基于圖像識別的閱卷系統的設計與實現

(3)基于鏈碼方法的結構特征
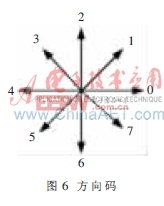
從曲線起點開始與其相連的像素點有8種可能的方向:k×45°(k=0,1,…,7),如圖6所示, 如果兩個像素點間的連線方向為k×45°,就用“k”作為這條連線的代碼,則一條曲線最終可近似地用下式表示:
An=a1a2…an,ai∈{0,1,2,…,7}, i=1,2,…,n
(4)孔洞特征
在二值圖像中,被目標像素1包圍的背景像素0(的集合)稱為孔洞(hole)。在字符的骨架線的鏈碼形成過程中,若搜索到的下一點就是該骨架線的搜索起始點,同時己形成的骨架鏈碼碼長超過了一定的閾值,則認為搜索到一個孔洞[5]。
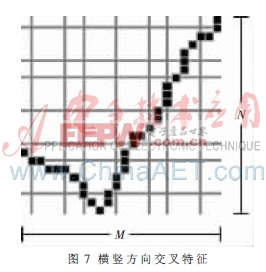
(5)橫豎方向交叉特征
橫向或縱向掃描字符,某一行或列的像素由白變黑的次數就是該行或列的橫或縱向交叉特征。本系統將橫豎兩個方向距離不等的7條線作用于字符,計算水平和垂直方向與字符的交叉數,如圖7所示。
2.2.2 符號模型庫建立
答題卡信息識別的訓練階段需要建立符號模型庫,以便對待識別手寫符號進行分類和識別。符號模型庫建立的好壞直接影響分類器的應用,從而影響手寫符號識別效果[5]。
由于手寫符號的多樣性,需要選擇某一類手寫符號中具有代表性的多個樣本來構造標準樣本,本系統采用手寫字符樣本特征向量的均值來描述類目標。設有n個符號類,每個符號類中有a個訓練樣本,每個樣本有b個符號特征,每個符號類中樣本的特征記為fkj,k為樣本特征序號,j為各個手寫符號的樣本序號,則第i個目標類特征的均值為P(i),即: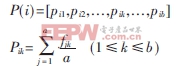
每次計算Pik時,k為大于等于1小于等于b的固定值。Pik為對于第i個目標類中a個樣本中各個樣本對應第k個特征值的均值。
2.2.3 手寫符號識別
對答題卡中矩形框信息識別包括兩個方面,一是識別矩形框中是否有字符,二是識別具體是哪種字符。其中識別是否書寫了字符比較簡單,只要比較增強對比度后的矩形框圖像與已知填有信息的矩形框的均方差大小,即可識別是否有字符,因為空白的矩形框和被書寫的矩形框均方差差別很大。下面主要介紹怎樣識別矩形框中的具體字符。
手寫符號識別就是在提取到符號的特征向量之后,依據一定的判別函數來判定出某一圖形點陣具體代表的是哪一個手寫符號。
判別函數可以先簡單地作如下定義:考慮有P1,P2,...,Pm個符號類別,假使每類有一個標準樣本,則共有m個標準樣本,分別表示為k1,k2,...,km。任意一符號特征向量X和第i個(i=1,2,...,m)標準樣本間的“相似度”為Ri。計算待識別的符號特征向量X與每類標準樣本之間的“相似度”[7],并將X分到與它“相似度”最大的類別,即對所有的j不等于i,若Di>Dj,則X就屬于Pi類符號。
系統采用基于最鄰近域分類器的模板匹配算法來對手寫符號進行識別。
首先定義字符特征向量,經過前面的特征提取分析,該特征向量為一個16維向量,X={x1,x2,..,x16},具體定義為:
x1:孔洞數;
x2:端點數;
x3~x9:7條水平線與字符的交叉次數;
x10~x16:7條豎直線與字符的交叉次數。
通過度量待識別字符和樣本庫中樣本字符的接近程度,確立最近分類的一個準則。在最鄰近分類中,經常使用的是相似度。如圖8所示,在提取了待識字符的特征向量并建立了字符庫后,將待識別字符和樣本庫中第i個樣本的特征向量之間求近似度R(X,G)。R(X,G)定義如下:

式中,xi為待識別符號特征向量的第i個分量,gik為樣本庫中第i個標準樣本的第k個分量,m為樣本類別數。分子為向量X,G之間的內積,分母分別為向量X、G的模。α是向量X,G在m維空間的夾角。顯然,當X、G兩個向量完全相同時,其夾角為0,R(X,G)=1,它們的距離D(X,G)=0,即相似度最大。求出最大Rr(X,G),若Rr(X,G)≥給定閾值,即可找到與待識別字符最接近的樣本類別,否則人工干預并修改樣本庫[7]。
3 實驗結果與分析
實驗采用CCD攝像頭采集答題卡圖像,經圖像預處理、若干特征提取、信息識別等過程,判定矩形框中有無字符、是什么字符,最后對答題卡信息分析和統計。實驗采用100份試卷作為樣本,對20份試卷進行測試,結果發現識別錯誤的手寫符號主要是“√”和“w”,原因在于這兩者在結構方面相似,而符號“○”的識別率達到100%。
本系統將圖像預處理、字符特征提取與圖像識別等技術應用于閱卷系統的開發,實現了閱卷自動化,加快了成績考核的速度,改善了教學管理環境。相比于傳統的基于光學標記閱讀機的閱卷系統,本系統利用圖像識別技術實現閱卷自動化,不需要特殊的答題卡,考生也可以隨意使用各種“√”、“w”、“○”等手寫符號進行答題,不必用指定的2B鉛筆填涂矩形塊,更符合人們的習慣。
參考文獻
[1] 王虎.基于圖像識別的標記閱讀機及選舉計票系統研究[D].合肥:安徽大學,2006.
[2] 張婷.基于圖像識別技術的光學標記閱讀機的研究與應用[D].合肥:安徽大學,2007.
[3] 吳元君,張婷,雷驚鵬.一種改進的OMR 技術在標準化考試中的應用[J].計算機教育,2007(13):250-272.
[4] 丁慧東.脫機手寫體漢字識別研究[D].長春:東北師范大學,2006.
[5] 龐東虎,金偉杰.英文字符特征提取系統[J].計算機仿真,2007,24(12):208-210.
[6] 楊玲,毛以芳,吳天愛.基于多特征多分類器的脫機手寫漢字識別研究[J].計算機與網絡,2008(01):217-217.
[7] 覃勝,劉曉明.基于圖像的OMR技術的實現[J].電子技術應用,2003,29(10):17-19.
[8] 翁功平.光標閱讀機OMR原理的設計與實現[J].工業控制計算機,2010,23(04):61-62.






評論