基于內容的音頻檢索系統的前端抗噪技術

引言
本文引用地址:http://www.104case.com/article/166556.htm基于內容的音頻檢索指通過音頻特征分析,對不同音頻數據賦以不同語義,使具有相同語義的音頻在聽覺上保持相似。該技術在許多領域都有極大應用價值。在檢索系統中一種常見情形是將安靜環境下訓練的模型應用于實際有背景噪聲的環境。尤其在哼唱輸入的情況下,噪聲不可避免,因此噪聲背景環境中的音頻識別技術一直備受關注。本文給出一個將音頻增強和音頻檢索系統相連接的抗噪聲音頻檢索系統,重點分析基于內容的音頻檢索系統的前端抗噪技術。
2 系統平臺的建立
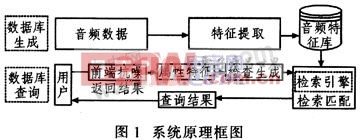
基于內容的音頻檢索系統運用多媒體信息處理技術,結合人感知心理研究和模式識別技術實現音頻檢索,包括音頻分割、特征提取和索引檢索等關鍵步驟。在提交哼唱式音頻過程中不可避免地會受到來自周圍環境和傳輸媒介引入的噪聲、設備內部電噪聲的干擾。這些干擾將使檢索系統的性能惡化。因此,必須對帶噪音頻進行抗噪處理。音頻檢索系統首先是建立數據庫,對音頻數據進行特征提取。音頻檢索主要采用哼唱查詢方式,用戶通過查詢界面哼入查詢信息,然后提交查詢。在進行屬性特征提取前通過前端抗噪模塊增強哼唱語音。接著系統對哼唱音頻提取特征,然后檢索引擎對特征矢量進行匹配,按相關性排序后通過查詢接口返回給用戶。圖1為抗噪聲檢索系統原理框圖。
3 音頻抗噪技術分析
3.1 語音增強算法分類
系統前端輸入信號通常是哼唱輸入,語音頻段可以采用語音增強技術。語音增強是指為了提高受噪聲污染的語音信號的質量而對含噪語音所做的處理,主要用于從帶噪語音信號中提取純凈的原始音頻或原始語音參數。根據不同的標準,語音增強算法有多種分類方法。
從信號輸入的通道數分為單通道的語音增強算法與多通道的語音增強算法。單通道語音系統下語音與噪聲同時存在于一個通道中,語音信息與噪聲信息必須從同一個信號中得出。常用方法包括譜減法、信號統計模型方法、聽覺掩蔽算法、維納濾波方法、信號子空間算法等。多通道語音增強算法則采用麥克風陣列獲取信號數據,它可充分利用陣列信號的信號源方向、說話人位置等空間特性,結合語音信號與噪聲的特征實現語音增強。代表性的算法有自適應波束形成算法、結合波束形成與后濾波算法及各種基于信號子空間、統計模型算法等。
另一種分類方法是根據對語音信號處理方式的不同,將語音增強算法分為時域語音增強算法和變換域語音增強算法兩大類。時域語音增強是在時間域直接處理帶噪語音來恢復純凈語音,利用語音信號在時域中的短時平穩特性、相關特性等來研究具有針對性的噪聲消除技術,其代表性算法有最大后驗概率估計法、卡爾曼濾波法、梳狀濾波器法、子空間的方法、自適應噪聲抵消算法、語音生成模型等。變換域語音增強需一個適當的變換將語音信號轉換到變換域中,然后針對變換域中的帶噪語音分量的特性設計算法恢復純凈語音分量,最后通過相應的反變換獲得純凈語音信號在時域中的估計。其常用變換有離散傅里葉變換、離散余弦變換及K-L變換和小波變換等,代表性算法有譜減法、維納濾波法、短時譜幅度的MMSE估計、自適應濾波法等、聽覺掩蔽效應增強算法,小波變換算法、基于頻域盲源分離的語音增強技術等。還有一些新方法,如神經網絡、分形理論等。




評論