一種基于SVM的數(shù)字儀表顯示值識別方法

若ai>0,稱相應的xi為支持向量(Support Vector)。更進一步,若OaiC,稱xi為邊緣(Margin)支持向量;若ai=C,稱xi為偏差(Bias)支持向量。非線性支持向量機的工作原理是通過非線性變換φ(x),將輸入空間變換到一個高維空間,在這個新空間中求取最優(yōu)線性分類面,并引入核函數(shù)(如RBF核函數(shù)
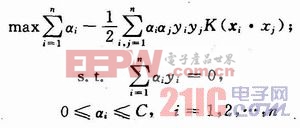
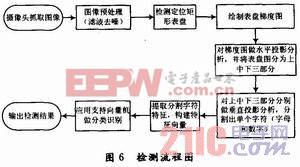
找出的支持向量充分描述了整個訓練數(shù)據(jù)集的特征,使得對SV集的線性分類等價于對整個數(shù)據(jù)集的分類,檢測流程圖如圖6。所示。本文引用地址:http://www.104case.com/article/166179.htm
1.5 實驗結果與分析
實驗中選取了3組典型的樣本,每組樣本數(shù)200個,在PC機上進行了試驗,結果如表1所示。每個樣本有6或5個數(shù)字,其中3或4個是表示小時和分鐘,2個表示秒鐘。
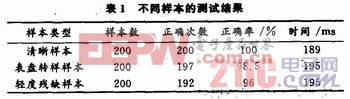
從表1可以看出,在二值化較好,數(shù)字清晰的情況下,識別率達到了100%,對有輕微點狀噪聲和輕微斷痕的樣本,識別率也很高,但對存在數(shù)字殘缺的樣本,識別率有所下降。就識別時間而言,整屏數(shù)字(6或5個數(shù)字)的識跗時間小于200 ms,明顯低于儀表數(shù)字的最快變化時間1 000 ms。
2 結語
主要研究了數(shù)字式儀表的自動判讀方法,為儀表盤上的儀表實現(xiàn)自動識別打下基礎。首先對采集到的數(shù)字式儀表進行預處理,主要包括圖像灰度化、二值化、噪聲消除等。參考現(xiàn)有的數(shù)字識別算法,本文主要采用垂直投影法來分割各個字符,然后對分割后的每個字符提取分塊統(tǒng)計特征。最后用SVM訓練樣本實現(xiàn)相應數(shù)字字符識別,最終判讀出數(shù)字儀表的讀數(shù)。該方法算法簡單,實時性高,可靠性好,是一種比較理想且具有一定應用價值的識別算法。




評論