NetFlow流量采集與聚合的研究實現

NetFlow的原始數據數據量非常龐大,保存每一條流數據的原始記錄將會使對數據進行查詢分析時產生效率低下的問題,在絕大部分應用中也沒有必要把數據粒度設計得如此之小。所謂流量聚合,是指對符合NetFlow數據格式的原始流記錄根據一定條件進行流量合并,實現多條流合并為一條的過程,以實現原始流的壓縮整理。
2.3.1 聚合策略
流量聚合有三個關鍵要素:聚合條件(F)、時間粒度(T)和聚合項(C)。滿足相同聚合條件和時間粒度的流進行流量疊加,并保留聚合項。三元組聚合策略:F,T,c>,其中:本文引用地址:http://www.104case.com/article/188834.htm

按照實際流量分析的需要,從F,T,C中各取出一個值組成一個聚合策略。對于T的粒度要根據實際監控的時間長短和監測精度來設置,一般來說T=3 min適合于當天實時流量的監測;T=30 min用于一周流量的分析;T=3 h用于一月內流量的分析。
2.3.2 聚合的實現
對于一個新采集的原始流,必須能根據其所攜帶的聚合條件信息快速匹配是否已存在與其相同聚合條件的聚合流,若有則做流量疊加,若沒有則創建一條新的聚合流。Hash表具有從Key快速映射到Value的特點,這種特點對于實時性較高的聚合非常有意義。圖3為流量聚合的}Iash表設計。
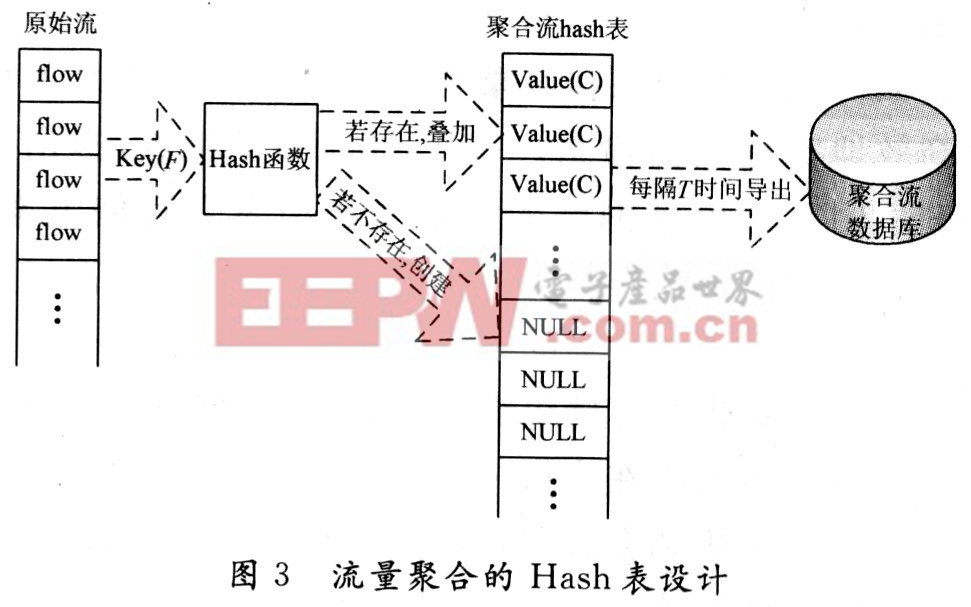
在圖3中聚合條件(F)作為Key,聚合項(C)作為Hash函數的映射值,時間粒度(T)作為Hash表導出到數據庫的時間。這樣可以滿足實時流量監測的需要,同時也壓縮數據減少存儲空間,提高數據的查詢效率。
3 實際NetFlow流采集與流量監測
在本系統設計的數據采集器的支持下,系統數據庫為前端分析提供了充足且多樣化的數據準備,前端程序只需通過簡單的查詢語句即可得到所需的數據集,簡化了查詢的工作量。利用該系統采集NetFlow數據包50 000個,時間持續約7 h,時間粒度為3 min,主要檢驗丟包情況,以及聚合后壓縮效率。這次采集無丟包發生,表1為該系統采集的數據結果。

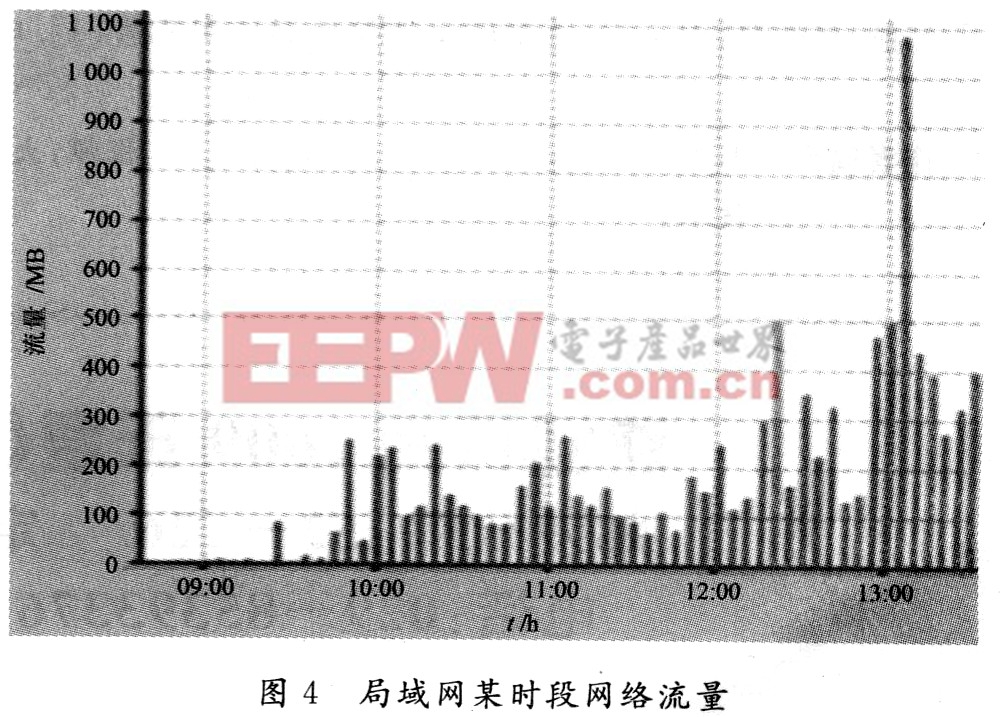
圖4是系統由所采集的數據生成的該時段的流量監測圖。
4 結 語
NetFlow數據流的海量特征使得服務器程序的效率至關重要,因此基于NetFlow的流量監測的主要任務是如何根據應用保存最重要的網絡流特征以及如何更高效地實現數據檢索。基于NetFlow特點,提出了一套適用于大流量網絡的流量采集與聚合存儲方案。流量采集通過多線程和緩沖區機制實現,有效提高了流量采集的可靠性。采集的原始流經聚合,并通過合理的分級存儲策略進行存儲組織,為前端的數據分析提供了全面支持。本系統在實際應用中取得了良好效果。下一步還將對采集和多級聚合存儲方案進行改進,以豐富系統對網絡流量統計分析功能,并力爭為異常流量分析提供較為完善的數據支持。





評論