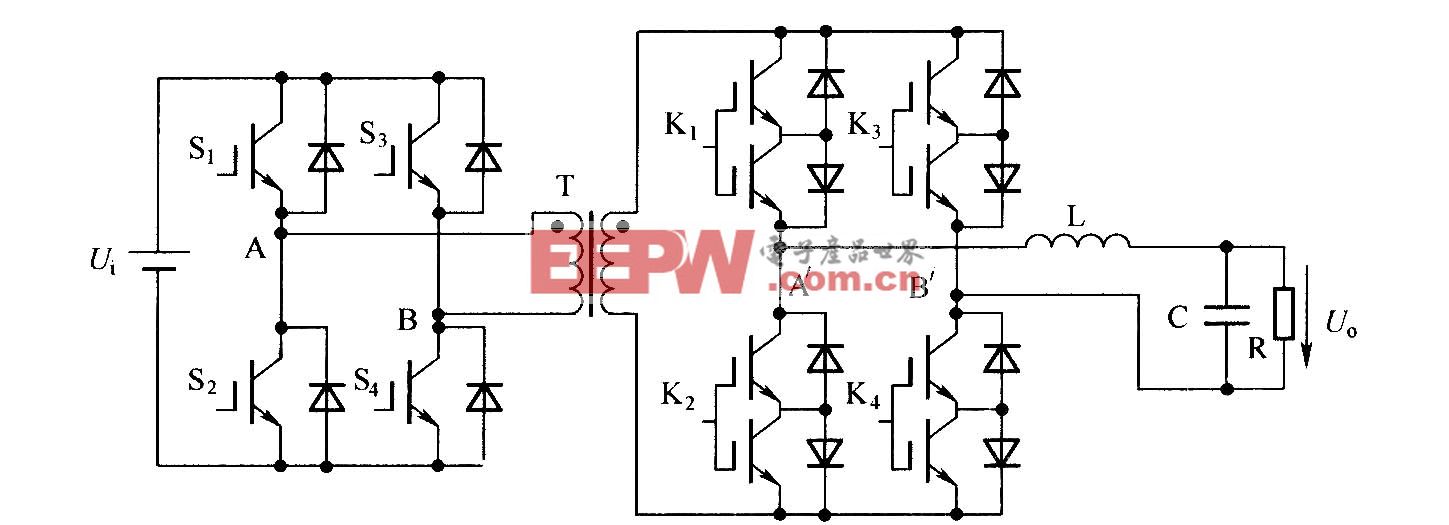
HPI接13的視頻數據傳輸系統設計

其中vm_flags字段設置了VM_RESERVED,表示該數據緩沖區一直常駐內存,在內存不足時,不會被交換出去。內核和進程同時對數據緩沖區讀寫,為了保證數據的一致性,對該區域的訪問不應該經過CPU內部的緩沖區,所以用pgprot_noncached設置非緩沖標志。
mmap系統調用返回一個進程虛擬地址,該地址就是vma->vm_start字段,進程對該虛擬地址的訪問,最終變為對物理地址CACHE_PHY的訪問。
2.3 數據緩沖管理
緩沖管理的主要任務是,當ARM接收到新的一幀時,為其分配相應的緩存,并將在物理地址重映射到進程虛擬地址。當應用程序處理該幀時,緩沖管理負責內存區域的回收。
當Linux內核啟動時,可以傳人參數mem=PHY_LEN,指定存儲空間的大小。在本例中,內核啟動時為HPI驅動預留8 MB的高端物理內存。在本例中,借助Linux中對普通外設I/O內存(PCI卡內存等)管理的思想,用高度為2的樹表示一塊連續的區域。該數據結構的優點在于,資源分配簡單,把離散的小內存合并為一塊連續的大緩沖區的算法復雜度為O(1)。具體實現請參閱內核源碼中resource結構相關部分。
重映射新一幀視頻數據到進程虛擬地址是緩沖管理的另一任務。因為前一幀數據物理地址已經映射到進程虛擬地址,需要先將前幀物理地址與進程虛擬地址的映射關系去掉,然后重映射當前幀數據到進程虛擬地址。去掉物理地址與進程虛擬地址的映射關系由內核函數zap_page_range完成,調用該函數后,如果進程再訪問該虛擬地址,內核會產生缺頁中斷。這時再用remap_page_range建立當前幀數據物理地址與進程虛擬地址間的映射關系,進程就可以通過同一虛擬地址訪問當前幀的數據了。該方法的意義在于,進程不用頻繁調用mmap建立物理地址與虛擬地址的映射,只用調用一次,當有新數據到達時,驅動自動將新幀數據映射到先前的進程虛擬地址,提高了進程處理視頻數據的效率。實現代碼如下:本文引用地址:http://www.104case.com/article/166938.htm

結 語
在當前視頻處理平臺上,視頻處理、視頻傳輸、復雜任務管理等工作一般都是由一塊DSP處理器單獨完成,結合其他嵌入式微處理器協同工作的技術方案剛剛起步。經測試,在基于本文提出的高速通信方法設計的視頻處理平臺上,TMS320DM642與AT9lRM9200間的通信速率可以達到50 Mbps,帶寬足夠用來傳輸MPEG等壓縮視頻數據。如果用HPl32模式,速度還會大幅度提高。同時,因為Linux系統的實時性不是很強,如果采用其他實時性強的操作系統,如Vxworks等,系統性能還會有大的提高。



評論