基于主動隊列管理的擁塞控制機制研究

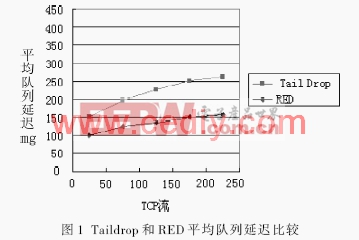
圖1所示是對兩種算法的仿真曲線圖。由結果可以得出:隨著流量的增加,兩種算法都產生了不同程度上的延遲,且在高負載的情況下,去尾算法由于全局同步而使隊列震蕩加劇[3-4]。本文引用地址:http://www.104case.com/article/163600.htm
2 設計方案
RED算法及很多的改進算法,都不能夠對不同Qos要求的服務提供有區別的服務,這樣就不能很好地保證高服務質量要求的服務。本文中,提出了一種可以實現區分服務的算法DS-RED(Different Serve RED),在緩存中設置一個動態門限來控制包的丟失率,使得緩存可以動態地分配給各個數據流,可以根據各個數據流的不同Qos要求,動態地調整網絡資源,從而提高網絡網絡資源的利用率。可以通過設置一個門限值,然后根據高低優先級包的丟失情況來動態調整這個門限值,使得不同的Qos要求的服務得到有區別的對待,并且高低優先級包丟棄達到一個均衡。使網絡資源得到更加充分的利用。
2.1 算法設計目標
(1)擁塞避免與擁塞控制。實驗表明要維持網絡中的高吞吐量和低延遲,就必須進行擁塞避免;作為擁塞避免失敗的補救措施,必須在路由器上實施擁塞控制,以避免網絡中擁塞崩潰的發生;
(2)實現各數據流區分服務。在緩存中設置一個動態門限來控制包的丟失率,使得緩存可以動態地分配給各個數據流,可以根據各個數據流的不同Qos要求,動態調整網絡資源,從而提高網絡資源的利用率,它可以通過設置一個門限值,然后根據高低優先級包的丟失情況來動態調整這個門限值,使得不同的Qos要求的服務得到有區別的對待,并且高低優先級包丟棄達到均衡。
2.2 算法思想
為高、低優先級數據流分別設置丟失計數器ch和cl,每個計數器指定一個丟失增量,例如為kh、kl。當ch每增加kh將會引起門限減少一定值;而cl每增加kl將會引起門限減少一定值。這樣如果太多高優先級數據包丟失,增大低優先級數據包丟棄概率的門限值就會減少,以減少低優先級數據包的緩存空間;反過來,如果太多低優先級數據包丟失,門限就會增加。使得高低優先級包丟棄達到一個均衡。使網絡資源得到更加充分地利用。
3 與RED算法的性能比較
為了比較RED和新算法的性能,進行網絡仿真,仿真使用的網絡拓撲結構如圖2所示。








評論