汽車牌照自動識別系統設計

2.2 特征提取本文引用地址:http://www.104case.com/article/194419.htm
特征提取的主要目的是從原始數據中抽取出用于區分不同類別的本質特征。由于不同的特征的適用性不同,故對不同效果的字符所提取的特征性能也不盡相同,因此,用單一的特征已經很難適應受多種條件影響的車牌照字符的識別。另外,由于不同特征的不同維之間所表示的意義也不太相同,且權重也可能相差很多,如果采用直接組合的方法,就會使權重較大的特征占主導地位,而忽略了權重較小的特征。要解決這種問題,可以采用特征向量歸一化法或者加權的辦法,將兩種特征通過加權的方法組合起來,從而達到組合使用兩種特征的目的。
2.3 分類器設計
分類器就是在特征空間中用某種方法將被識別對象歸為某一類別。其基本做法是在樣本訓練集的基礎上確定某個判決規則,以使按這種判決規則對被識別對象進行分類所造成的錯誤率最小或引起的損失最小。
采用神經網絡作為分類器時,需要有一定的訓練樣本,而且樣本個數不能太少,但是,本文的實驗環境中的車牌上,漢字、英文樣本較少,甚至某些漢字英文僅有一個或者幾個樣本,因而無法保證神經網絡的訓練程度。因此,本文采用模板匹配法。模板匹配法實際上就是采用多個標準樣本的距離分類器。通常可利用平均樣本法來計算樣本均值以將其作為每個類別的標準樣本,然后計算待識別樣本與標準樣本間的距離,最后選擇距離最小的標準樣本作為待識別的樣本類別。
通常采用的距離準則如下;
(1)Minkowsky距離
該距離是若干種距離的通式表示:

(2)“City block”距離
即街區距離,它是對Manhattan距離的修正,同時加上了權重。即:
(3)Euclidean距離
即歐氏距離,是Minkowsky距離在λ=2時的特例,其優點是各點連續可微:
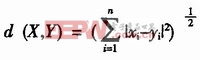
(4)Mahalanobis距離
即馬氏距離,它注意到樣本的統計特性,而排除了樣本間的相關性影響。它可表示為:
本設計選用了歐式距離。因為歐式距離可以只計算
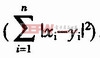
,這樣可以降低計算時間。
3 結束語
本文提到的車牌照識別方法具有很好的識別效果,并可針對出現的漏識和識別錯誤等現象做出改進,預處理時還可對圖像亮度進行分析,針對過亮或者過暗的圖像采取不同的二值化策略;也可以根據字符識別的結果采用回溯方法來驗證車牌定位和字符切分的準確性;字符識別部分可增加字符模版的訓練樣本數量,而采用神經網絡作為分類器均可以提高字符識別的準確率。







評論