度以1 次傳輸為單位。
當多個AHB 主設備試圖同時訪問同一個AHB從設備時,總線矩陣仲裁器介入以解決訪問沖突。在下面的例子中CPU 和DMA1 均試圖訪問SRAM1 以讀取數據。
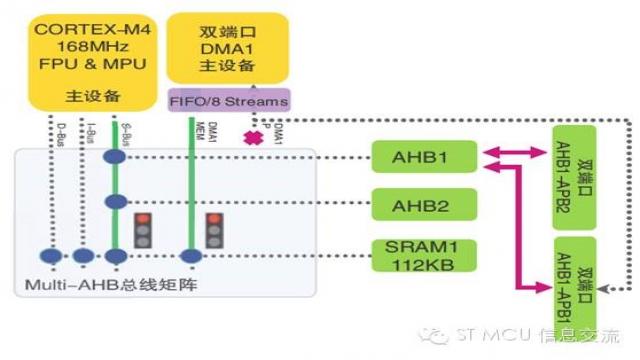
如上述示例總線訪問請求同時發生的情況下,就需要總線矩陣仲裁。為了解決這種問題,需要應用循環調度策略:如果本次最后贏得總線控制權的主設備是CPU,則在下一次訪問中DMA1將贏得總線控制權并首先訪問SRAM1。CPU 隨后方可有權訪問SRAM1。
這就表明,一個主設備的傳輸延時取決于其它等待請求訪問AHB 從設備的主設備數量。下面的例子是五個主設備試圖同時訪問SRAM1的情形:
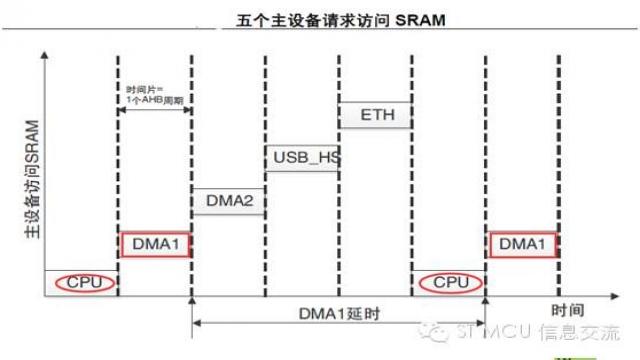
DMA1再次獲得總線矩陣訪問權并訪問SRAM1 的延時等于其它等待請求的所有主設備的執行時間之和。
我們再來看看進行總線矩陣仲裁可能導致的DMA傳輸延時最差情況。
主設備DMA端口進行一次數據傳輸會遭遇的延時取決于其它主設備的傳輸類型和長度。比如,我們結合上面的DMA1 & CPU 的例子,它們并行訪問SRAM。 DMA傳輸延時將隨著CPU 數據傳輸事務長度而變化。如果總線訪問首先給予CPU 且不是執行單次數據加載/存儲,DMA 訪問SRAM 的等待時間可能從一個AHB 周期(單次數據加載/ 存儲時間)延長為N 個AHB 周期,這里N 為CPU 數據傳輸事務中數據的數量。
CPU 鎖定AHB 總線以保持其訪問總線的所有權,減少了多次加載/ 存儲操作過程中的延時以及進入中斷的延時。這提高了固件的響應能力,但是可能導致DMA 數據傳輸事務的延遲。
DMA1 與CPU 并行訪問SRAM 的延時取決于傳輸類型:
• 中斷(上下文保護)發起的CPU 傳輸:8 個AHB 周期;
• LDM/STM 指令發起的CPU 傳輸:14 個AHB 周期(注2)
---在多達14 個寄存器與存儲器之間進行傳輸;
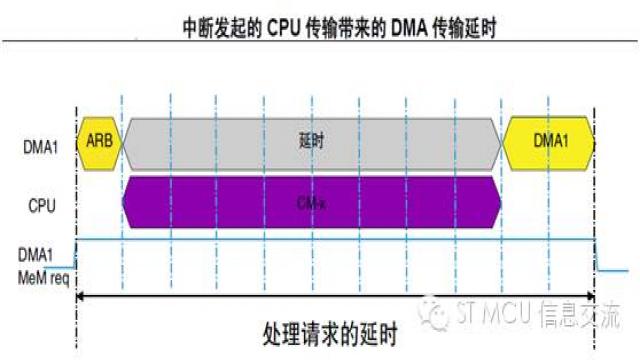
上圖詳細描述了一個因中斷進入而導致DMA多周期傳輸延遲的情形。DMA 存儲器端口被觸發,發出存儲器訪問請求。經過仲裁, AHB 總線未授權DMA1 存儲器端口訪問,而由CPU 來訪問總線。可以看到在服務DMA 請求之前有一段額外的延時。這段中斷發起的CPU 傳輸,耗時為8 個AHB 周期。
不難理解,當同時對一個從設備進行尋址且數據傳輸事務長度不是一個數據單元時,其他主設備(如DMA2,USB_HS, Ethernet…)也會碰到類似情形。所以,為了提高DMA 對總線矩陣的訪問性能,要盡量回避總線競爭。
以上內容主要取材于ST官方應用筆記文檔AN4031的一部分。該筆記里除了上述內容外,還對STM32F2/F4的DMA傳輸路徑、DMA傳輸時間的估算、DMA編程都有較為細致的介紹。我這里算是拋磚引玉,有興趣的話可以去www.stmcu.com.cn 的設計資源區搜索下載AN4031。
(注1)并非所有主設備訪問從設備都得經過總線矩陣,細心的人可能看到了有些主設備與從設備間有直通通道。細節詳見STM32芯片相關參考手冊。
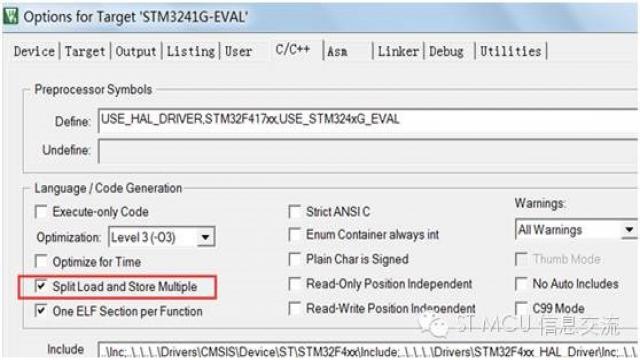
(注2) 通過配置編譯器,將加載/ 存儲多重指令分解為單個加載/ 存儲指令,可以降低由LDM/STM 發起的傳輸的延時。


評論